





5 predictions about agentic AI and analytics in 2026
What AI trends will shape analytics in the coming months?
Comparing the performance of Graviton-based systems vs x86 hardware for real-time event-driven applications.








Software running on the Java virtual machine, the .NET platform, using a JavaScript engine, or an interpreted language like Python, Ruby, or Lua may not need any porting work at all. If your application is a compiled-to-native binary written in C++, it must be recompiled and perhaps ported to Arm. This might involve changing a few compile flags for a handful of dependencies and updates to packaging.
To profile the bandwidth, you can use fio (the Flexible I/O Tester). This tool allows specifying an I/O testing pattern in a configuration file, and includes many different I/O engines testing different system-level I/O APIs. For the test, you can use a 16 KiB block size, and a sequential write test using four jobs writing directly to disk.
Data intensive systems place heavy demands on disk and network bandwidth. The storage optimized systems have high bandwidth in both areas, so the bottleneck will depend on the particular ratio of network to disk traffic in your workload. Data streaming workloads like those accelerated by Redpanda tend to have relatively balanced network and disk loads, with the exact ratio depending on the context. The limiting factor often ends up being the disk.
Redpanda is a developer-centric modern streaming data platform that is API-compatible with Apache Kafka®. It relies heavily on disk performance, particularly disk throughput and durable write latency, making it a good target for investigating Graviton instance types. Redpanda was released on Arm in 2021 and can be built from source or installed from pages following the instructions on GitHub.
The Graviton processor, launched at the end of 2018, was one of the first non-x86 CPU offerings by a large cloud vendor. The initial Graviton 1 chips offered good price-to-performance for workloads that could be ported to Arm. The second-generation Graviton 2 chips, released in 2020, had better than 50% per-core performance and much larger and more varied instance types, with up to 64 cores and up to 512 GiB of RAM.
Since the emergence of large cloud hosting providers such as Amazon’s EC2, x86 processors have been virtually the only game in town. Alternative server CPU architectures such as IBM’s POWER and Oracle’s SPARC exist, but they have had little impact in commodity cloud hosting.
Amazon changed that dynamic when it decided to offer Arm architecture chips on their Elastic Compute Cloud (EC2) service. Arm chips, which have grown up from use in much smaller devices such as mobile phones, are now available to run your heaviest workloads.
We are data fanatics. Our customers build data-intensive applications that ingest gigabytes of data daily using Redpanda. So we were naturally curious to see if these instances are competitive with x86 architecture instances when it comes to hosting data-intensive applications.
In this post, I explore this question in detail.
Launched at the end of 2018, Amazon Web Services' Graviton processor was notable as one of the first and only non-x86 CPU offerings by a large cloud vendor. The initial Graviton 1 chips (in the a1 instance types) offered good price-to-performance for workloads that could be ported to Arm. This was in spite of the fact that the maximum machine size was limited (a1.4xlarge with 16 CPUs and 32 GiB of RAM), the available instance shapes were limited to the a1 type (roughly equivalent to "General Purpose" x86 instances), and single-threaded performance was considerably lower than contemporary x86 offerings. While this release gave us a taste of what the Graviton family had to offer, the real meal would come later in 2020 with the release of the second-generation Graviton 2 chips.
If the initial Graviton was Amazon dipping its toes into the CPU pool, Graviton 2 was a cannonball from the highest diving board. Available around mid-2020, Graviton 2 was a significant leap over its predecessor. It had better than 50% per-core performance and, more importantly, much larger and more varied instance types, with up to 64 cores and up to 512 GiB of RAM. Many testimonials followed Graviton 2’s release, showing that these Arm-powered instance types offered a significant boost for price/performance over x86 instances.
Recently, Amazon introduced additional storage-focused Graviton 2 instance types: Is4gen and Im4gn with attached NVMe SSD storage. The Is4gen instances have the same CPU count as an Im4gn instance of the same size, but twice the storage and 50% more memory. These instance types target similar workloads to the storage-optimized I3 and I3en x86 instance types.
We are interested in the performance of these new Arm instance types for data-intensive services such as Redpanda: how do they stack up to the x86-based instances? To answer this question, we present a comparison of the Arm and x86 storage optimized instances on EC2.
Redpanda is a developer-centric modern streaming data platform that is API-compatible with Apache Kafka®. An important goal that we set for ourselves was to allow our customers to use Redpanda on any platform of their choosing. We released Redpanda on Arm in 2021 and you can build it from source or install it from pages following the instructions on GitHub.
Redpanda relies heavily on disk performance, particularly disk throughput and durable write latency, so it makes for a good target for investigating Graviton instance types.
