




Stream Oracle changes to ClickHouse in real time with Redpanda Connect
A hands-on walkthrough of our new Oracle CDC connector
Using Boost.Beast to implement a custom HTTP client.









For request serialization, Redpanda's HTTP client uses the request_serializer template with header and string_body as parameters from the Boost.Beast library. This serializer uses split serialization, which means it serializes the HTTP header but omits the body. The client then sends the contents of the body separately, which avoids any data copying if the body is represented as an iobuf or seastar::input_sream.
Redpanda's HTTP client uses a custom implementation called iobuf_body to handle response parsing. This implementation replaces the string_body object and doesn't store all its data in a contiguous buffer. Instead, it has an internal iobuf instance, a fragmented buffer implementation. This allows the client to read data lazily using limited memory resources and to avoid unnecessary data copying. The response_parser passes every incoming raw buffer to the BodyReader concept implementation using the PUT method.
The HTTP client in Redpanda needs to use the RPC implementation for transport, which uses Seastar's net package internally. It should also support zero-copy networking with DPDK, allow asynchronous operation using Seastar futures, avoid unnecessary data copying, and be as standards-compliant as possible. The client is also expected to handle a vast amount of data, and to minimize cache pollution, it should avoid copying data multiple times.
Redpanda decided to use Boost.Beast to build its HTTP client. Boost.Beast was chosen because it is highly customizable and allowed Redpanda to integrate a request serializer and response parser with their iobuf type. Redpanda didn't use it as a full-featured HTTP client, but rather as a request serializer and response parser.
Redpanda required an HTTP client to access the Amazon AWS API. This client needed to support features like TLS 1.2, chunked encodings, and custom headers. However, most HTTP libraries weren't compatible with Seastar's threading model, which Redpanda uses, as they have their own thread pools, event loops, blocking I/O, locks, or all of these simultaneously.
The Seastar framework offers a great HTTP server implementation, which is used by ScyllaDB and Redpanda. However, Seastar doesn't have an HTTP client library that can be easily used with Seastar framework. So we made one.
In Redpanda, we need an HTTP client to access the Amazon AWS API. This means that the client has to have features like TLS 1.2, chunked encodings, and custom headers. There are many convenient HTTP libraries that implement this but Seastar's threading model is not compatible with most of HTTP libraries. The libraries use their own thread pools, event loops, blocking I/O, locks, or all of those simultaneously. To get the best performance with Seastar, the entire application codebase needs to use the future/promise model to express all I/O operations.
The basic requirements for our HTTP client are that it:
For the sake of not reinventing all of this we decided to use Boost.Beast. We're not using it as a full-featured HTTP client, although I'm pretty sure that Boost.Beast is a great one. Instead, we're using it as a request serializer and response parser. Luckily, the library is very customizable and allows us to integrate parser and serializer with our iobuf type.
The Boost.Beast library provides request_serializer and response_parser templates. Both of them can be parameterized. The important parameters of the template are fields and body implementations. The fields has a collection of key-value pairs that hold the contents of the HTTP-header. It also contains some basic properties like HTTP method (GET, POST,...), status code, and target URL. The body is an object that stores the contents of the HTTP body without any protocol artifacts, such as chunked encoding headers. The Boost.Beast library has several implementations of the body concept. For instance, the string_body treats its contents as a string and stores it in a contiguous memory region.
For the serialization of the request, we used the request_serializer template with header and string_body as parameters. This is what a normal HTTP client would use -- no tricks, except that we used it only to generate the request header.
The request_serializer implements split serialization. When enabled, the request_serializer serializes the HTTP header but omits the body.
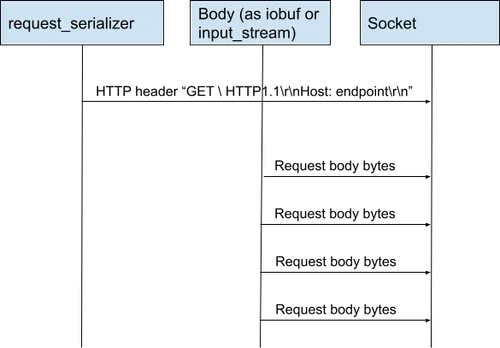
Our HTTP client uses the serializer to serialize the header and then it sends the contents of the body. If the body is represented as an iobuf or seastar::input_sream, the operation won't result in any data copying. The serializer has its own chunked-encoding serialization mechanism that works with iobuf and supports zero-copy as well.
Response parsing is a bit more complicated. Split parsing is not supported by the response_parser. This means that every byte should go through the body implementation that we use. If we'd use the response_parser with the string_body type as a parameter, we`ll end up reading everything into memory. Going forward, we need to solve two problems:
To achieve this we implemented a replacement for the string_body object which is called iobuf_body. It implements the body interface and, contrary to string_body, it doesn't store all of it's data in a contiguous buffer. It has an internal iobuf instance, our fragmented buffer implementation.
Normally, the response_parser goes through every incoming raw buffer and parses it. Every fragment of the HTTP body is passed to the BodyReader concept implementation using the PUT method.
The iobuf_body behaves as shown here:

First, it lets you set a source buffer in advance (1). This should be a buffer that we just received from the socket and need to parse. This buffer is passed to the response_parser as an input (2). The response_parser analyzes it and invokes the PUT method of the iobuf_body instance (3). The iobuf_body compares the incoming HTTP-body fragment with the source buffer. If the incoming buffer is a part of the source buffer, the iobuf_body just borrows the reference to it from the source and adds it to its internal iobuf (performing zero-copy). Finally, the client of the library consumes the next fragment as an iobuf instance (4) that contains fragments of the original “source” buffer.
In some cases, an actual copy is needed, for example when response_parser passes a stack-allocated buffer to the append method. In this case, the parser does a normal copy operation and the client consumes the iobuf instance that contains copied data. But this backoff mechanism is not supposed to be used frequently.
The response parsing sounds pretty complicated, but the client of the library doesn't have to deal with all this. It's just an internal implementation detail.
The HTTP client integrates with Seastar's native input_stream and output_stream interfaces. This lets the client of the library to stream data without loading it into memory first.
auto file = co_await seastar::open_file_dma(path,
ss::open_flags::rw | ss::open_flags::create);
auto stream = co_await seastar::make_file_output_stream(std::move(file));
http::client client(client_conf);
http::client::request_header header = ...create GET request header
auto resp = co_await cli.request(header);
co_await ss::copy(resp->as_input_stream(), out_file);ion looks (thanks to C++20 and Seastar streams).
Boost.Beast offers great flexibility that makes it possible for us to integrate the library with our transport layer. It also enables a zero-copy mechanism that lets us read data from disk directly into memory using DMA and use the same buffer to send it through this HTTP client without copying. And that's exactly what we need.
If you want to hear more about what we're up to, join us on Slack, or if this is the kind of technology you want to hack on, we are hiring.
From all of us at Redpanda, we hope to see you soon!
Subscribe to our VIP (very important panda) mailing list to pounce on the latest blogs, surprise announcements, and community events!
Opt out anytime.

