





Full CDC semantics land in the Iceberg output for Redpanda Connect
Your lakehouse mirrors the database, instantly.
Build your own time series data stream to detect anomalies in a payment system using TimescaleDB, Kafka Connect, and Redpanda.








To set up a time series data stream application for monitoring payments, you need to stream payment time series data into Redpanda and use a Kafka Connect instance to sink the streaming data into TimescaleDB for analysis. This requires setting up a Redpanda cluster and TimescaleDB on Docker containers, creating a dedicated Docker network, and initializing the database with expected columns from the Redpanda messages. You also need to set up Kafka Connect and create connection properties files for both Redpanda and TimescaleDB.
A time series database is a database optimized for time series data, which represents changes in a system, process, or behavior over time. It's used for applications like Internet of Things (IoT) data monitoring, real-time weather forecasting, and detecting anomalies in payment systems. It allows for the monitoring and analysis of data from different sources in real time, providing powerful predictions and efficient querying of high volumes of continuous data.
Kafka Connect is used to create a data stream sink from Redpanda to TimescaleDB. It is set up in a Docker container with a customized Dockerfile. Kafka Connect requires a set of Java libraries and a few configuration files to create sink connections. Connection properties files are needed for both Redpanda and TimescaleDB to set up the connection between them.
Redpanda is used in setting up a time series data stream application. It is set up on a Docker container, and its service is started with specific configuration parameters. A single-node Redpanda cluster is created in the network, and its Kafka API is reachable for the application. A topic is created in Redpanda for sending and receiving the streaming data in a logical order.
TimescaleDB is a common solution for time series databases. It expands PostgreSQL for faster time series query performance and is known for its efficiency. TimescaleDB implements time-series compression algorithms to enhance query and storage performance. It supports multi-node deployment with horizontal scalability and chunks the time series data in small intervals, making the most recent data more performant for inserts and queries.
Streaming data is a continuous flow of data, often produced by different sources and then ingested into a data store for analysis. Time series data is a type of streaming data that represents the changes in a system, process, or behavior over time. It’s widely used for analyzing and monitoring systems, behavior, and processes.
In short: a time series database is simply a database optimized for time series data. You might use one for applications like:
A common solution for time series databases is TimescaleDB. It expands PostgreSQL for faster time series query performance and is well-known for its efficiency. TimescaleDB implements time-series compression algorithms to enhance query and storage performance. It supports multi-node deployment with horizontal scalability. It also chunks the time series data in small intervals so the most recent data is more performant for inserts and queries. For more information on TimescaleDB’s core features, check their documentation page.
Let’s take a look at a sample architecture integrating Redpanda with TimescaleDB, so you can see step-by-step how to build your own time series data stream.
Imagine you’re working with a payment system. Payment information flows continuously between agents, so it’s critical for a payment system provider to detect anomalies in their system, like fraud.
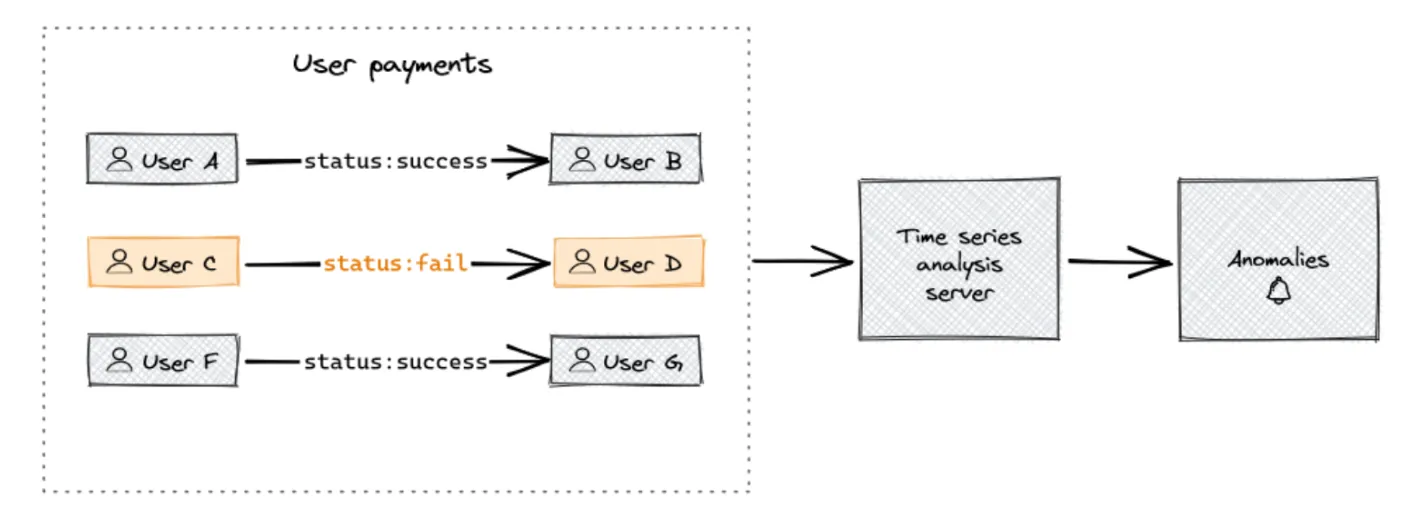
Use case diagram
Your goal is to stream payment time series data into Redpanda and use a Kafka Connect instance to sink the streaming data into TimescaleDB, where you can analyze the data for anomalies. Here's what the architecture for this solution looks like:
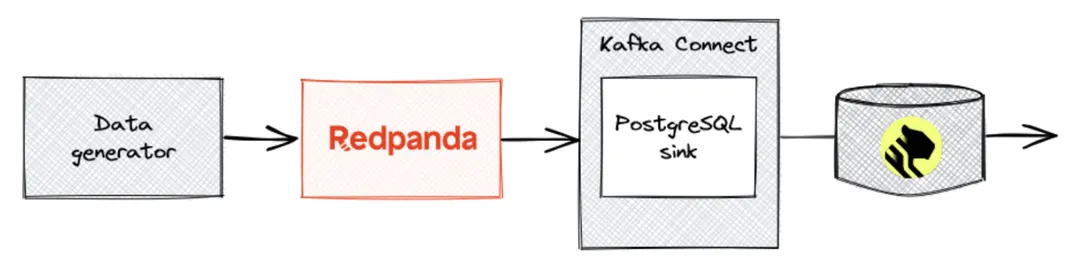
Architecture diagram
To follow this tutorial, you’ll need Docker installed. A time series streaming setup typically has multiple components: producers, consumers, and middleware to support sending and receiving the streaming messages. With Docker, you can simulate this multi-component setup.
To connect all the components together, you need a dedicated Docker network. You can create one with the following command:
docker network create -d bridge redpanda-timeseriesSetting up Redpanda on a Docker container first requires pulling the image. Start the Redpanda service with these configuration parameters:
At the time of this writing the latest version of Redpanda is v22.3.11. Hence the tutorial uses this version.
The following command should create a single-node Redpanda cluster in the redpanda-timeseries network. You should be able to reach this Redpanda instance’s Kafka API at redpanda:9092.
docker run -d --name=redpanda --rm \
--network redpanda-timeseries \
-p 9092:9092 \
-p 9644:9644 \
docker.vectorized.io/vectorized/redpanda:v22.3.11 \
redpanda start \
--advertise-kafka-addr redpanda \
--overprovisioned \
--smp 1 \
--memory 1G \
--reserve-memory 500M \
--node-id 0 \
--check=falseNote that running Redpanda directly via Docker isn’t recommended in production and you should use a container orchestration engine like Kubernetes. But a Docker-based setup works fine for local development and testing.
Go into redpanda and try out a few rpk commands. rpk stands for Redpanda Keeper, and it is a command-line interface utility that Redpanda provides. To check the service status:
docker exec -it redpanda rpk cluster infoThis should give the following output:
CLUSTER
=======
redpanda.92c9ba41-860e-4c07-a3a3-7a7a3eb2d286
BROKERS
=======
ID HOST PORT
0* redpanda 9092To create a topic called mock-payments:
rpk topic create mock-paymentsThe topic you just created in this step will be used for sending and receiving the streaming data in a logical order.