The value proposition offered by a switch to Arm-based servers is most obvious in the case of software built on an intermediate layer. Software running on the Java virtual machine, the .NET platform, using a JavaScript engine, or an interpreted language like Python, Ruby, or Lua may not need any porting work at all. Once the underlying runtime for these languages is available on Arm, you can expect your code to “just work.”
If your application is like Redpanda, which is a compiled-to-native binary written in C++ and uses dozens of native third-party libraries, this might be tricky. To run our code and the entire constellation of dependencies, it must be recompiled and perhaps ported to Arm.
Despite this, and somewhat to my surprise, porting Redpanda was less difficult than you might think. The experienced engineer who did the work described changing a few compile flags for a handful of dependencies and updates to packaging: a small total amount of work.
A typical change in the cmake build scripts would be changing some x86-specific flags to depend on the detected processor. For example, changing the following unconditional setting of the -march (machine architecture) flag:
set(RP_MARCH "-march=westmere" CACHE STRING)to instead be conditional:
if (${CMAKE_SYSTEM_PROCESSOR} MATCHES "aarch64")
set(RP_MARCH "-march=armv8-a+crc+crypto" CACHE STRING )
else ()
set(RP_MARCH "-march=westmere" CACHE STRING)
endif ()After a handful of these changes, and an update to the packaging workflow to create Arm packages, the deed was done.
No modifications to the C++ source were necessary.
One aspect of our development process which made this easy was that we “vendor” all of our third party dependencies. That is, we use a pinned version of the dependency source (generally the upstream version or a fork if we have outstanding changes) and build each package ourselves. This allows us to make changes to a temporary fork of any project without the need to wait for upstream to accept a pull request (though we do endeavor to send PRs upstream, too, so that we are aligned with upstream as much as possible). In this case, we could adjust the build process as necessary to produce Arm binaries.
Data intensive systems place heavy demands on disk and network bandwidth. The storage optimized systems we will compare today have high bandwidth in both areas, so which is the bottleneck will depend on the particular ratio of network to disk traffic in your workload.
Data streaming workloads like those accelerated by Redpanda tend to have relatively balanced network and disk loads, with the exact ratio depending on the context. Here we will focus on a pure ingestion workload which has roughly a 1:1 network to disk ratio, and as the instance types in question have more network bandwidth than disk bandwidth, the limiting factor ends up being the disk.
Given that disk speed rules, we’ll focus on that aspect in this initial evaluation of these instances. In particular, we will examine the following three disk-related benchmarks:
In this comparison, we limit focus to one of the storage optimized instance families for each architecture: the Intel Skylake-SP based I3en family as well as the new Arm Graviton 2 based Is4gen family.
Since we expect disk bandwidth to be the limiting factor, we first check the raw disk write bandwidth offered by Intel (I3en) and Graviton 2 (Is4gen) instance types.
To profile the bandwidth, we use fio (the Flexible I/O Tester) written by Jens Axboe and collaborators. This state of the art tool allows specifying an I/O testing pattern in a configuration file, and includes many different I/O engines testing different system-level I/O APIs. In particular, fio allows us to define a reasonable approximation of the I/O patterns imposed on the disk by data-intensive applications like Redpanda.
For our test, we use a 16 KiB block size, and a sequential write test using four jobs (threads, roughly speaking) writing directly to disk (bypassing the page cache). To be even more specific, we use the following fio configuration:
[file1]
rw=write
bs=16K
direct=1
numjobs=4
time_based
runtime=100
size=100GB
ioengine=libaio
iodepth=128The results are as follows:
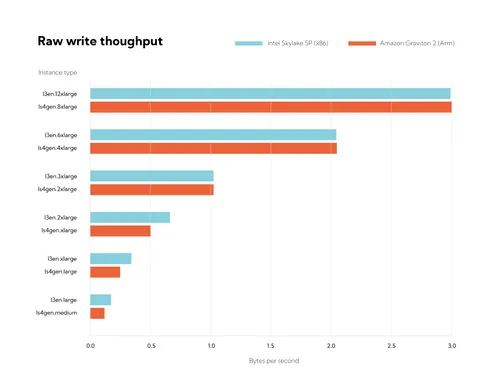
What sticks out is the similarity between the two sets of results: for the larger sizes they are identical (though there’s a multiplier of 1.5: an Is4gen 8x instance has the same throughput as a 12x I3en instance). We can’t yet conclude which offers better throughput for each dollar spent, but we’ll get there below.
