




Bridge Queries in Redpanda SQL
Have your real-time cake and eat your analytics too
A single, multi-modal engine









Redpanda Cloud Topics introduces a new replication path into Redpanda through object storage. Instead of replicating all data across availability zones (AZ), the application data from Kafka clients is sent directly to cloud storage, incurring no additional costs. Developers can switch a low-latency topic to a cloud-latency topic with a single command.
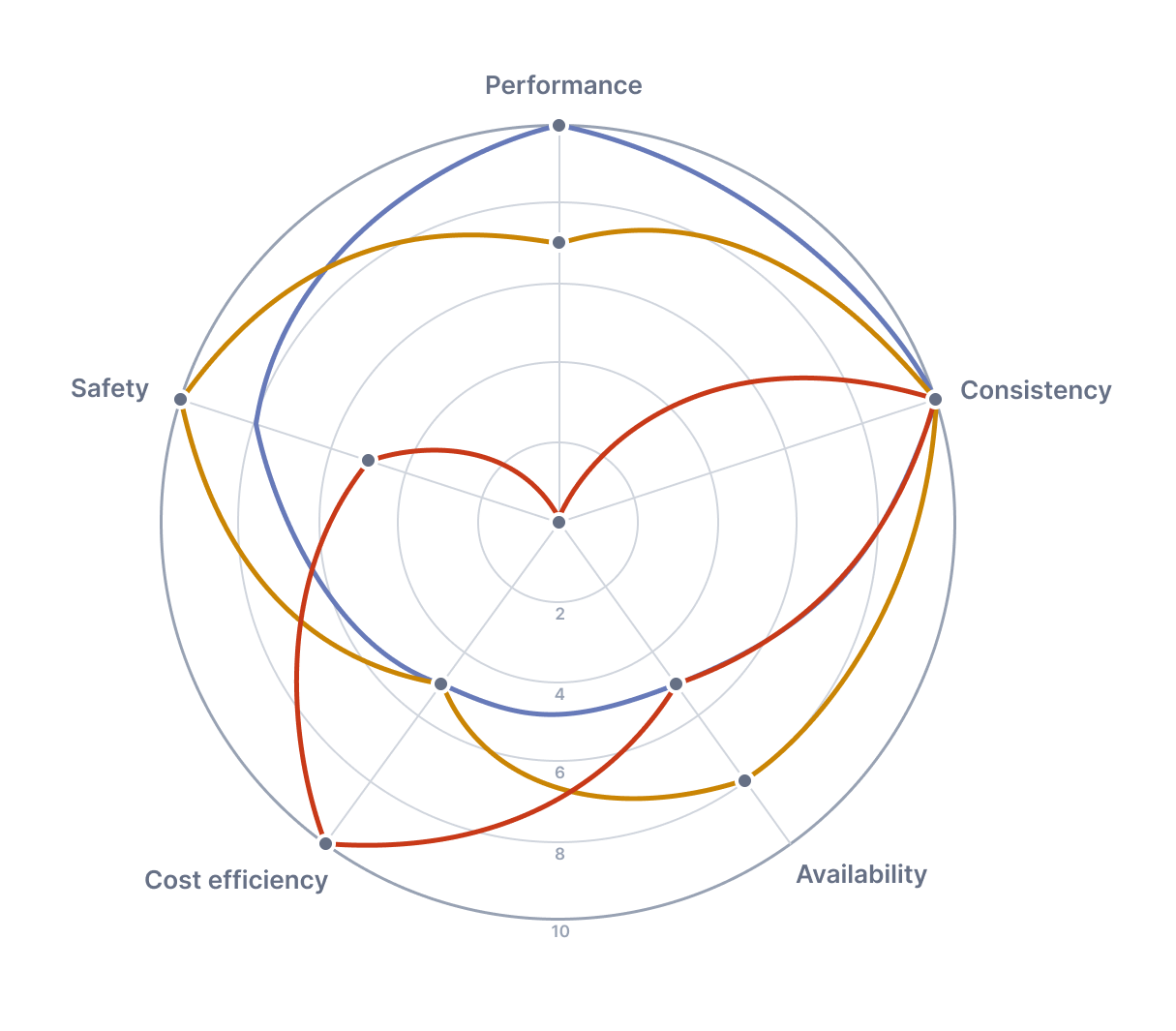
Redpanda One, or R1, is an upcoming engine from Redpanda that represents five years of work and their vision for the future. It offers developers the tools to dynamically choose between availability, consistency, latency, safety, and networking costs as pillars for engineering data-intensive apps, and to change these parameters mid-flight.
