Apache Iceberg Topics: Query Streaming Data as Iceberg Tables
Apache Iceberg Topics in Redpanda revolutionize how organizations manage and consume streaming data, enabling instant analytics on streaming data without the complexities of traditional ETL processes.


.svg)
Why Iceberg Topics?
Available on all clouds - AWS, Azure, GCP
Apache Iceberg Topics in Redpanda allow you to query real-time data while it’s still streaming. Iceberg Topics build on Tiered Storage to store streaming data as both logs and Iceberg tables backed by Parquet files in cloud object stores. Access real-time events with SQL or programmatically using any Iceberg-compatible lakehouse, tool or engine, including Snowflake, Databricks SQL, Google BigQuery, ClickHouse, AWS Athena, Spark SQL, Python, Flink, Starburst, Hive, IBM Watson, etc. Getting real-time insights for faster decisioning has never been easier.
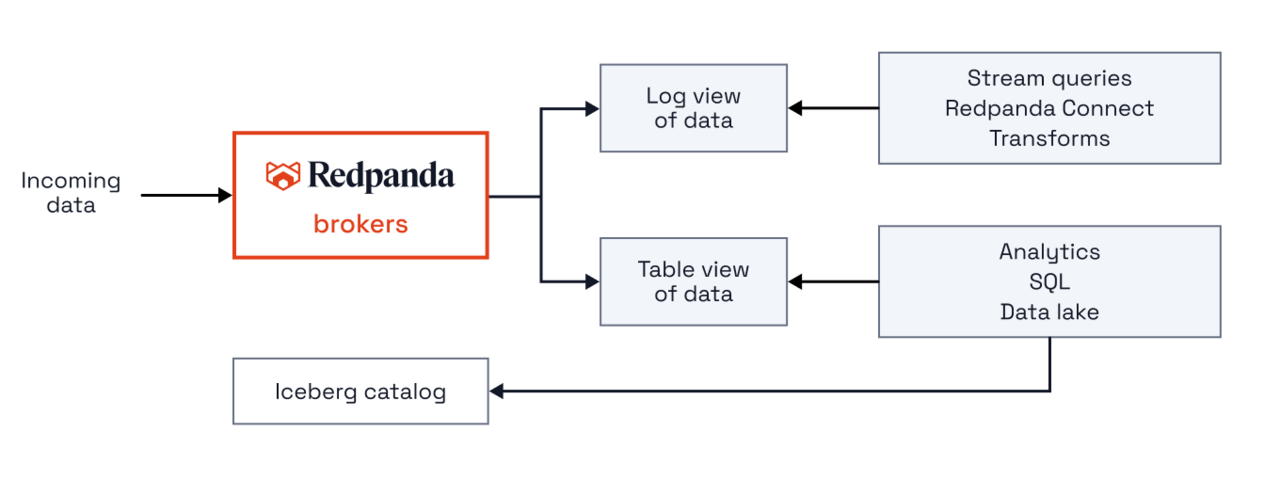
Demo of Apache Iceberg Topics in Redpanda:
Zero ETL for Instant Insights
Store streaming data directly in the Iceberg open table format, making it immediately accessible for analytics. This eliminates the need for complex ETL pipelines, accelerating time-to-insight.
Seamless Integration with Analytics Tools
Combine real-time and historical data effortlessly, supporting both streaming and batch analytics within your data lakehouse architecture. Access streaming data using popular analytics platforms, thanks to Iceberg’s broad industry adoption as the leading open table format.
Catalog Integration for Discovery and Governance
Leverage your existing REST-enabled Iceberg catalog service, such as Tabular/Databricks, Snowflake Open Catalog, AWS Glue and others to simplify how the streaming data is discovered and governed.









