





Deploy agents you can trust with centralized AI governance
You can't scale what you can't trust. A governance layer fixes that.

Your guide through the wild west of techniques, tools, and technologies for building real-time data pipelines








In today's data-driven world where information serves as the lifeblood of organizations, the role of data engineering has emerged as a crucial pillar in transforming raw data into valuable insights. Data engineering, often called the backbone of modern analytics, involves a meticulous process of collecting, refining, and orchestrating data to fuel the engines of business intelligence, decision-making, and innovation.
In this series, we’ll discus what data engineering is, why it exists, and different techniques used in achieving it. From pipeline architecture to data transformation techniques, and real-time processing to storage solutions—this guide is an indispensable compass for anyone navigating the intricate landscape of data engineering.
Data engineering is the process of designing, building, and maintaining data pipelines within a business that enables deriving meaningful insights from operational data. A data engineering role is a critical position within an organization's data ecosystem since they’re responsible for designing, building, and maintaining the infrastructure and pipelines that enable the collection, storage, and processing of large volumes of data. They play a pivotal role in ensuring that data is accessible, reliable, and ready for analysis by data scientists and analysts.
Their responsibilities include a wide range of tasks, including data ingestion from various sources, data transformation, data cleaning, and the creation of efficient ETL (Extract, Transform, Load) processes.
Data engineers also manage data warehouses, databases, and distributed computing frameworks, ensuring optimal performance and scalability. They also collaborate closely with data scientists and other data stakeholders to help shape the foundation upon which data-driven decision-making and insights are built, making them indispensable members of any data-driven organization.
Now that we understand what data engineering is, let’s explore its reason for existence.
Businesses generate a vast amount of data in various forms as a result of their operations. For example,
This data can be in structured, semi-structured, or unstructured formats, stored in operational systems (i.e. transactional systems) optimized for transactional workloads and rapid data updates.
So, what can a business do with this enormous amount of raw data?
Properly analyzing and acting upon raw data enables businesses to make strategic decisions, adapt to changing market conditions, improve customer experiences, optimize operations, and drive growth. Once analyzed, the insights are then consumed by various stakeholders within a business.
These stakeholders include:

However, analyzing operational data in its raw form can be challenging and inefficient for several reasons.
Data must be cleaned: Operational data might contain inconsistencies, errors, missing values, and redundant information.
Scattered data: Operational data often comes from different sources with varying structures and formats. They must be consolidated and transformed into a unified format conducive to analysis.
Data should be aggregated and summarized: Analytical insights often require aggregated and summarized data. Transforming operational data enables the creation of aggregated views that provide a higher-level perspective for analysis.
Data should be enriched: Incorporating external data, such as demographic information or geographic data, enhances the analysis context.
Performance optimization: Raw operational data might not be optimized for efficient querying and analysis.
Transforming data into an analytics-optimized format is necessary to address these challenges and unlock the full potential of the data. There are mainly two ways to do that: ETL and ELT.
ETL is an acronym for the three stages of data processing—extracting from source systems, transforming them to match the format expected by the target system, and finally loading them to the target system, such as a data warehouse or a columnar database.
