





Full CDC semantics land in the Iceberg output for Redpanda Connect
Your lakehouse mirrors the database, instantly.
Streaming data means using the latest data to make timely business decisions. Here’s how we how we built a streaming data pipeline in SQL using Upsolver SQLake and Redpanda.








In a nutshell: batch data processing is slow and expensive. It requires loading data into the data warehouse before preparing and transforming the data for analysis, which delays data-driven decisions and risks the data becoming obsolete. To make effective, timely, and impactful business decisions—you need fresh and accurate data. The most efficient way of achieving this is through stream processing.
In this post, you’ll learn how to build a streaming data pipeline in SQL using Upsolver SQLake and Redpanda.
What is the difference between streaming and batch data processing? Stream processing happens in real time (or near real time), where incoming events are continuously analyzed and reported on as data flows in. In contrast, batch processing happens on a group of events after a specified period of time, where incoming events are stored before they’re processed and analyzed.
Switching from batch to streaming might seem complicated, but they’re actually not all that different. You can think of each event (or a group of events) in a stream as a batch. Micro-batch event processing handles a group of events that arrive within a small window of time, like every minute, or when combined are of a certain batch size, like 4KB. So, batch processing is basically just an extension of micro-batch processing. If you can handle batch processing, then you can handle stream processing.
What’s more, with stream processing you can benefit from a more resource-efficient system that’s easier to scale. There are also significant business advantages in processing data as soon as it’s available, such as:
To gain these benefits, you should consider moving mission-critical jobs from batch to stream. Moving from batch processing to stream processing isn’t as difficult or complicated as you may think. The following diagram shows a simple streaming data architecture.
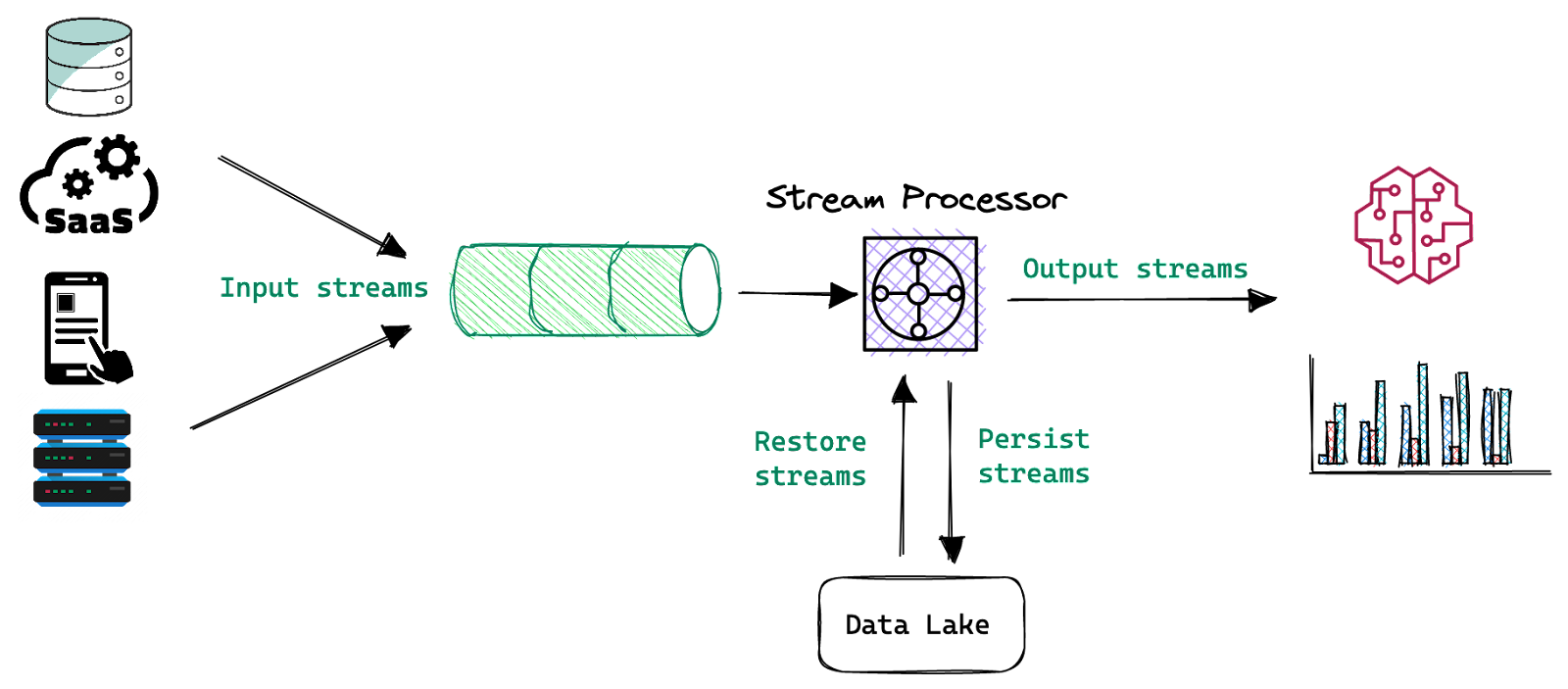
As shown above, the majority of your data sources are already producing data in a streaming manner. Writing these events into a message bus is a best practice, as it provides resiliency and high availability for your data streams.