To set up TimescaleDB on a Docker container, pull the image.
This tutorial uses the Highly Available image, which includes PostgreSQL 14 and TimescaleDB Toolkit. If you want a full cloud experience you could also use Timescale to host your database, which you can try for free for 30 days. Once you’ve spun up an instance you can skip to creating your schema.
Start the TimescaleDB container with these configuration parameters:
docker run --name timescaledb --rm \
--network redpanda-timeseries \
-v ./tools/timescaledb/:/docker-entrypoint-initdb.d/ \
-p 5432:5432 \
-e POSTGRES_PASSWORD=pass1234 \
-e POSTGRES_USER=timescaledb \
timescale/timescaledb-ha:pg14-latestNote the volume mount parameter in the configuration. This is for mounting scripts in the Docker container. As you mount the scripts, you can use those to initialize the database, so you can create your schema and tables.
You can insert the initializing script(s) into the ./tools/timscaledb path in your local environment. This path is going to be mounted into the /docker-entrypoint-initdb.d/ path in the TimescaleDB container.
The initializing script creates a table with expected columns coming from the Redpanda messages. You also need to activate the timescaledb extension, as in this sample SQL script:
# Creating the schema in the 'timescaledb' database
CREATE SCHEMA IF NOT EXISTS mock_data;
CREATE EXTENSION IF NOT EXISTS timescaledb CASCADE;
# DDL for table creation - includes the columns for expected fields
# in messages to be produced in Redpanda
CREATE TABLE IF NOT EXISTS mock_data.peer_payouts
(
payment_timestamp TIMESTAMP WITH TIME ZONE NOT NULL,
amount DOUBLE PRECISION NOT NULL,
status VARCHAR(10) NOT NULL,
currency_code VARCHAR(10) NOT NULL,
sender VARCHAR(50) NOT NULL,
recipient VARCHAR(50) NOT NULL,
_loaded_at TIMESTAMPTZ DEFAULT NOW()
);
# Creates a hyper table for benefiting from time series functionalities.
SELECT create_hypertable('mock_data.peer_payouts', 'payment_timestamp');Since Redpanda is compatible with Kafka API endpoints, you can use Kafka Connect to create a data stream sink from Redpanda to TimescaleDB.
To create a Kafka connect component in Docker, you can create a customized Dockerfile, such as:
FROM openjdk:21-jdk-slim-buster
ENV KAFKA_TAG=2.13-3.1.0
ENV KAFKA_VERSION=3.1.0
ENV POSTGRES_DRIVER=https://repo1.maven.org/maven2/org/postgresql/postgresql/42.4.3/postgresql-42.4.3.jar
ENV POSTGRES_CONNECTOR=https://repo1.maven.org/maven2/org/apache/camel/kafkaconnector/camel-postgresql-sink-kafka-connector/3.18.2/camel-postgresql-sink-kafka-connector-3.18.2-package.tar.gz
RUN mkdir /integrations /integrations/connectors
# Install cURL
RUN apt-get update && apt install -y curl
# Install Kafka Connect
RUN curl -o /integrations/kafka.tgz https://archive.apache.org/dist/kafka/${KAFKA_VERSION}/kafka_${KAFKA_TAG}.tgz && \
tar zxvf /integrations/kafka.tgz -C /integrations/ && \
mv /integrations/kafka_${KAFKA_TAG} /integrations/kafka-src && \
rm -rf /integrations/kafka.tgz
# Download PostgreSQL driver jar
RUN curl -o /integrations/connectors/postgresql-driver.jar ${POSTGRES_DRIVER}
# Download PostgreSQL Connector dependencies
RUN curl -o /integrations/connectors/postgresql-connector.tar.gz ${POSTGRES_CONNECTOR}
RUN tar zxvf /integrations/connectors/postgresql-connector.tar.gz -C /integrations/connectors/ && \
rm -rf /integrations/connectors/postgresql-connector.tar.gz && \
mv /integrations/connectors/postgresql-driver.jar /integrations/connectors/camel-postgresql-sink-kafka-connector/
COPY ./tools/kafka_connect/integrations/configuration /integrations/configuration
COPY ./tools/kafka_connect/scripts/start_connector.sh /integrations/scripts/start_connector.sh
CMD ["bash", "/integrations/scripts/start_connector.sh"]The following paragraphs will be explaining the important lines in this Dockerfile. So that you can follow and change any necessary parts to experiment in your own setup.