ETL process works like this:
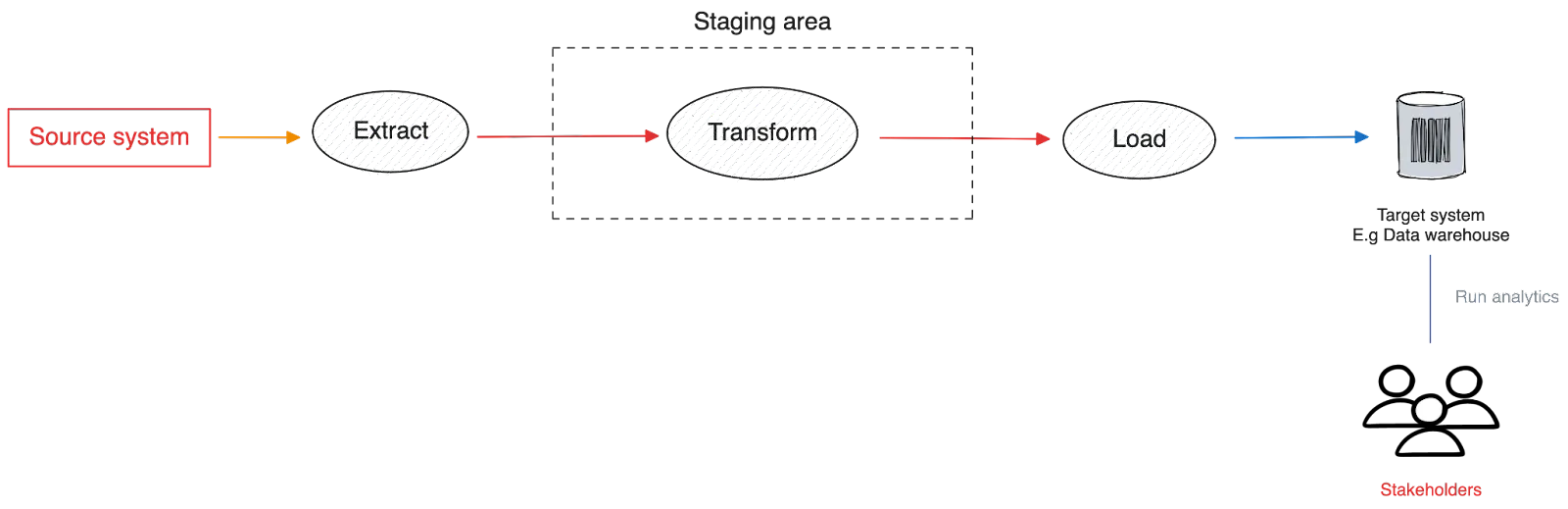
Since the data warehouses were invented, ETL has been the default approach for moving operational data to them.
ETL only processes the data set that was necessary for data analysis. However, when the data volume, velocity, and veracity increased over time, businesses began collecting all the data produced in the business to process them later.
When the big data hype came, cost-effective storage, like cloud object stores, became popular. Enter data lakes.
The idea of ELT is to collect all data and move them to a data lake or warehouse immediately. Then do the transformation on-demand when running analytics queries.
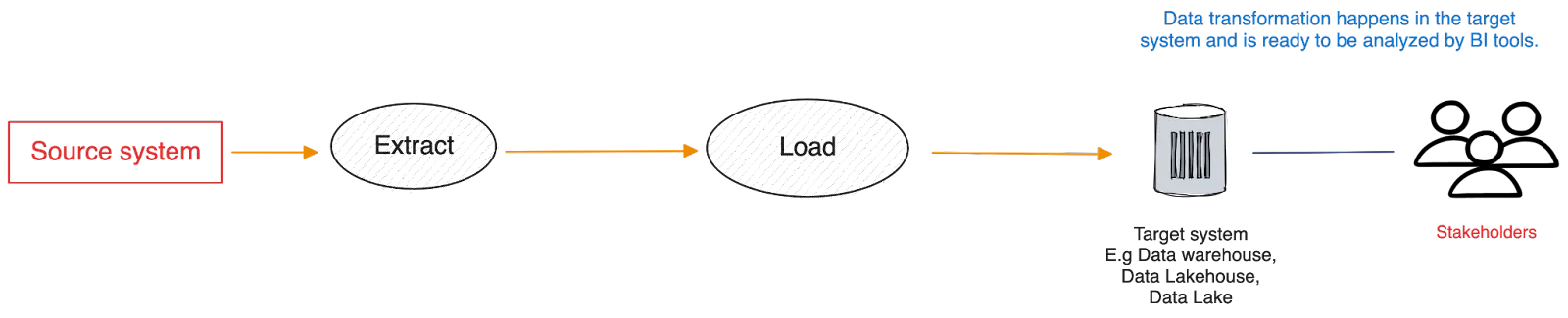
Whether you’re using ETL or ELT, operational data must be moved to an analytics-optimized target system to derive meaningful insights. This data movement is facilitated by data pipelines–the infrastructure that transfers data from their sources to destinations.
A data pipeline has an origin and a destination. Also, it consists of one or more processing steps, each performing a specific operation on the data moving from its origin toward the destination. If we take it more technically, we can think of a pipeline as a directed acyclic graph (DAG).
The processing steps of a pipeline perform transformations on data and might use external storage as the staging area for reading and writing data. Each pipeline is monitored to detect failures. Furthermore, pipelines can be scheduled to run at specific times and intervals.
