




Bridge Queries in Redpanda SQL
Have your real-time cake and eat your analytics too
A practical analysis of observability tools, optimal batch sizing, and the impact of write caching









You can use a Grafana visualization with a PromQL query to calculate the average effective batch size by topic in Redpanda. The formula is: sum(irate(vectorized_storage_log_written_bytes{topic!~"^_.*"}[5m])) by (topic) /sum(irate(vectorized_storage_log_batches_written{topic!~"^_.}[5m])) by (topic).
Redpanda provides both public and private Prometheus metrics for deep introspection into the cluster and workload behavior. Some of these metrics include 'vectorized_storage_log_written_bytes' and 'vectorized_storage_log_batches_written' for the number of bytes written and count of message batches since process start respectively. 'vectorized_scheduler_queue_length' is a metric for the broker's internal backlog of tasks, and 'redpanda_cpu_busy_seconds_total' is a public metric for evaluating CPU utilization.
For high-volume workloads in Redpanda, it is recommended to target at least a 4 kilobyte (KB) effective batch size and upwards of 16 KB where possible to really unlock performance. This is because NVMe storage, which is recommended for high-performance, low-latency workloads, tends to write out data in 4 KB aligned pages.
When tuning a high-performance Redpanda system, you can achieve efficiency improvements, latency changes, control resource utilization, and reduce back pressure. Increasing the effective batch size can open up capacity on the cluster without adding hardware. Reducing CPU usage allows more work to be done with the system, or it can enable you to right-size the system to reduce costs.
Write caching is a mechanism Redpanda supports that helps alleviate the broker-side issue from having many tiny batches. It shifts the broker's behavior when writing out messages to disk. With write caching enabled, the brokers acknowledge as soon as the message is in memory. Once a quorum is reached, the leader acknowledges back to the client, and the brokers can flush larger blocks of messages to disk, taking better advantage of the storage. This is similar to how a storage controller might take many small writes and assemble them into a single large write to preserve storage IOPS capacity.
In part one of this batch tuning series, we discussed batching from first principles, how to configure batching, and what affects batch sizes. If these topics sound unfamiliar, read the first blog before you go any further.
In this second part, we dive into some practical analysis with observability tools, recommendations, and guidance when tuning. Plus, a quick detour into write caching when client-side tuning may not be possible. Lastly, we'll touch on a real-world example we recently completed with a customer.
Redpanda emits Prometheus metrics for deep introspection into the cluster and workload behavior. The metrics are split between public and private groups. The private endpoint contains several metrics critical to seeing the effective batch size at the cluster and topic level.
vectorized_storage_log_written_bytes - private metric for the number of bytes written since process startvectorized_storage_log_batches_written - private metric for the count of message batches since process startvectorized_scheduler_queue_length – private metric for the broker's internal backlog of tasks to work through redpanda_cpu_busy_seconds_total – public metric for evaluating CPU utilizationWe can use a simple Grafana visualization with a PromQL query to turn this into the average effective batch size, breaking it down by broker, topic, and partition. Additionally, we want to check other areas, such as the batch rate per CPU core, scheduler backlog, and batches written per topic.
Average effective batch size by topic:
sum(irate(vectorized_storage_log_written_bytes{topic!~"^_.*"}[5m])) by (topic)
/
sum(irate(vectorized_storage_log_batches_written{topic!~"^_.}[5m])) by (topic)
Average batch write request rate per core:
sum(irate(vectorized_storage_log_batches_written{topic!~"^_.*"}[5m])) by (cluster)
/
count(redpanda_cpu_busy_seconds_total{}) by (cluster)
Batches written per second per topic:
sum(irate(vectorized_storage_log_batches_written{topic!~"^_.*"}[5m])) by (topic)
Size of the scheduler backlog:
sum(vectorized_scheduler_queue_length{}) by (cluster,group)
CPU utilization:
avg(deriv(redpanda_cpu_busy_seconds_total{}[5m])) by (pod,shard)
When we tune a high-performance Redpanda system, we want to take a systematic, scientific approach where one option is modified at a time, evaluated, and accepted or rejected. This lets us look at the behavior of the change and establish new baselines to work from. There are several areas to look at as tuning happens, including efficiency improvements, latency changes, controlling resource utilization, and reducing back pressure.
In our tuning work with customers, we've found that increasing that effective batch size has allowed us to open up capacity on the cluster without adding hardware. For example, when the CPU is saturated at 100%, you inherently start to experience back pressure on the producers because there's no more space for work. Reducing CPU usage allows more work to be done with the system, or it will enable you to right-size the system to reduce costs.
