Building with Redpanda Connect: Bloblang and Claude plugin
A workshop on building and debugging real-world streaming pipelines
Using Docker Compose to prototype an end-to-end streaming application with Flink SQL, Redpanda, MySQL, Elastic and Kibana.









Stream based processing has risen in popularity in recent years, spurred on by event driven architectures, the need for faster analytics, and the availability of various technology stacks that make it all feasible. One popular component of such a stack is Apache Flink, a stream processing framework that boasts one of the most active open source communities today. Flink takes a stream-first approach -- everything is a stream, and a batch file is treated as a special case of a bounded stream. At Redpanda, we share the view that streaming is a superset of batch, and our goal is to make Redpanda the best persistence layer for stream processors.
Flink has several API layers that provide different levels of abstraction. At the highest level is Flink SQL, which allows non-programmers to easily build complex streaming pipelines in a familiar language. Flink SQL is ANSI compliant, and supports constructs such as joins, aggregations, windowing, and even user-defined functions. It can integrate with a number of data sources and sinks declaratively, via DDL statements. For example, to allow Flink SQL to read from a Kafka topic:
CREATE TABLE access_logs (
event_time TIMESTAMP(3) METADATA FROM 'timestamp',
host STRING,
ident STRING,
authuser STRING,
request STRING,
status SHORT,
bytes BIGINT
) WITH (
'connector' = 'kafka', -- using kafka connector
'topic' = ‘logs’, -- kafka topic
'scan.startup.mode' = 'earliest-offset', -- reading from the beginning
'properties.bootstrap.servers' = 'kafka:9094', -- kafka broker address
'format' = 'csv'
);Once the table is declared, reading and processing the stream coming from the topic is straightforward. For example:
SELECT count(1), status FROM access_logs GROUP BY status ;
SELECT count(1), status FROM access_logs GROUP BY status ;
Flink SQL does not ship with a specific connector for Redpanda. However, given Redpanda’s strong wire compatibility with the Kafka protocol, the standard Kafka connector works perfectly. As an example, we take an existing Flink SQL demo that shows an end-to-end streaming application. The demo shows Flink SQL reading a stream from a Kafka topic, which is then processed via streaming SQL. The results are written to Elastic, which are then presented as dashboards using Kibana. We replaced Kafka with Redpanda while keeping the rest of the application intact. TL;DR,
It just works.
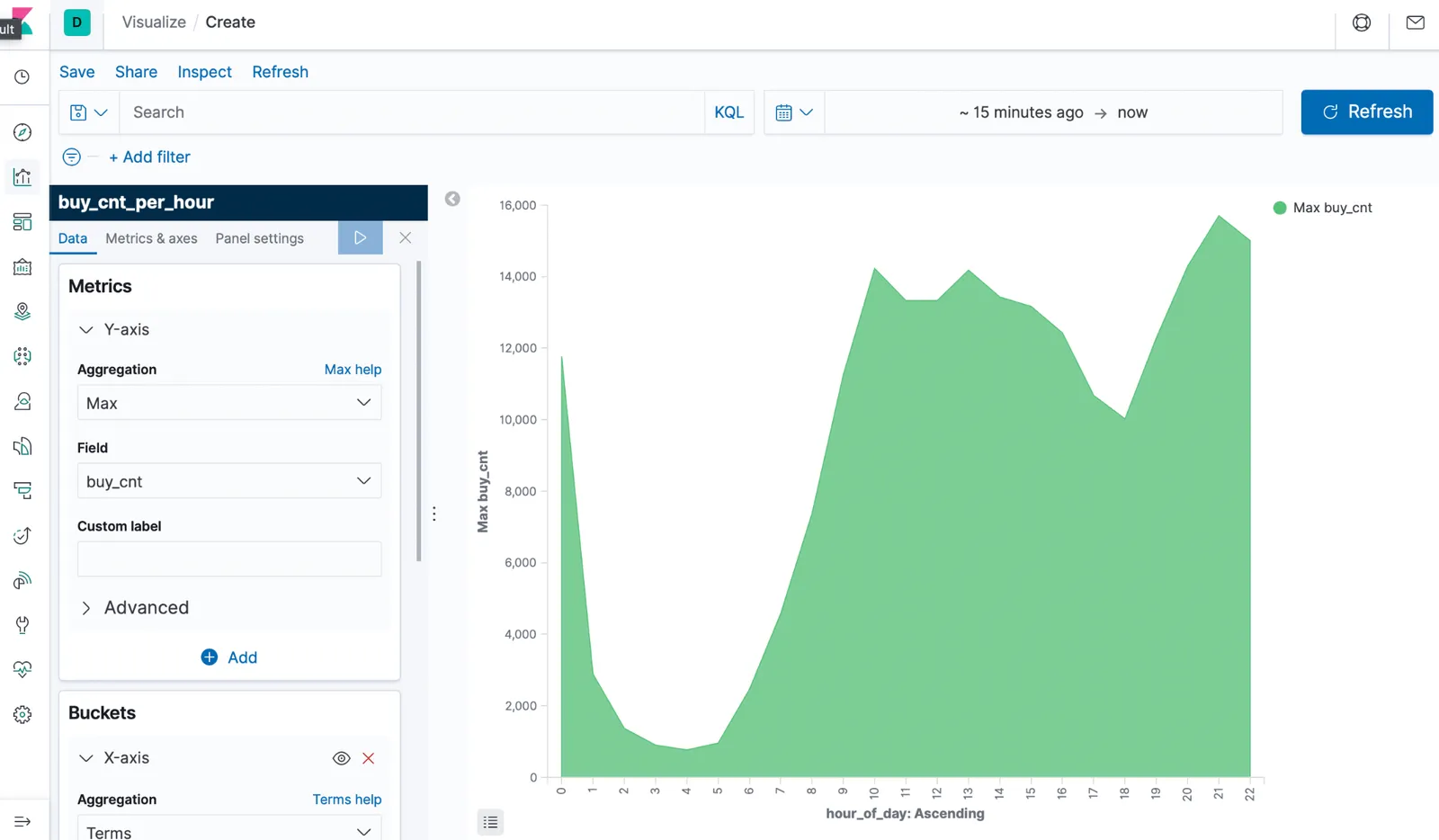
To see for yourself, go to the demo article at the Apache Flink project website. (Props to Flink PMC / Committer @JarkWu for putting together this excellent demo.) The demo requires Docker and Docker Compose to bring together the various components to run in your local environment.