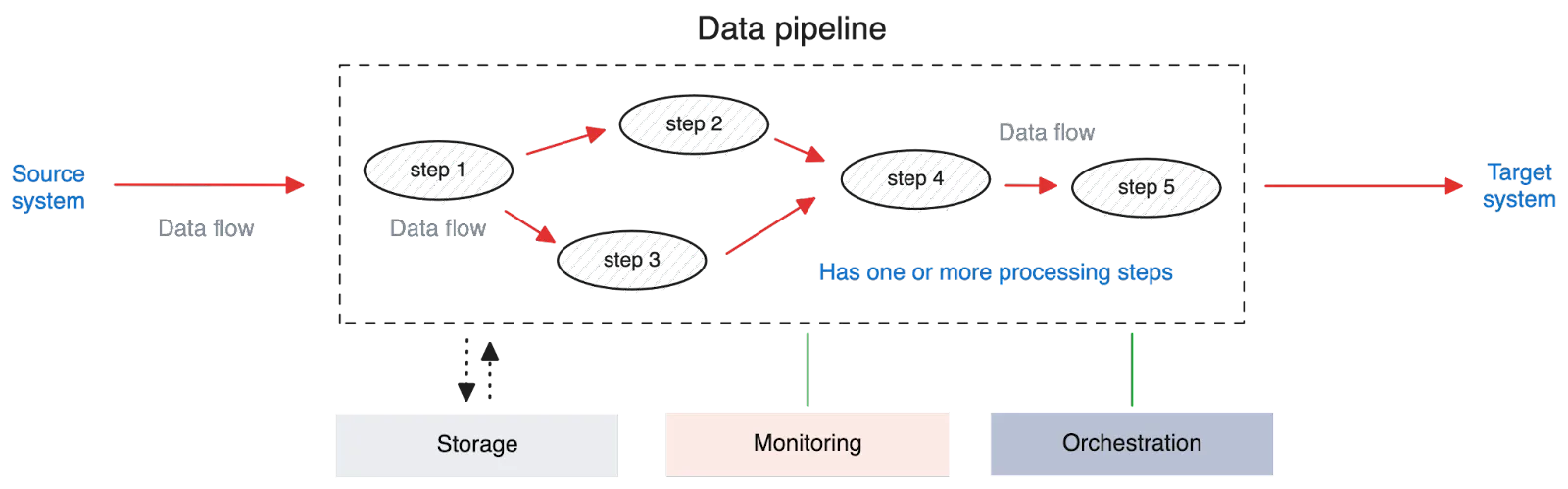
Data pipelines are divided into batch and streaming based on their processing latency. Let’s look at both of these a little more closely.
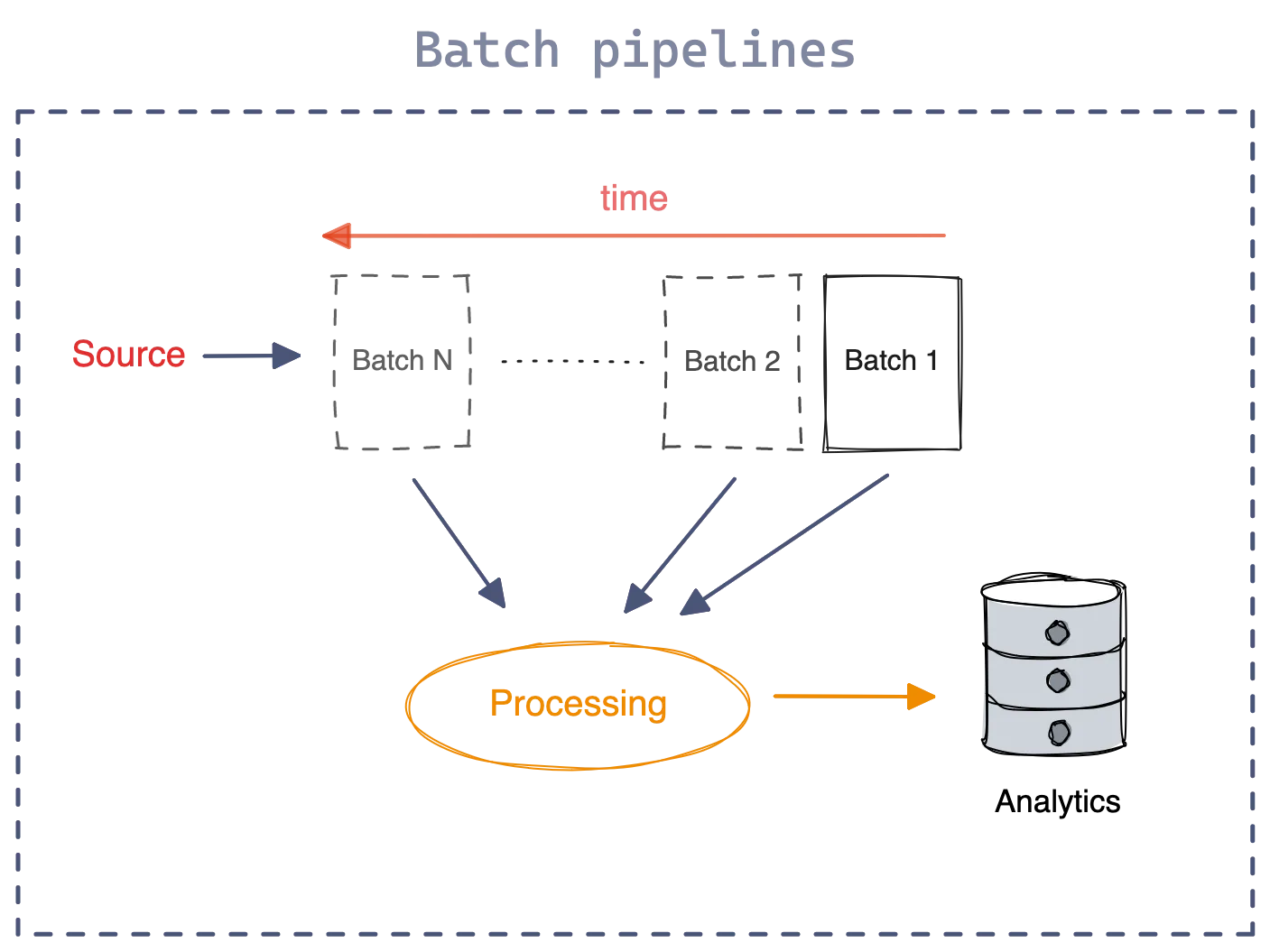
Batch pipelines extract and process large chunks of data (batches) at regular intervals or as a one-off job. Once the processing is completed, the analytics are generated.
The time it takes for pipeline execution can vary depending on the batch size. It can take a few minutes to several hours or even days. To prevent source systems from becoming overloaded, the process is typically carried out during periods of low user activity, such as at night or on weekends.
Streaming or real-time data pipelines extract and process data as they are generated. Typically, their processing latencies range from milliseconds to seconds. Unlike batch pipelines, stakeholders no longer have to wait for the streaming data pipeline to complete its run, allowing quick reactions to generated insights.
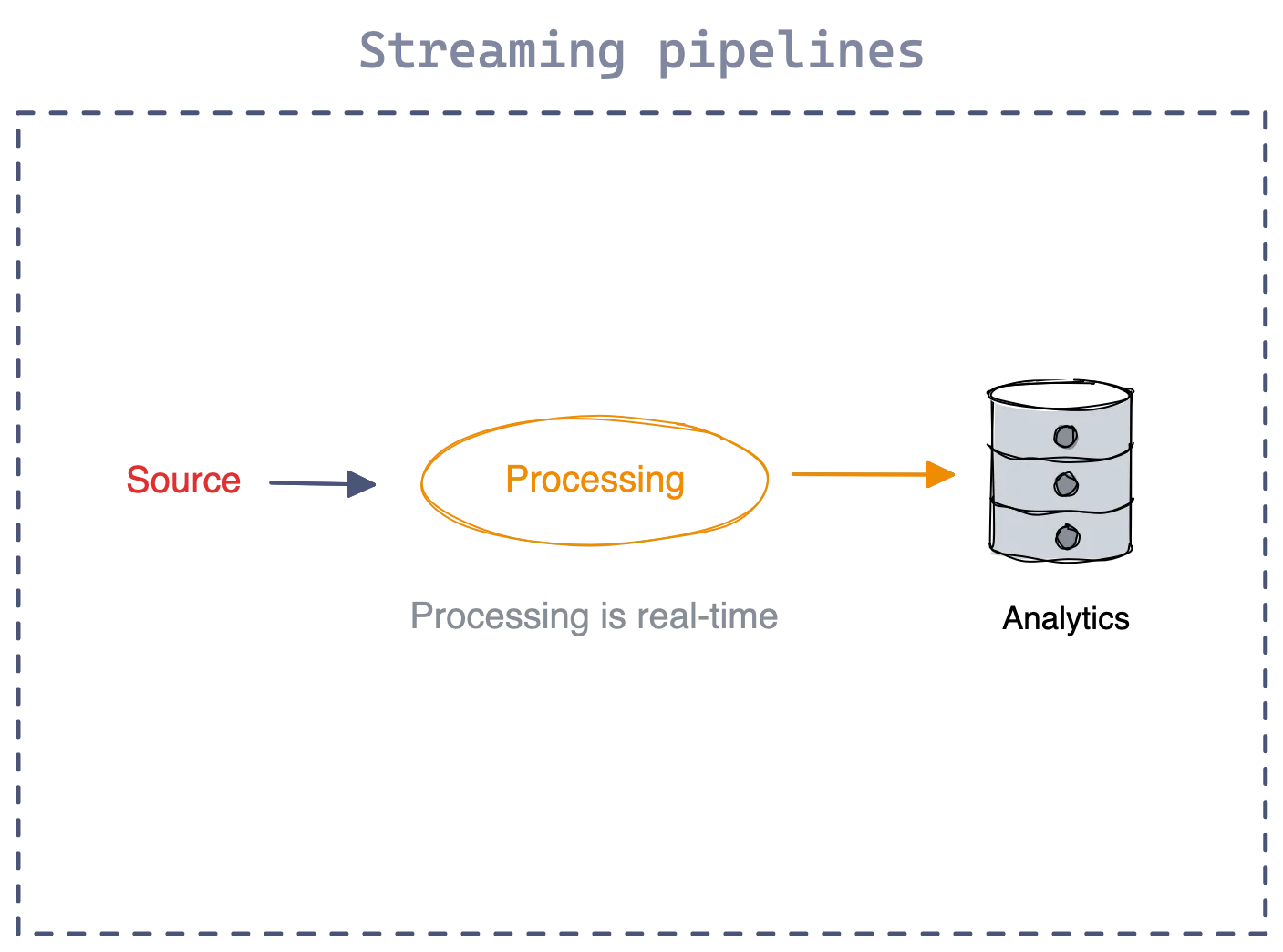
Several frameworks and platforms are designed to handle both batch and streaming data pipelines, providing a unified approach to data processing. Here are some popular ones:
Apache Spark™: Spark is a versatile framework that supports both batch and stream processing. It provides libraries like Spark Streaming for real-time data processing and structured APIs for batch processing.