Bring-Your-Own-Cloud (BYOC) in Redpanda is an innovative deployment model that combines managed service benefits with complete data control and sovereignty. With BYOC, Redpanda clusters run entirely within your own cloud account (AWS, GCP, or Azure) while Redpanda manages the operational aspects remotely. Your data never leaves your environment, maintaining compliance with strict data residency and security requirements. Redpanda handles cluster deployment, configuration, monitoring, upgrades, and troubleshooting through a secure control plane connection. This model allows you to leverage existing cloud credits, committed use discounts, and enterprise agreements while maintaining your security policies, VPC configurations, and compliance certifications. BYOC provides the operational simplicity of a fully-managed service without sacrificing control over your infrastructure. You retain access to all cloud-native features, can integrate with existing tools, and maintain your network security boundaries. It's ideal for organizations with regulatory requirements (GDPR, HIPAA), specific security mandates, or existing cloud infrastructure investments. BYOC delivers enterprise-grade streaming with reduced operational burden while ensuring data sovereignty and compliance.
Apache Iceberg plays a crucial role in Redpanda's R1 by providing topic-level integration. This guarantees completeness (all the data exists) and correctness (the data exists in the exact ordering it was produced), with the ability to bring in the largest number of massively parallel databases for querying petabyte-scale data in seconds.
Redpanda's upcoming engine, R1, introduces a new multimodal streaming data engine that gives engineers the ultimate flexibility to choose how their data is stored per topic. This is a significant shift from traditional methods, allowing for more tailored and efficient data storage solutions.
Sometimes, you’re lucky enough to invent the future. Frankly, that future will not be about debating the technical nuances of streaming vs. batch. It will be about creating the simplest possible way to build data-intensive applications.
What originally got me to build Redpanda was being nerd-sniped into building what I wanted to use myself — a simple, easy-to-use, cost-effective drop-in Kafka replacement designed with developers in mind. Those ideas resonated with friends and, in turn, companies that probably transported you to work today, cleared your paycheck, or protected whitehouse.gov from last night’s attack.
The duality of representing an Append Only Table as a Schematized, Append Only Logs shifted data engineers' reasoning about systems into control plane databases. It doesn’t take much squinting to view Salesforce as a sophisticated, control-plane database. Most businesses are or will be.
And yet, what has actually shifted in the last year is our ability to represent row-oriented data, projected into cheap, high-throughput object storage systems in a columnar format. Query engines can skip over petabytes of data due to indexing and return results that would be only possible with a secondary copy. The second important shift was to offer a high latency (five seconds tail), extremely cost-effective, write-through segments into cloud object stores like Amazon S3 for infrequently access, dumb-but-important-pipe commonly used for observability style use cases. The third was to offer ultra-low latency (500 microseconds) and predictable performance for operational, mission-critical use cases.
Redpanda One — R1 — is our upcoming engine representing the culmination of five years of work and our vision for the future. It gives the developer the tools to dynamically choose (per table-topic) between availability, consistency, latency, safety, and networking costs as pillars for engineering data-intensive apps, and to change them mid-flight.
Redpanda has always thrived in large-scale operational use cases, especially when used for mission-critical systems. If your company stops making money when Apache Kafka® is down, that’s our best fit. Undoubtedly, we are simply the fastest engine in the world for the Kafka API. A core competency has always been the ability to deliver fast, reliable software in the presence of a cantankerous world with unreliable computers, networks, switches, and disks.