With a few configuration files, Kafka Connect creates sink connections. However, you do need to install a custom set of Java libraries. Use a separate Dockerfile with a base image that has Java Development Kit (JDK) and curl components.
Choose openjdk:21-jdk-slim-buster and install curl in it:
FROM openjdk:21-jdk-slim-buster
FROM openjdk:21-jdk-slim-buster
# Install curl
RUN apt-get update && apt install -y curlTo get Kafka Connect, download the Apache Kafka package and click the suggested download link for the Kafka 3.1.0 binary package. Once you have the link for the tgz file, you can add the following lines in your Dockerfile.
# Install Kafka Connect
RUN curl -o /integrations/kafka.tgz https://archive.apache.org/dist/kafka/3.1.0/kafka_2.13-3.1.0.tgz && \
tar zxvf /integrations/kafka.tgz -C /integrations/ && \
mv /integrations/kafka_2.13-3.1.0 /integrations/kafka-src && \
rm -rf /integrations/kafka.tgzHaving a structure in the Docker container folders is helpful when you’re working with more than one configuration file. I recommend you rename the downloaded contents and move them to a folder structure.
The example commands in this tutorial have the following folder structure in the Kafka Connect Docker container:
|-- integrations
| |-- configuration
| | |-- connect-standalone.properties
| | `-- sink-connector.properties
| |-- connectors
| `-- kafka-srcTo set up a connection between Redpanda and TimescaleDB, you need one connection properties file for each technology, as follows.
Connect Properties
This file provides a set of mandatory parameters to recognize the Redpanda instance and its possible message converters. Also, it has a plugin.path, an important parameter for preloading any Kafka connector plugins.
In the tutorial, the mock data stream is structured with a string key and a payload. The payload is serialized as binary. Keeping the structure of the streamed messages, prepare the properties file as follows:
plugin.path=<plugins-path>
key.converter=org.apache.kafka.connect.storage.StringConverter
value.converter=org.apache.kafka.connect.converters.ByteArrayConverter
key.converter.schemas.enable=false
value.converter.schemas.enable=false
bootstrap.servers=<redpanda-bootstrap-server>
offset.storage.file.filename=/tmp/connect.offsets
offset.flush.interval.ms=10000The external Kafka API addresses of the broker's nodes refer to the bootstrap.servers property. The external Kafka API address of the broker is set as redpanda:9092 in the previous section and has only one node. For this tutorial, you can fill the plugin and redpanda properties yourself in the properties file setup with the following values:
plugin.path/integrations/connectorsbootstrap.serversredpanda:9292
PostgreSQL Sink Properties
This file provides the details of a data flow from a given Kafka broker connection to a PostgreSQL database.
The Apache Camel PostgreSQL Sink Connector is a practical choice when defining a sink to TimescaleDB. It’s a PostgreSQL based database and supports PostgreSQL connections. Under the hood, Camel PostgreSQL Sink Connector uses Camel JDBC Sink Connector, Java PostgreSQL Driver, and other Java dependencies.