Apache Flink®: Flink is a stream processing framework that also offers support for batch processing. It provides powerful APIs for building complex data processing applications.
Apache Beam®: Apache Beam is a unified programming model for both batch and stream processing. It allows you to write data processing pipelines that can be executed on various processing engines, including Apache Spark and Apache Flink.
Kafka Streams: Kafka Streams is a stream processing library that's tightly integrated with Apache Kafka®. While its primary focus is on stream processing, it can handle simple batch processing tasks as well.
Google Cloud Dataflow: Google Cloud Dataflow is a fully managed stream and batch data processing service that's part of the Google Cloud Platform. It uses the Apache Beam programming model and can run on Google Cloud's infrastructure.
Amazon Kinesis: Amazon Kinesis is a cloud-based platform for real-time data streaming and batch processing. It includes services like Kinesis Streams and Kinesis Data Analytics for handling both types of data processing tasks.
While these frameworks provide a foundation for building data pipelines, distributed storage systems also play a crucial role in scalable, reliable, and cost-efficient data ingestion from transactional systems, acting as both sources and destinations for pipelines.
Streaming data platforms, such as Apache Kafka, Redpanda, Apache Pulsar, and Amazon Kinesis, support streaming data ingestion and consumption, allowing consumers to process data while the data is moving.
We’ll dig into processing tools and data storages in our upcoming post.
In the dynamic landscape of data engineering, the journey from raw data to actionable insights is complex yet rewarding. As organizations continue to gather vast volumes of information, the role of data engineers becomes increasingly pivotal in shaping the foundation of data-driven decision-making.
This field guide has illuminated the essential elements of data engineering–crafting efficient data pipelines to generate value from the operational data produced in a business. The next post of this series goes into more detail about data pipelines, discussing the different processing tools and storage systems involved in data engineering.
If you have a question or want to chat with data engineers around the world, join the Redpanda Community on Slack.
You can't scale what you can't trust. A governance layer fixes that.

Your lakehouse mirrors the database, instantly.

What is it, why enterprises need it, and how to evaluate one
Subscribe to our VIP (very important panda) mailing list to pounce on the latest blogs, surprise announcements, and community events!
Opt out anytime.