You can follow the step-by-step instructions in the article, except for the initial step of grabbing the docker-compose.yml file. We had to modify the file to substitute Redpanda for Kafka, so the first step should be to enter the following from your command line to get our version of docker-compose.yml:
mkdir flink-sql-demo-redpanda; cd flink-sql-demo-redpanda;
wget https://raw.githubusercontent.com/patrickangeles/flink-sql-demo-redpanda/main/docker-compose.ymlThe rest of the demo walks you through establishing connectors to Kafka Redpanda and Elastic via SQL DDL statements, building streaming jobs via SQL DML statements, and wiring the data and visualizations together via Kibana. We won’t repeat the steps here, instead we encourage you to follow the instructions exactly as described in the original article.
docker-compose.ymlIt’s worth going through the changes made to docker-compose.yml in case you want to build your own Redpanda powered projects using Docker Compose. We updated to a more current compose version (3.7), replaced the kafka and zookeeper services with a redpanda service, and updated the service dependency graph appropriately. The Redpanda service declaration looks like the following:
redpanda:
image: docker.vectorized.io/vectorized/redpanda:v21.8.1
command:
- redpanda start
- --smp 1
- --memory 512M
- --overprovisioned
- --node-id 0
- --set redpanda.auto_create_topics_enabled=true
- --kafka-addr INSIDE://0.0.0.0:9094,OUTSIDE://0.0.0.0:9092
- --advertise-kafka-addr INSIDE://kafka:9094,OUTSIDE://localhost:9092
hostname: kafka
ports:
- "9092:9092"
- "9094:9094"
volumes:
- /var/lib/redpanda/dataSome of these parameters are worth mentioning, especially if you’re new to Redpanda. For one thing, Redpanda follows a thread-per-core model, and likes to consume all available resources in the host environment when permitted. This is great for production deployments, but not ideal when you are prototyping on your laptop. The first three parameters mentioned below are startup flags that tell Redpanda to play nice with other processes in a shared host or VM.
--smp 1 Limits Redpanda to only use one logical core.--memory 512M Limits Redpanda to 512M memory. Alternatively, you can specify --reserve-memory N, which lets Redpanda to grab all the available memory, but reserving N for the OS and other processes.--overprovisioned Indicates to Redpanda that there are other processes running on the host. Redpanda will not pin its threads or memory, and will reduce the amount of polling to lower CPU utilization.--node-id 0 This is a required parameter. Every broker in Redpanda is identified by a node-id that survives restarts.--set redpanda.auto_create_topics_enabled=true Equivalent to setting auto.create.topics.enable=true in Kafka.hostname: kafka In Docker Compose, the default hostname is based on the service name. We override this with hostname: kafka, so we can stay compatible with the connector declaration from the original demo script.volumes: /var/lib/redpanda/data This tells Docker Compose to make a volume available for that path, which is the default Redpanda data directory.Docker and Docker Compose are great for developer productivity as they allow for quick assembly of different application components. Developers can build rapid prototypes of end-to-end applications all within their local environment. In this article, we showed how to retrofit an existing application prototype using Kafka (as well as Flink, MySQL, Elastic, Kibana) with Redpanda. Using Redpanda containers in lieu of Kafka and Zookeeper for your streaming stack has some nice benefits, including faster startup times and more efficient resource consumption.
We believe that this way of prototyping is conducive to building new streaming applications. In particular, Redpanda for event sourcing and Flink SQL for stream processing is a powerful, easy-to-use combination. The upcoming Redpanda Data Policies feature will allow for outbound data transformation via WASM. Eventually we can use this to implement capabilities like predicate and projection push-down, which have the potential to speed up basic streaming operations by reducing the amount of data that goes from Redpanda to your stream processors.
In the future, we want to provide more prototype examples of Redpanda with Flink SQL, and also explore Redpanda in combination with other streaming engines. Our goal is to make Redpanda the best persistence layer for streaming. Watch this space!
Subscribe to our VIP (very important panda) mailing list to pounce on the latest blogs, surprise announcements, and community events!
Opt out anytime.