To install this into the Kafka Connector, download and extract those compiled dependencies into your plugin path in the Dockerfile (the path that you set in your Connect Properties). Add the following lines in your Dockerfile:
ENV POSTGRES_DRIVER=https://repo1.maven.org/maven2/org/postgresql/postgresql/42.4.3/postgresql-42.4.3.jar
ENV POSTGRES_CONNECTOR=https://repo1.maven.org/maven2/org/apache/camel/kafkaconnector/camel-postgresql-sink-kafka-connector/3.18.2/camel-postgresql-sink-kafka-connector-3.18.2-package.tar.gz
# Download PostgreSQL Driver Jar
RUN curl -o /integrations/connectors/postgresql-driver.jar ${POSTGRES_DRIVER}
# Download PostgreSQLl Connector dependencies
RUN curl -o /integrations/connectors/postgresql-connector.tar.gz ${POSTGRES_CONNECTOR}
RUN tar zxvf /integrations/connectors/postgresql-connector.tar.gz -C /integrations/connectors/ && \
rm -rf /integrations/connectors/postgresql-connector.tar.gz && \
mv /integrations/connectors/postgresql-driver.jar /integrations/connectors/camel-postgresql-sink-kafka-connector/
# Make sure that the created configurations are copied into the /integrations/configuration path
COPY ./tools/kafka_connect/integrations/configuration/sink-connector.properties /integrations/configuration/sink-connector.properties
COPY ./tools/kafka_connect/integrations/configuration/connect-standalone.properties /integrations/configuration/connect-standalone.propertiesAfter setting up the environment for the Camel PostgreSQL Sink, prepare the properties file. You’ll use this file later when initializing the standalone connection. The properties contain:
name=camel-postgresql-sink-connector
connector.class=org.apache.camel.kafkaconnector.postgresqlsink.CamelPostgresqlsinkSinkConnector
key.converter=org.apache.kafka.connect.storage.StringConverter
value.converter=org.apache.kafka.connect.converters.ByteArrayConverter
key.converter.schemas.enable=false
value.converter.schemas.enable=false
topics=mock-payments
camel.kamelet.postgresql-sink.serverName=<server-name>
camel.kamelet.postgresql-sink.username=<user-name>
camel.kamelet.postgresql-sink.password=<password>
camel.kamelet.postgresql-sink.query=<sink-query>
camel.kamelet.postgresql-sink.databaseName=<database-name>For this tutorial, you can fill the postgresql sink properties yourself in the Docker setup with the following values:
camel.kamelet.postgresql-sink.serverNametimescaledbcamel.kamelet.postgresql-sink.username< username-set-in-docker-compose >camel.kamelet.postgresql-sink.password< password-set-in-docker-compose >camel.kamelet.postgresql-sink.databaseNametimescaledb
The sink query (camel.kamelet.postgresql-sink.query) syntax allows you to perform data casting. It’s an insert statement referring to the fields of the JSON messages inserted previously in Redpanda. In the place of <sink-query>, writer a one liner of the following insert statement:
INSERT INTO mock_data.peer_payouts (
payment_timestamp,
amount,
status,
currency_code,
sender,
recipient
)
VALUES (
TO_TIMESTAMP(:#timestamp),
:#amount,
:#status,
:#currency,
:#sender_nickname,
:#recipient_nickname
)Once you have your .properties files and the Dockerfile, you can start building your Kafka Connect image with the following command.
docker build -t kafka_connect -f ./tools/kafka_connect/DockerfileThis command assumes that your Dockerfile is located in the relative path ./tools/kafka_connect/Dockerfile.
The tutorial provides a data generator to make the creation of streaming data easier. This public Docker image, nandercc/random-data-generator, includes a CLI tool that generates random payment JSON objects.
Once you have Redpanda, TimescaleDB, and Kafka Connect configured and their containers running on your machine, you can start producing messages with a mock data producer. The following code should start producing random payout information into the Redpanda mock-payments topic for 300 seconds.
docker run --name data-generator --rm \
--network redpanda-timeseries \
nandercc/random-data-generator \
data-producer payouts \
--server redpanda:9092 \
--topic mock-payments \
--timeout 300The messages should be logged on your terminal as:
2023-01-14 18:04:17,485 INFO [random_data_generator.cli] [cli.py:23] Payment data is sent: {"id": "bdd6cae3-1b97-4933-bca5-b90fac9856a8", "timestamp": 1673719457.4834366, "amount": 89.11, "status": "success", "currency": "EUR", "sender_nickname": "tiffanyaguirre", "recipient_nickname": "ljenkins"}
2023-01-14 18:04:18,598 INFO [random_data_generator.cli] [cli.py:23] Payment data is sent: {"id": "9dc21c23-c0c3-434a-bc8a-3d75c2a399ad", "timestamp": 1673719458.5967793, "amount": 20.61, "status": "success", "currency": "EUR", "sender_nickname": "sbennett", "recipient_nickname": "katherine64"}
2023-01-14 18:04:18,598 INFO [random_data_generator.cli] [cli.py:23] Payment data is sent: {"id": "9dc21c23-c0c3-434a-bc8a-3d75c2a399ad", "timestamp": 1673719458.5967793, "amount": 20.61, "status": "success", "currency": "EUR", "sender_nickname": "sbennett", "recipient_nickname": "katherine64"}So far, you’ve created a relevant Redpanda topic and TimescaleDB tables, and then you began producing messages into the Redpanda topic. With this setup running, you can call the Kafka Connect standalone script to connect the given Redpanda instance and topic with the given PostgreSQL sink path.