Next is the stream processor, which allows you to build ETL jobs that prepare, transform and join datasets on the fly. Data is then written into a serving layer for analytics and machine learning, as well as to the data lake for long-term storage. The data lake enables you to integrate this data into more systems and tools, like offline feature extraction or model training. It’s also useful when you need to replay and reprocess historical data to enrich or correct it.
Estuary wrote a post on The Real-Time Data Landscape that provides a list of tools and vendors that plug into different parts of this architecture. It’s a good idea to review it for more context and options when implementing this yourself.
Two of the most critical components of a streaming architecture are the streaming bus and the stream processing engine.
Redpanda is a Kafka®-compatible, high-performance data streaming platform or bus. Written in C++, it's JVM-free, ZooKeeper®-free, making it simple to deploy and manage. It allows you to extract the best performance out of every core, disk, memory chip, and network byte—without sacrificing the reliability and durability of your data.
Upsolver SQLake is a unified batch and stream processing engine. It allows you to easily consume events from popular sources like Redpanda, Kinesis, S3, and PostgreSQL. You can:
Let's redraw the previous architecture diagram to reflect how Redpanda and SQLake fit into it.

With the ELT and ETL models, users are tasked with manually developing, testing, and maintaining the orchestration logic needed to support a reliable, consistent, and performant data pipeline. To minimize production failures and improve the reliability of your pipelines, you need to automate as much as possible and eliminate potential failure points.
Manual work, however, not only slows down business growth but also introduces numerous human errors that compound over time. These human errors will result in poor data quality, slow performance, high costs, and poor business outcomes.
In this section, we’ll walk through an example that demonstrates how to determine the last salesperson to fulfill an order in our store. The pipeline we’ll build performs two simple tasks:
Let’s get started.
There are many flavors of Redpanda—installed locally, running on top of Kubernetes, and available as a managed cloud service. Start by signing up for a free trial of Redpanda Cloud. Then, create a new cluster and you’ll see all the information you need to start streaming!