Reducing the saturation of the system also inherently lowers latency (especially at the tail) and back pressure. If the system can work, client requests don't stack up. Those requests can be completed promptly upon arrival, rather than waiting in an internal work queue to be picked up and completed.
One under-appreciated side effect of batch size tuning that we've encountered is a reduction in overall network traffic for the same volume of message flow. Not only does improving batch size increase compression efficiency, it also reduces Apache Kafka® protocol overhead and duplication of header metadata.
Redpanda uses the underlying cluster hardware as efficiently as possible. We recommend targeting your high-volume workloads for at least a 4 kilobyte (KB) effective batch size and upwards of 16 KB where possible to really unlock performance.
Using NVMe SSD storage is a strong recommendation for high-performance, low-latency workloads. NVMe storage tends to write out data in 4 KB aligned pages. No problem if your message batch is 4 KB or larger. But what happens if you're sending millions of tiny, single message batches per second? Each message will be written alone in a 4 KB sized write, no matter how small it is: causing a large degree of write amplification and inefficient use of the available disk IO Small batches also use significant CPU, which may saturate the CPU and drive up end-to-end latency as the backlog of requests starts to pile up.
Write caching is a mechanism Redpanda supports that helps alleviate the broker-side issue from having many tiny batches (or single message batches). This is especially useful for cases where your architecture makes it hard to do client-side tuning, change the producer behavior, or adjust topic and partition design.
Write caching shifts the broker's behavior when writing out messages to disk. In Redpanda’s default mode, where write caching is off, the batch is sent to the leader broker, it writes it to disk, replicates it to the replica brokers, and once they acknowledge the successful write to disk, the leader confirms back to the client. You can see how additional latencies might pile up here.
With write caching enabled, the same procedure happens, but the brokers acknowledge as soon as the message is in memory. Once a quorum is reached, the leader acknowledges back to the client, and the brokers can flush larger blocks of messages to disk, taking better advantage of the storage. This is similar to how a storage controller might take many small writes and assemble them into a single large write to preserve storage IOPS capacity.
The write caching mechanism is similar in function to how Kafka commits batches to in-memory buffer cache and then periodically flushes that cache out to disk. When write caching is enabled in Redpanda, the data durability guarantees are relaxed but no worse than a legacy Kafka cluster.
Let's jump into a real example exhibiting why your effective batch size matters. In 2024, we migrated a customer from Kafka to Redpanda Cloud using BYOC clusters. Their workload was calculated around 1.75 to 2 GB per second and several million messages per second.
Initially, we started partially loading them onto a Tier 7 cluster capable of 1.2 GB per second of produce volume with the plan to scale up to larger tiers as the load was moved over. We found that with only 50% of the load moved, the cluster CPU was saturated at >90% during peak hours.
While moving them to higher tiers was possible, we made an architectural decision to split the work across two Tier 7 clusters because of other capacity and timeline requirements. Latency was acceptable during those periods, but there was concern that future growth would drive up operational costs, requiring more clusters to handle the increases.
Over the summer of 2024, the customer returned and asked how we could reduce CPU utilization to consolidate the clusters into the next tier up while reducing infrastructure costs. Together, we dug into the workload behavior with their application team. Initially, everyone believed that the effective batch size was close to the configured batch size of their producers.
What nobody had accounted for, however, was the multiple use cases flowing through the cluster, each contributing its own shape to the traffic. In the sizing sessions, we originally evaluated behavior based on aggregate cluster volume and throughput, not the individual impact of heavier-weight topics, nor had this taken into account an extremely small producer linger configuration.
As we dug into the per-topic effective batch size, we noticed that some high volume topics were batching well below their expected size. These topics created hundreds of thousands of tiny batches, driving up the Redpanda request rates. In turn, this was causing a backlog of requests to stack up on all brokers, driving up all latencies from median to tail.
Cross-checking with the math, we now accounted for the message arrival rate at the producers, producer, partition count, and client configuration, confirming what we saw with our performance dashboards. The extremely low linger configuration never allowed the configured batch size to fill, so the batch was always triggering early.
Over several days, we made three separate adjustments of linger time across their applications and watched the impact.
The latency improvements measured within the Redpanda broker were the most dramatic part of the change. All percentile levels experienced at least a 2-3x improvement, if not an order of magnitude, by the third configuration change. Even tail latencies had a modest improvement.