Large files aggregated over multiple partitions, all in memory, with synthetic delays for client acknowledgments with asynchronous compaction, server critical infrastructure common in observability use cases.
We’re beyond excited to share a sneak preview of our upcoming engine called R1. This new multimodal streaming data engine will give engineers the ultimate flexibility to choose how their data is stored per topic.
Redpanda Cloud Topics introduces a new replication path into Redpanda through object storage. Rather than replicating all data across availability zones (AZ), the application data from Kafka clients is sent directly to cloud storage, incurring no additional costs.
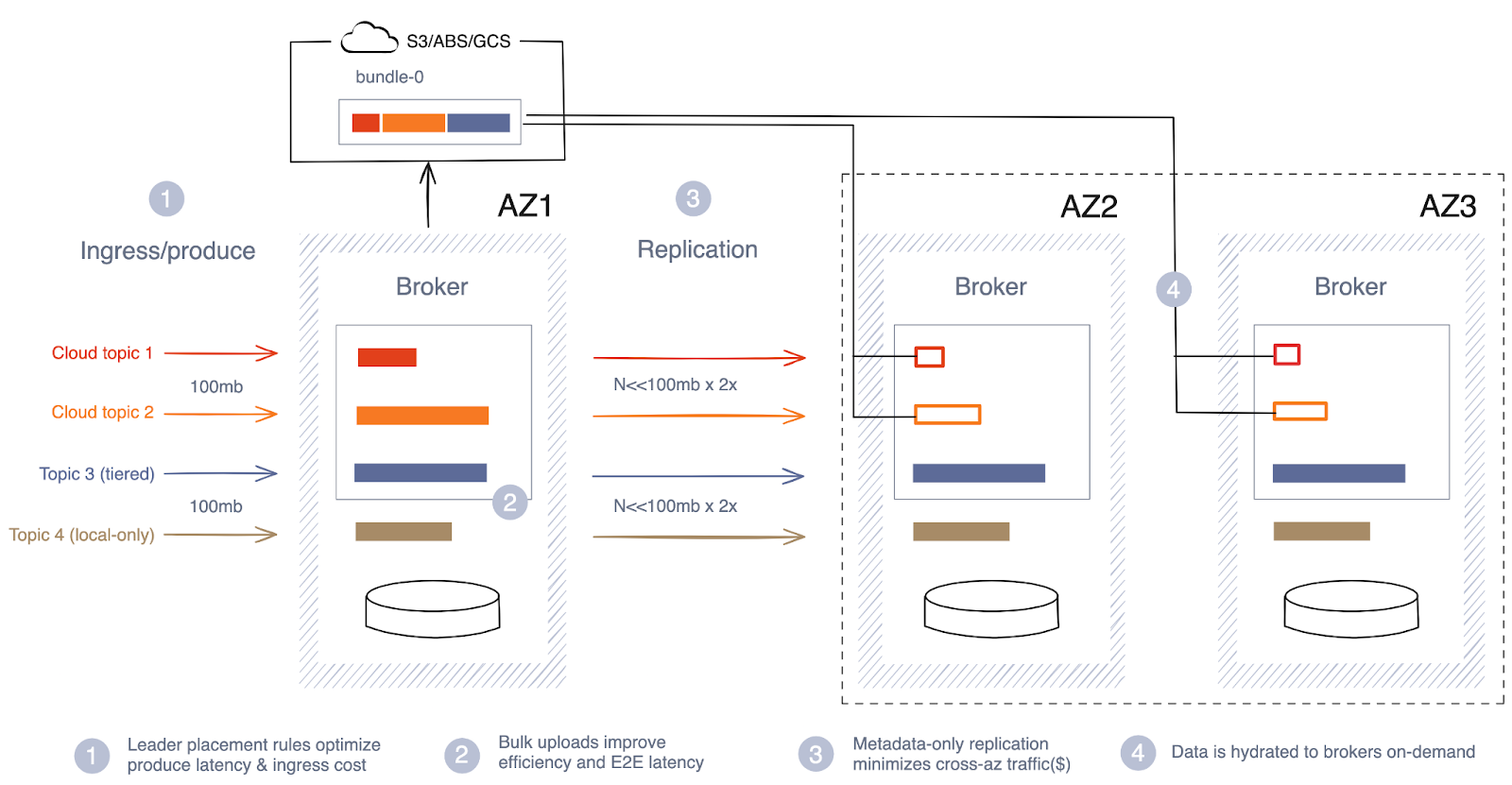
Developers can flip the switch to make the low-latency topic a cloud-latency topic with a single command.