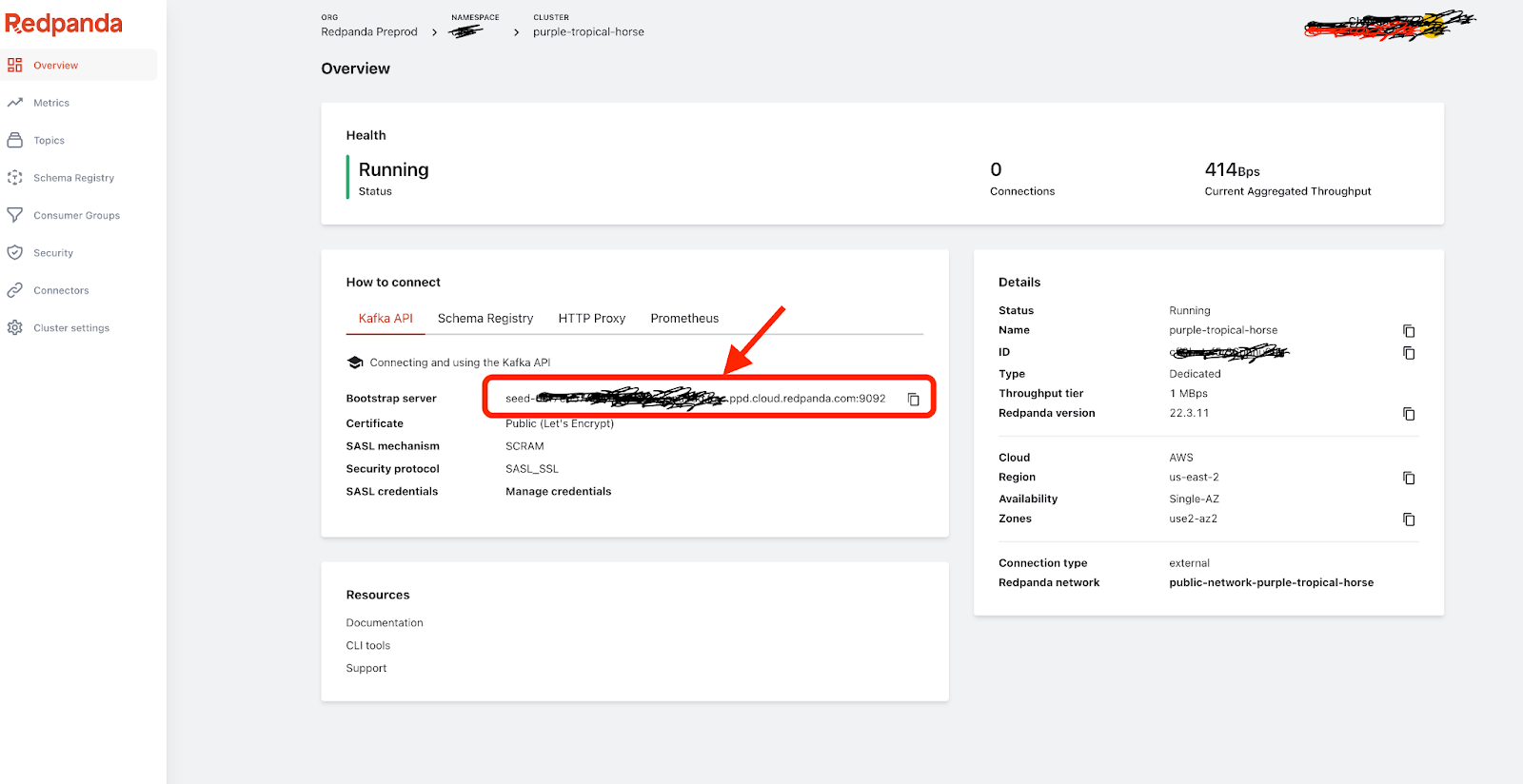
Use the Bootstrap server for the HOSTS property when configuring SQLake in the following step. Also, create a new user called demousr by clicking on the Security icon in the left menu.

And don’t forget to edit ACLs as shown below to enable demousr to access topics from SQLake.

Start by signing up to SQLake, it’s completely free to try. Once logged in, launch the Streaming pipeline with Redpanda template.
The template will include the following sections of code. Each should be self-explanatory but we’ll go briefly through each one here.
2a. Create a connection to read data from Redpanda. Since Redpanda is Kafka-compatible, we’ll use the KAFKA connection that already exists in SQLake.
Before executing the above, make sure to update the bolded properties with your own information.
2b. Create a staging table to hold the raw stream. This table is located in the data lake and will be maintained and optimized by SQLake. You can query it at any time with a data lake query engine like Amazon Athena.
2c. Create a job to stream data into the table from the Redpanda topic.
Query the staging table to make sure data is available before continuing to the next step.