As effective batch size improves, the overall batches per second rate directly show up as CPU utilization improvements. You can see how incremental changes can drop resource usage enough to give breathing room. When reviewed in context with these other graphs, you see the connection between config changes and fuller impact to the system.

This is another view of the CPU utilization. We use this heatmap style to get a better feel for the evenness of usage across cores and pick out hot spots to investigate. You can see the dramatic CPU drop-off more clearly here.

This indicates a high volume of batches per second in several high-volume topics. This is inversely related to the average effective batch size. The larger the effective batch size, the lower this rate will go.

While reviewing this average on the cluster as a whole is directionally helpful, digging into each topic can identify poor performance with particularly expensive, high-volume topics. Tuning client linger.ms and batch.size will directly show up here. You can also see where the 4 KB crossover occurs to help reduce NVME write amplification.

The primary queue backlog was for the "main" tasks, where produce requests are handled inside the broker. The higher this line, the more contention there is for tasks requiring work to be accomplished. Ideally, we want this as low as possible. This tends to correlate with request volume when CPU is saturated.

One unexpected result of this change was a reduced network bandwidth required to handle the full flow of messages to this cluster. After we completed the effective batch size improvements, we went from requiring about 1.1 GB/sec of bandwidth to handle 1.2 million messages per second to about 575 MB/sec of bandwidth. We believe a combination of improved compression of the payloads, as well as a reduction of various Kafka metadata overhead, contributed to this.
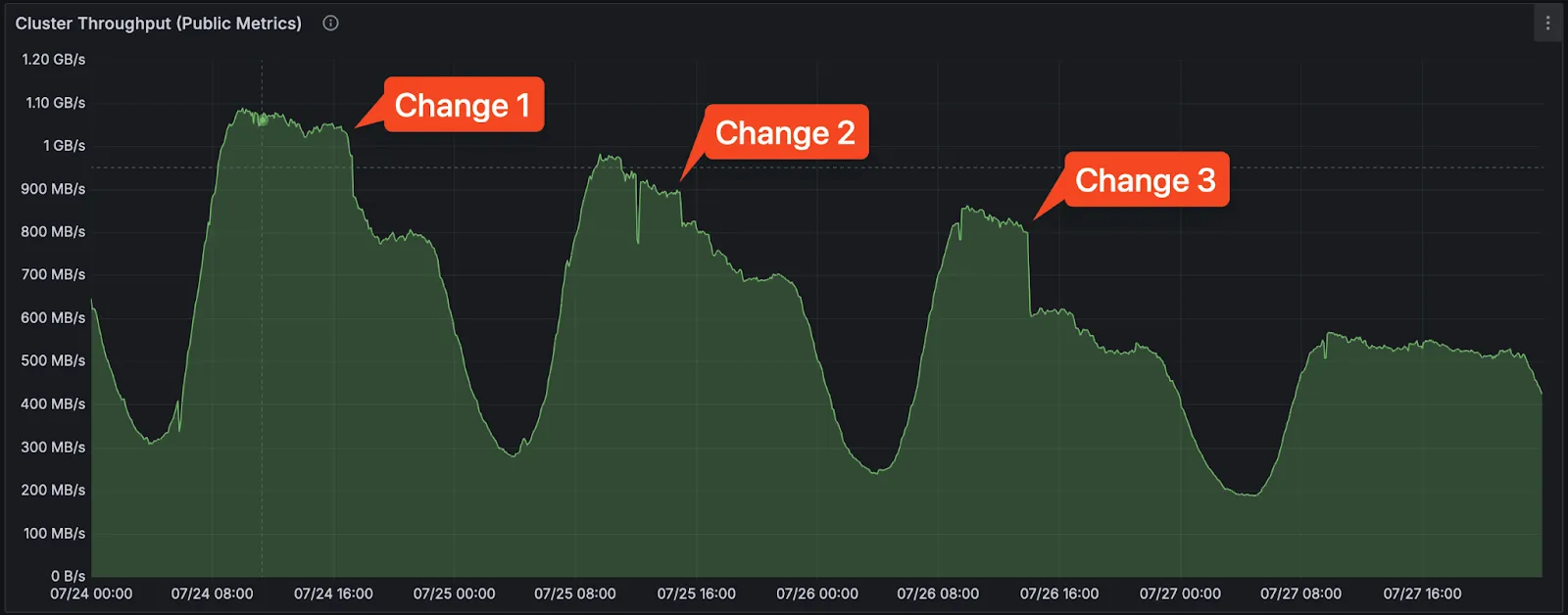
Once we validated that the effective batch size could be improved and that it rendered sizable reductions in resource utilization, we realized we might be able to gain one further improvement: collapsing the full data flow in this region from two clusters to one. Remember, because of the original CPU utilization issues, we could only place 50% of the flow on each cluster. We had now opened up capacity in two dimensions: CPU and network capacity.
The final test included between 2.5 and 2.7 million messages per second. We observed an additional increase in effective batch size because the producers sent twice the original flow to a single cluster. The full flow now only takes 1 GB/sec of network bandwidth with CPU utilization hovering around 50% — with capacity to spare for use by other features like Redpanda data transforms or the Apache Iceberg integration.
In this two-part series, we’ve seen the multifold impacts of raising the effective batch size: reduced load on the cluster, resulting in better performance (increased usable throughput, lower tail latencies) and better efficiency (lower infrastructure and network transfer costs).
We’ve seen how to configure batching, what factors affect batch size, and how to use observability metrics to pinpoint where a batch size problem may exist, allowing application designers and cluster administrators to get the very best performance from Redpanda.
To read more about batch tuning, browse our Docs. Have questions? Ask away in the Redpanda Community on Slack.
Subscribe to our VIP (very important panda) mailing list to pounce on the latest blogs, surprise announcements, and community events!
Opt out anytime.