rpk topic create my-topic -c redpanda.cloud_topic=true
The common understanding that most SaaS businesses are just wrappers on cloud object stores, like S3, isn’t entirely misinformed. We’re all doing our best with the resources at hand, and S3 stretches the dollars. S3 is so popular that most major clouds support the same API for accessing data. It’s also a marvel of engineering, delivering cost efficiencies that are simply hard to beat.
The challenge is that it’s very slow. A single object write can take multiple seconds, and in messaging systems these latencies are the norm. The ability to dynamically choose your latency target per topic is a way of eliminating the old-school debate of batch vs. streaming data access. You’ll need both. Batch for seamless backfill/catch up where you can leverage multi-gigabytes per second, massively parallel fetch strategies with vectorization engines, and seamless handoff to the tailing iterator for interactivity.
Topic-level integration with Iceberg guarantees completeness (all the data exists) and correctness (the data exists in the exact ordering it was produced), with the ability to bring in the largest number of massively parallel databases for querying petabyte-scale data in seconds. Zero-shot integration from stream to SQL.

The recent moment of clarity we’ve had as an industry to settle on open formats for data at rest proved that it was never a technical problem — it was a cultural artifact. What enables this “unification” of access is the ability to schematize what used to be a bag of bytes into a high-level construct, which can be enforced on the server side with common formats that engineers are already familiar with, like Protobuf, Avro, JSON, etc.