We can also see something about scaling with size: at each 2x step up in instance size, throughput almost exactly doubles. The relationship only breaks down with the 8xlarge instance size, which is only about 50% faster than the 4xlarge size for the Is4gen Graviton 2 instance family (and a similar reduction in scaling occurs for the Intel instances). This seems to be a limitation of the Linux block layer at the parameters used in the fio test which can't saturate this 4-way RAID0 configuration: with larger block sizes we are able to reach 4 GB/s on the 8xlarge instance, representing the expected doubling of throughput over the next smaller size.
For a data streaming system, maximum ingestion throughput is a key performance metric. It describes the total aggregate size of incoming messages a system can support and is expressed in bytes per second. If the incoming rate exceeds this value, producers will fall behind and may ultimately drop messages. Sizing your system to run below the maximum ingestion rate is key to reliable performance.
Ingestion throughput isn't necessarily a single absolute value—the system may have different bottlenecks when many small records are sent from many clients versus larger batches sent by few clients. Here, we will stress the latter case: reasonably large messages (1K) sent by a handful of clients on the same local network.
Let us check ingestion throughput for a single-node Redpanda cluster, on the same Is4gen Graviton 2 and Intel I3en instance families that we benchmarked above.
We use the Apache librdkafka (a popular C/C++ Kafka client library) benchmark, rdkafka_performance, which allows us to set up a simple message producing scenario. We use 24 concurrently running copies of the benchmark, spread across three c6i.8xlarge instances in the same VPC, with the following command line:
rdkafka_performance -P -c 100000000 -s 1000 -t <random topic name> -b <broker IP> -uThat sends 100 million messages from each client (for a total of 2.4 billion) with size 1 KB to a single topic. Client settings are left at their defaults. The topic is configured with 64 partitions, though the performance here does not depend strongly on the partition count.
The Redpanda cluster settings are at their “production” default, including running all tuners (which update some OS tunables as well as set parameters for Redpanda’s internal I/O scheduler).
Running the above benchmark across most instance types in the family gives the following results:
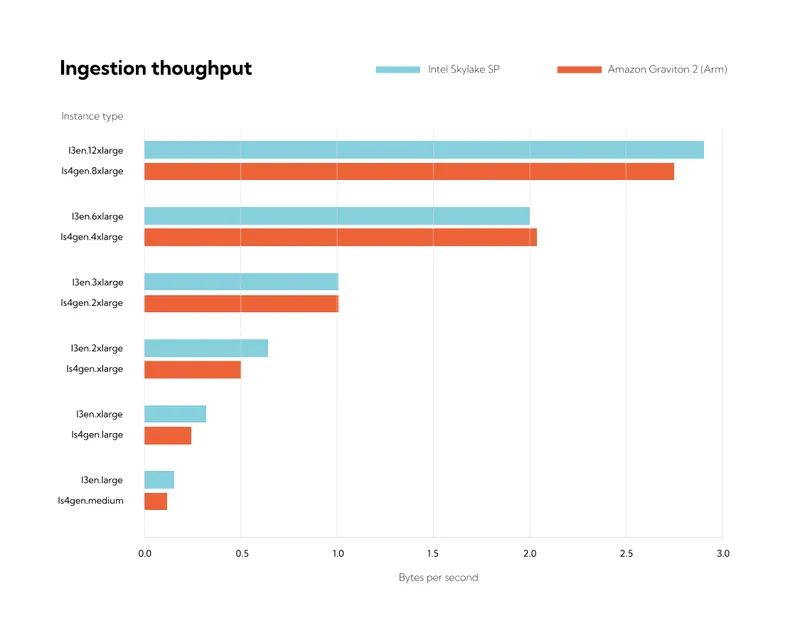
I can't blame you if you think I've just copy & pasted the prior plot here, but that is not it. Rather this plot shows that Redpanda is able to achieve the very close to the same results as the fio benchmark, as it saturates the disks (again with the caveat regarding the largest tested instance on each architecture).
However, it is hard to say much about the relative value offered by the two instance families from this plot alone. Instead, let us normalize by the instance on-demand cost:
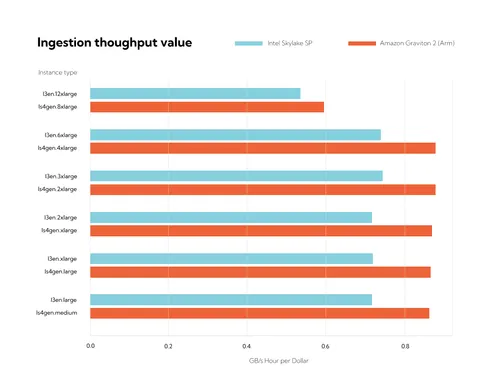
Here, the units are GB/s*hours/$, which is quite a mouthful. (As a side note, since time appears on both the top and bottom of these units, we can simplify this to just GB/$ or, because we know messages are 1,000 bytes each, "messages per dollar.") In this example, producing a 1,000-byte message to Redpanda only costs about three ten-billionths of a dollar.