A sample output should look like this:

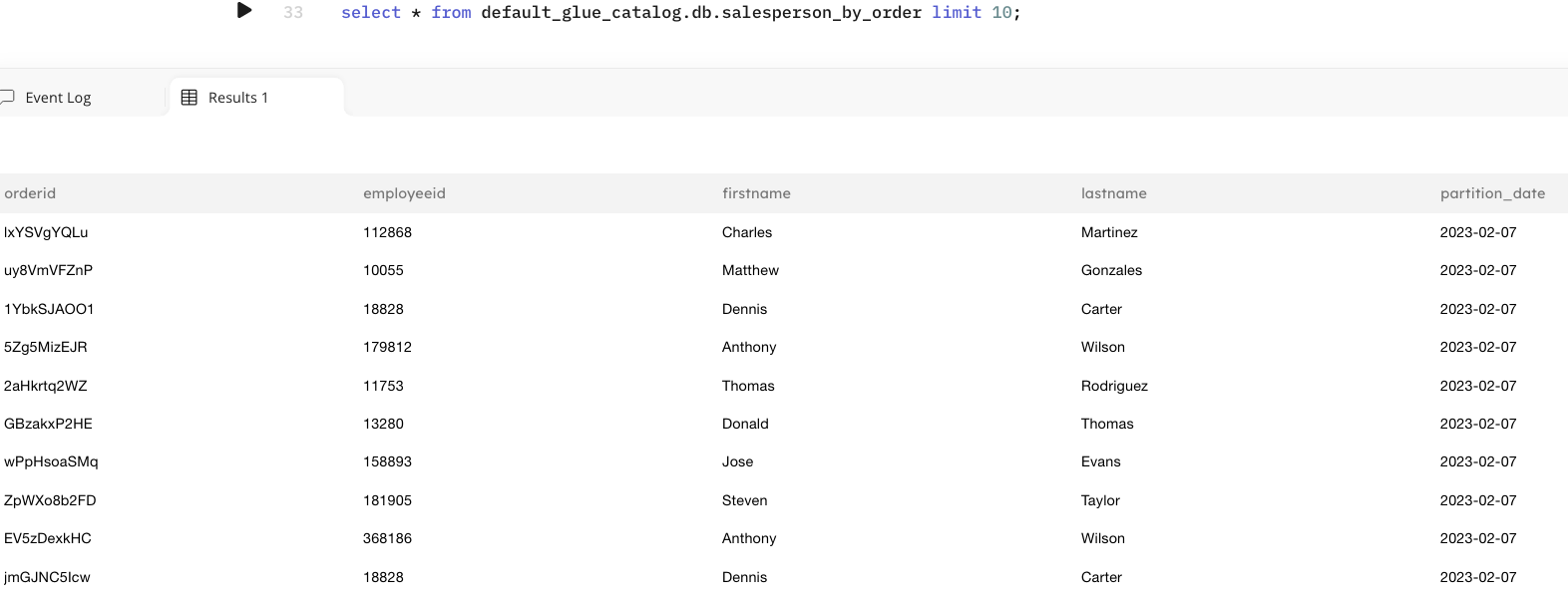
2d. Create a materialized view to continuously update the last salesperson's information on an order. This view is used to join a particular order with the most recent salesperson who took action against that order using the orderid as the join key.
At this stage, the streaming data is continuously ingested. All the raw events are persisted to the data lake in S3 and made queryable. A materialized view is being updated based on salesperson action captured in real-time. The next phase of the pipeline will load the historical orders data which we’ll join with the salesperson's actions.
3a. Create a connection to SQLake’s sample S3 bucket where the order data is stored.
3b. Create a staging table in the data lake to hold the raw order data. This is similar to the staging table we created for the streaming source.
3c. Create an ingestion job to load raw orders into the staging table.