The longest pole will always be data integration because a human always has to approve some sort of Jira ticket. Today, we announced the largest connectivity portfolio for the Kafka API via Redpanda Connect with over 260 connectors, including most major databases and systems of record.
Connectivity is not just about enriching your data or a nice to have, it’s how you deliver end-user value. The only thing that matters is happy users (in production). Your users don’t see or care about the how, only the what, and neither should you. There’s no real intellectual property in writing the 100,001 integration with the salesforce API. You’re also the N-millionth human to have integrated S3. This is a long, tedious, detail-oriented tail of connectors that make the clock tick. Most of it is permissively licensed open-source too, if that’s your vibe.
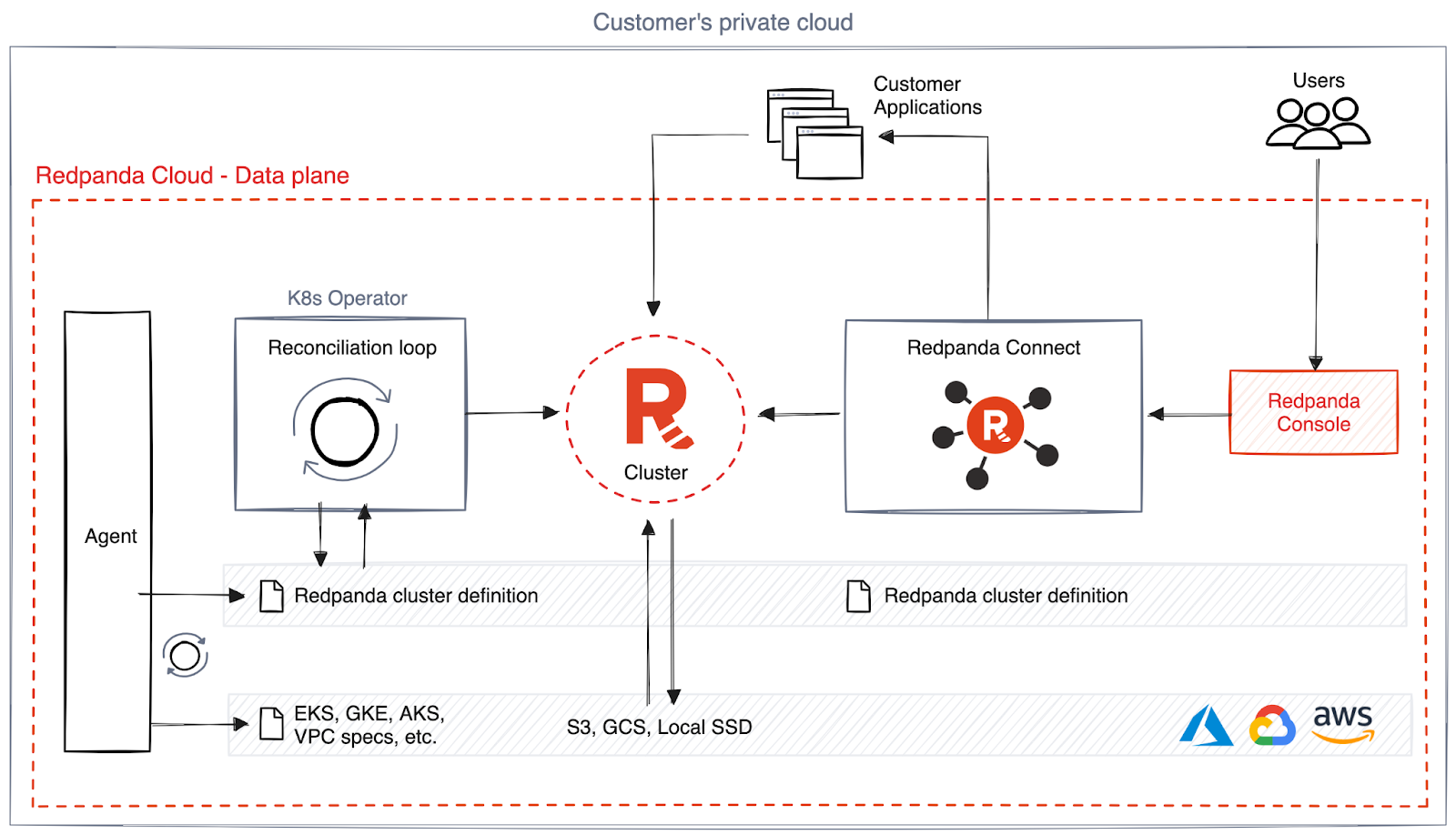
As I wrote in my previous post about data atomicity in BYOC, culturally, Redpanda has always tackled the hard things first. We started building a new storage engine from scratch without virtual memory or primitives, like the page cache to accelerate write-behind workloads. Using a network of Single-Producer-Single-Consumer (SPSC) queues to eliminate CPU cache pollution, all the way to implementing our own S3 client from scratch for performance and making sure it integrated with our own memory allocator.
New cloud primitives allowed us to invent a new way to deliver software, which we called Bring-Your-Own-Cloud (BYOC), a fully managed service hosted on your own cloud account. In simple words, it’s the separation of control and data planes, where the control plane is cloud.redpanda.com and the data plane lives inside your network. We coined BYOC as a new word to describe a new architectural primitive: data plane atomicity, an agent-based security model, and a user-owned data model that did not exist when we built it.