Based on the normalized cost, it is apparent the Arm instances offer a competitive cost-per-byte of throughput, coming with about a 20% edge over the Intel instance types. For this simple test, it doesn't matter much which instance type is chosen when "value" is the metric since performance closely tracks disk bandwidth, and EC2 prices bandwidth equally across an instance family.
A nice feature of the new Graviton 2 instances is that they all have “smooth regulation” for their SSD throughput. To understand what we mean here, it is perhaps easiest to look at this in comparison to something which isn't “smooth.” Take, for example, this comparison of SSD throughput for I3.large and Is4gen.large instances:
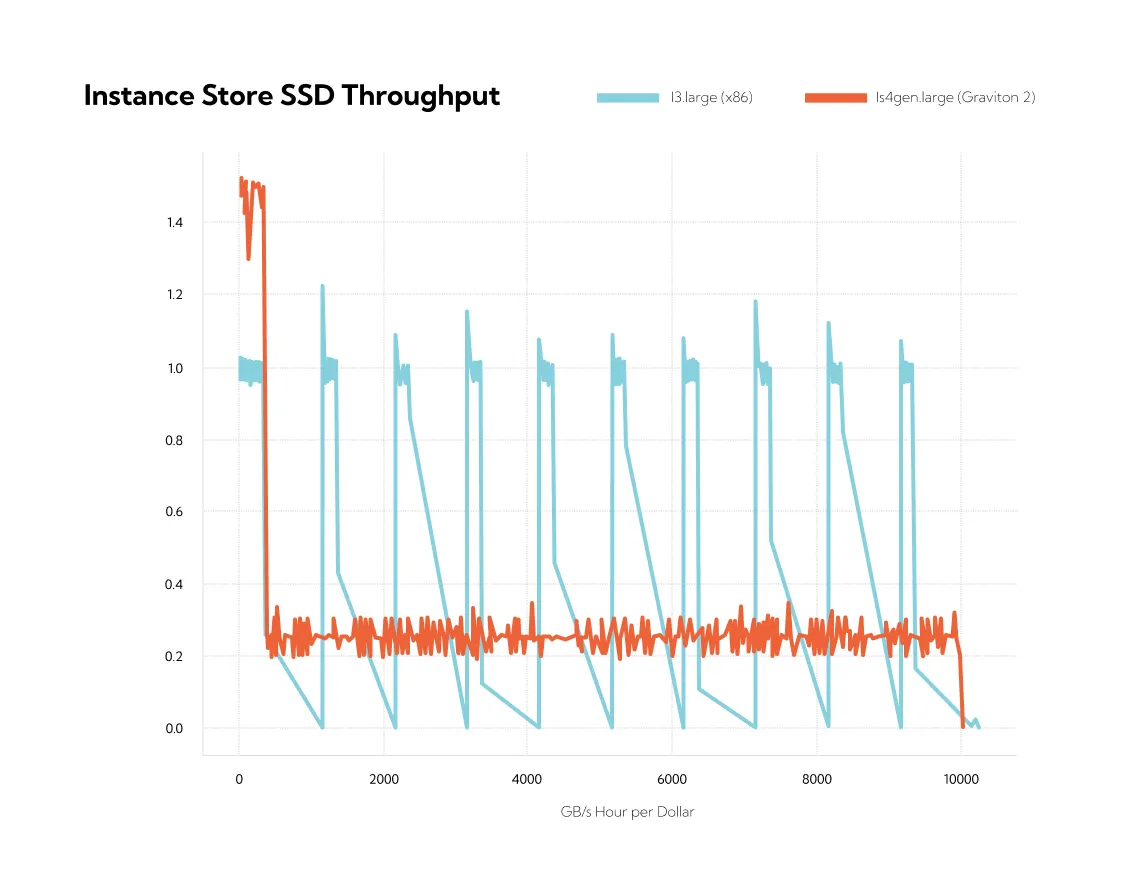
That's quite the contrast in behavior. Roughly speaking, the I3.large instance runs at a high throughput close to 1 GB/s for just under 200 ms of every second, then flatlines to zero throughput after that. Not just close to zero, either—more like absolute zero. The next write of a 16K block doesn't return until the next second arrives some 800 ms later. On the other hand, the Is4gen.large throughput is very consistent at just under 200 MB/s.