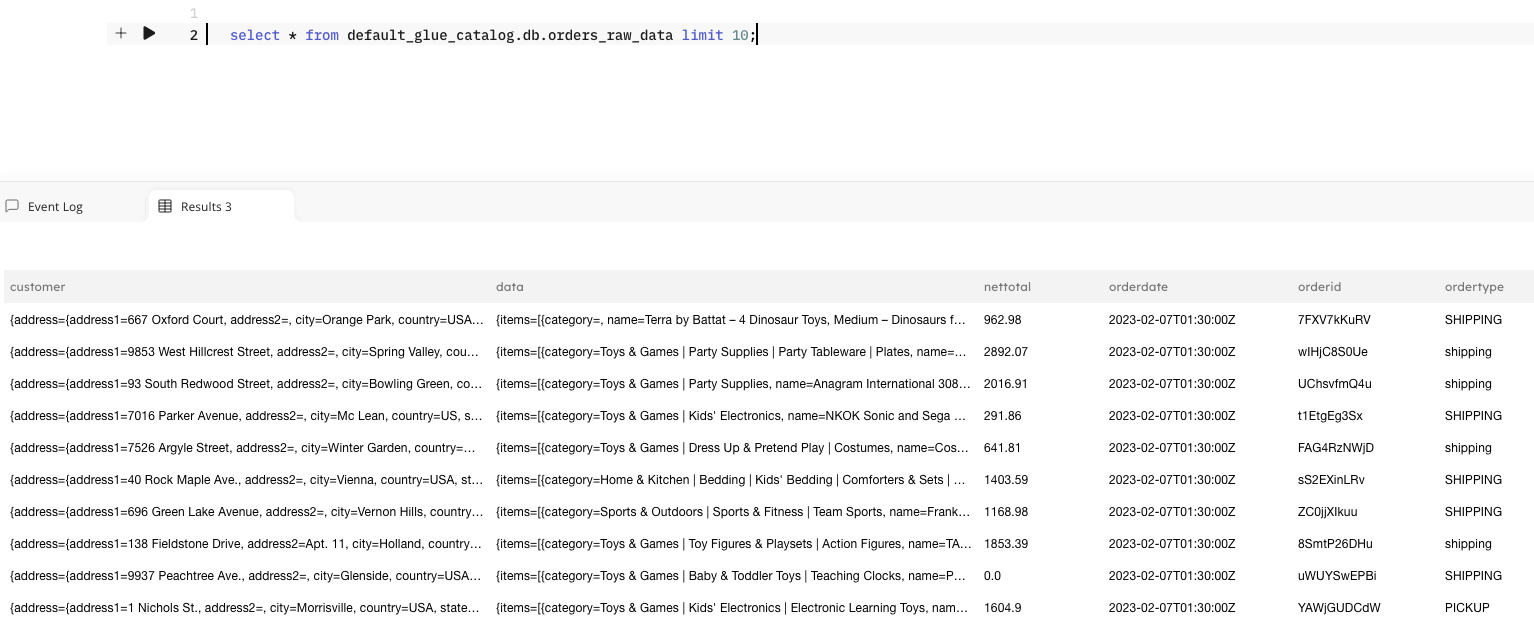
Query your raw data in SQLake. It may take a minute for the data to appear.
A sample output should look like this:
This SQL statement may be overwhelming but it’s actually simple. It creates a job that reads the raw order data from the staging table and joins it with the materialized view we created in Step 2d. You can customize the SELECT block to include specific columns you’re interested in exposing or perform business logic transformations that suit your needs. This example only exposes the salesperson's information and the ID of the order they're currently fulfilling.
4a. Create a table to store the final datasets
4b. Create a job to transform, join and load results to the target table.
Query the output table to view the results of the transformation job. Since this target table was created in the data lake you can use any query engine that supports reading from the data lake. Additionally, you can store your output in Snowflake or Amazon Redshift.
Through a simple example, we demonstrated that combining historical data with streaming events is a powerful tool to deliver fresh insights. Using only SQL, you built a data pipeline that consumed real-time events from Redpanda and stored them in the data lake. You then took raw JSON objects in S3 and staged them in the data lake. Both of these staging tables in the data lake are queryable and automatically maintained for you to improve performance and reduce query costs. From there, you joined both historical and streaming data to produce the final output.
All of this took only a few minutes and a handful of SQL to implement! You didn’t need to configure a schedule for the jobs or orchestrate them to run—it was all automatically created for you. Eliminating manual, error-prone tasks enables more users to be self-sufficient and deliver value with data quickly.
Try Upsolver SQLake for free today. Explore the builder hub to get started with tutorials, videos, and SQL templates. Join our Slack Community and meet with fellow developers or chat with our solution architects, product managers, and engineers.
You can also take Redpanda for a test drive! Check out our documentation to understand the nuts and bolts of the platform, and browse our Redpanda Blog for free tutorials and step-by-step integrations. If you have questions, get in touch to chat with our Solution Architects and Core Engineers. Lastly, don’t forget to join the Redpanda Community on Slack to hang with fellow Repanda users.
Subscribe to our VIP (very important panda) mailing list to pounce on the latest blogs, surprise announcements, and community events!
Opt out anytime.