docker run -d --name kafka_connect --rm \
--network redpanda-timeseries \
kafka_connect:latest \
bash integrations/kafka-src/bin/connect-standalone.sh \
integrations/configuration/connect-standalone.properties \
integrations/configuration/sink-connector.propertiesYou can get into the TimescaleDB table to check out some example queries with the following command:
docker exec -it timescaledb psql -h localhost -d timescaledb -U timescaledbSelect the EUR currency payments within the last five minutes:
SELECT * FROM mock_data.peer_payouts
WHERE currency_code = 'EUR' AND payment_timestamp >= NOW() - INTERVAL '5 seconds'
ORDER BY payment_timestamp;The output looks like:
payment_timestamp | amount | status | currency_code | sender | recipient | _loaded_at
-------------------------------+--------+---------+---------------+--------------+-----------+-------------------------------
2022-12-31 15:03:23.445194+00 | 18.55 | success | EUR | ryanruiz | sarah60 | 2022-12-31 15:03:23.477883+00
2022-12-31 15:03:25.496392+00 | 20.96 | success | EUR | joshuamoore | rmeza | 2022-12-31 15:03:25.516868+00
2022-12-31 15:03:27.532481+00 | 90.61 | success | EUR | coreyeverett | ivega | 2022-12-31 15:03:27.552709+00
(3 rows)You can try out the materialized views with continuous aggregations for monitoring failed payments with the following SQL command:
CREATE MATERIALIZED VIEW mock_data.peer_payouts_per_minute
WITH (timescaledb.continuous) AS
SELECT
time_bucket('5 minute', payment_timestamp) AS day,
status,
AVG(amount) AS mean_amount,
STDDEV(amount) AS std_amount,
MAX(amount) AS max_amount,
COUNT(1) AS frequency
FROM mock_data.peer_payouts pyt
WHERE status = 'fail'
GROUP BY day, status;The aggregations in the mock_data.peer_payouts_per_minute materialized view resemble the following table:
day | status | mean_amount | std_amount | max_amount | frequency
------------------------+--------+--------------------+--------------------+------------+-----------
2022-12-31 15:00:00+00 | fail | 19.685000000000002 | 1.9578738468042307 | 22.53 | 6
2022-12-31 15:05:00+00 | fail | 39.11575757575758 | 31.131611449447874 | 92.93 | 33
2022-12-31 15:10:00+00 | fail | 33.902000000000015 | 28.223191944381693 | 95.05 | 35
2022-12-31 15:15:00+00 | fail | 34.31379310344828 | 28.242435828502714 | 91.4 | 29
2022-12-31 15:20:00+00 | fail | 39.840454545454534 | 32.37680878966606 | 93.57 | 22mock_data.peer_payouts_per_minute will now be materialized as it enters the system, always providing a five minute aggregated view of your new data as it streams in.
Congratulations! You just built a time series data analysis system using Redpanda and TimescaleDB using Kafka Connect. That didn't take long at all.
With a time series data stream from Redpanda to TimescaleDB, you can create actionable, real-time applications in finance, IoT, and social media systems, just to name a few applications. Redpanda is compatible with Apache Kafka API, and TimescaleDB is PostgreSQL, so you have a good variety of programmatic and non-programmatic connection options already available.
You can access the resources for this tutorial in this GitHub repository, as well as Redpanda’s source-available code in this repo. If you have questions, join our Redpanda Community on Slack or pop into Timescale's Slack channel and ask away!
Subscribe to our VIP (very important panda) mailing list to pounce on the latest blogs, surprise announcements, and community events!
Opt out anytime.