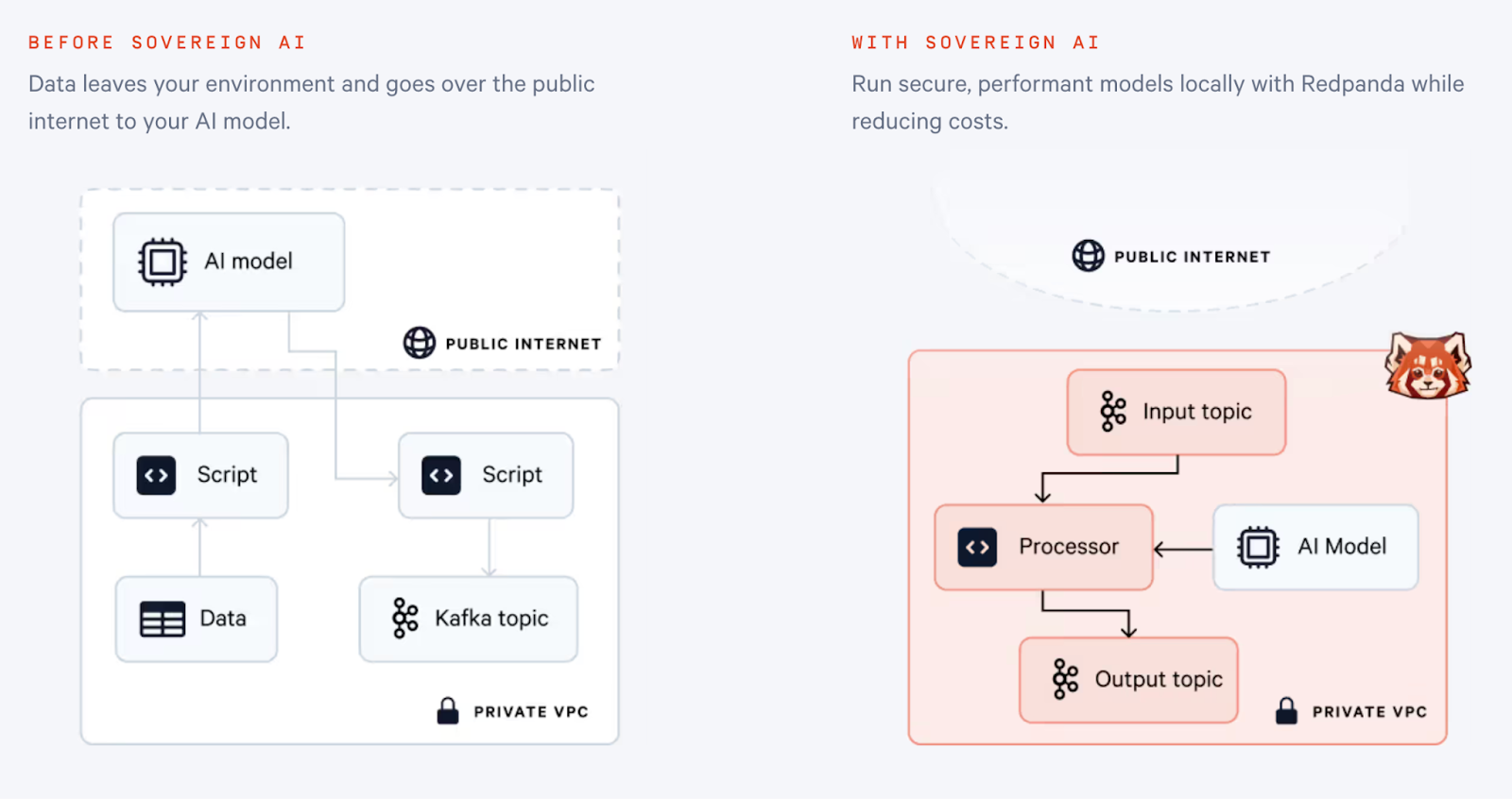
The world wants to build magical user experiences with transformative tech like LLMs but is stuck in figuring out how to secure, trust, and understand it. The bottleneck is not in the performance of state-of-the-art models, which are in the same category as the best-closed source models, nor in your business's data — but in the bundling of the CUDA libraries, GPU acceleration drivers, authentication, authorization, and mechanics that block adoption.
On the shoulders of BYOC stands our vision for AI: private, traceable, and secure. We launched the ability to deploy state-of-the-art open weights and open-source models in your cloud without data ever leaving your network.
I’m beyond energized to share this vision with you. We couldn’t be here without you, partnering with us along the way and helping us tweak and iterate daily. Five years in, and it still feels like we’ve only just started.
If you want to learn more about R1, get in touch.
Subscribe to our VIP (very important panda) mailing list to pounce on the latest blogs, surprise announcements, and community events!
Opt out anytime.