This behavior may be a result of several virtual machines (VMs) sharing access to a single underlying SSD for these smaller instance sizes. Some hardware or firmware component is load-balancing access from the various VMs getting a slice of the SSD (four I3.large VMs can share one 1900 GB SSD). This might implement something like a token bucket system with a granularity of one second. Every second the VM gets a full allocation of ~200 MB of write credits, but it can burn through them at 1 GB per second, leaving nothing left for the rest of the time. Rinse and repeat.
Is this behavior a problem for high-availability services running on these instance types? Well, it doesn't make the engineer’s life any easier. You never want to incur these long 800 ms stop-the-world hiccups, but any large write puts you at risk. If some background process suddenly writes out a large file? Take a 800 ms break. It is also difficult to apply effective back-pressure to clients in this scenario. Things seem like they are going great in the "fast" part of each second. There is no apparent queuing of I/O and it seems reasonable to accept more requests at the moment, but that doesn't look like a good idea after the great slowdown.
However, one can also make the opposite argument: this bursty behavior gives you the ability to satisfy some large requests much more quickly (at 1 GB/s), as long as they are appropriately spaced out. In principle, you can avoid the downtime by carefully limiting the throughput at the application level. In practice, however, this is fraught with various problems, and one would usually prefer the stable behavior which is present on the new Graviton 2 instances, as well as the I3en instances. In this case, if you want the I3 shape, I would recommend the larger instance sizes where this effect is less pronounced (the zero-throughput period is much smaller).
Of course, our ingestion throughput mostly stresses two components of our cluster: disk and network throughput. However, there are plenty of other dimensions along which we might reasonably compare these instance types. For example, the amount of fast NVMe storage each type comes with, the guaranteed network bandwidth, random-access memory amount, and so on.
We don’t need to benchmark these, since they are simply publicly available attributes of the instance types. Here’s a table comparing the I3en and Is4gen instance types head-to-head:
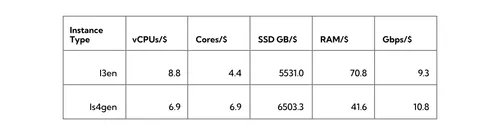
This table applies to most instance sizes as both cost and resources generally increase proportionally for larger instance types, with a few mostly minor exceptions.
The situation with vCPUs and cores is a bit complicated. On EC2, each Intel Skylake core with hyperthreading counts as two vCPUs, while each Graviton core has a single hardware thread and counts as a single vCPU. So, if you count cores, you get a much better deal with Graviton 2: 57% more cores per dollar! However, because of the 2:1 ratio between cores and vCPUs on Intel, the situation is reversed if you are counting vCPUs: you get 28% more vCPUs on the Intel instance type.
Generally speaking, one Graviton 2 core (at 2.5 GHz) is competitive with, and perhaps slightly slower on average than, a Skylake core (at 3.1 GHz) for single-threaded code (i.e. not using the second hardware thread on the Skylake part). So, 57% more cores sounds like a great deal in favor of the Arm instance type. However, once you run more threads and can take advantage of hyperthreading, the situation gets murkier. Most importantly, this is workload dependent: averages are one thing but what matters is your workload, and there is a lot of variation between them. If you forced my hand, I’d still give an edge to Arm in the CPU pricing department.
Arm instances also have a small edge in SSD capacity and guaranteed network bandwidth (17% and 18%, respectively) over the Intel instances. But Intel has a big edge (70%) in RAM per dollar spent. Overall, we can say there is no clear winner on these other factors, and it will depend a lot on your workload.
In this post, we have taken a first pass at examining the performance of Graviton 2 using Redpanda as a target application, with results that show Arm at about a 20% price/performance advantage over Intel instances for a high-throughput message ingestion scenario. We also examined throughput regulation behavior on some EC2 instances, and took a look at other key instance metrics.
We also profiled and discussed a curious performance issue on the I3 instance type where SSD throughput at saturation oscillates between a period of high throughput and zero throughput, reaching the documented throughput when averaged over one second. This behavior doesn’t occur on I3en or the new Graviton instance types.
Overall, we can say that Amazon has built a strong contender here and it’s worth considering these new storage-optimized Arm instances for your storage intensive workloads.
To learn more about Redpanda or discuss these benchmarks with our engineers, please join our community Slack or check out our GitHub.
What AI trends will shape analytics in the coming months?

Benchmark shows Vera provides 5.5x lower latencies and up to 73% higher throughputs than other leading CPU models

Learn from the leaders actually shipping and scaling AI agents today
Subscribe to our VIP (very important panda) mailing list to pounce on the latest blogs, surprise announcements, and community events!
Opt out anytime.