





Full CDC semantics land in the Iceberg output for Redpanda Connect
Your lakehouse mirrors the database, instantly.

Learn how to integrate Databricks with Redpanda for real-time analysis of clickstream data.








Global organizations need a way to process the massive amounts of data they produce for real-time decision making. They often utilize event-streaming tools like Redpanda with stream-processing tools like Databricks for this purpose.
An example use case is recommending content to users based on their clicks on a mobile or web app. The clickstreams will be streamed through Redpanda to Databricks, where a recommendation engine will analyze their data and recommend content:
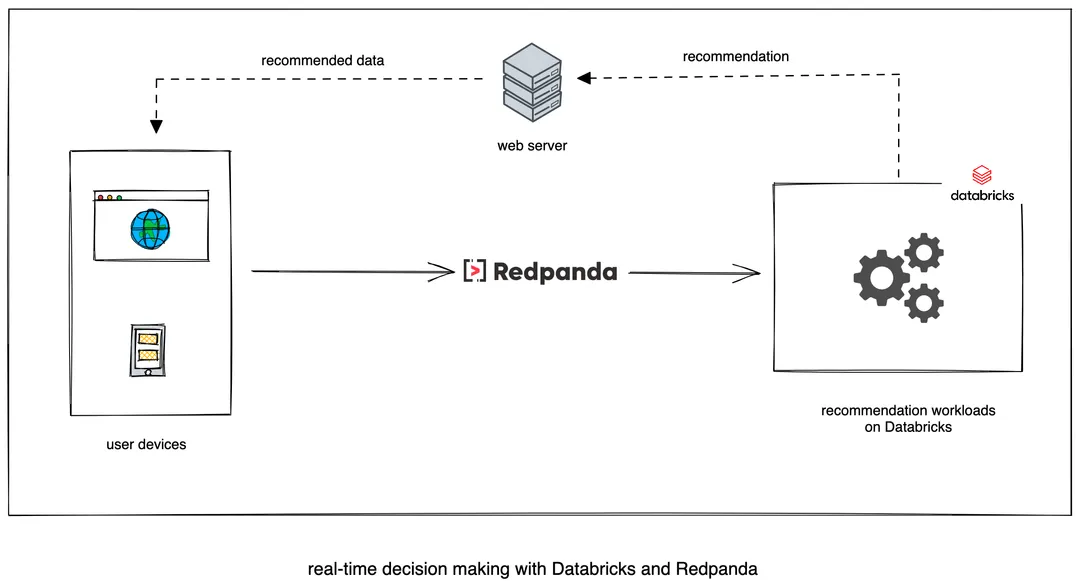
Redpanda is a fast and scalable real-time event streaming platform that serves as an Apache KafkaⓇ alternative. It’s API-compatible with Kafka, so all of your existing tooling with Kakfa works with Redpanda, too. It also ships as a single binary and can run on a virtual machine, Docker, and Kubernetes.
This tutorial covers event streaming and data analytics using Redpanda and Databricks. You will learn how to produce data to a Redpanda topic from a shell, store the produced data in CSV files within Databricks, and analyze the data in real-time to obtain insights.
Let’s get started! First, the prerequisites. To complete this tutorial, you’ll need the following:
To set up Redpanda, create a docker-compose.yml file in a server that can be accessed over the internet. This ensures that the Redpanda broker can communicate with your deployed Databricks instance:
version: "3.7"
services:
redpanda:
command:
- redpanda
- start
- --smp
- "1"
- --reserve-memory
- 0M
- --overprovisioned
- --node-id
- "0"
- --kafka-addr
- PLAINTEXT://0.0.0.0:29092,OUTSIDE://0.0.0.0:9092
- --advertise-kafka-addr
- PLAINTEXT://redpanda:29092,OUTSIDE://localhost:9092
image: docker.vectorized.io/vectorized/redpanda:latest
container_name: redpanda-1
ports:
- 9092:9092
- 29092:29092
- 8081:8081Start the Redpanda container by changing directories to the directory containing the docker-compose.yml file and execute the following command:
docker compose up -dThis operation will pull the Redpanda Docker image and start Redpanda on port 9092. Ensure your virtual machine instance has a static public IP address and that port 9092 is public.
Refer to the following guides to add a public IP address and port on your virtual machine instance:
To get started, create a Databricks account (Your account is free for a 14-day trial period). After filling in your account details, you'll be redirected to choose a cloud provider. Go ahead with your preferred cloud provider, choosing the appropriate setup instructions from the list below:
After a successful setup, you should land on a dashboard with links to various aspects of Databricks.
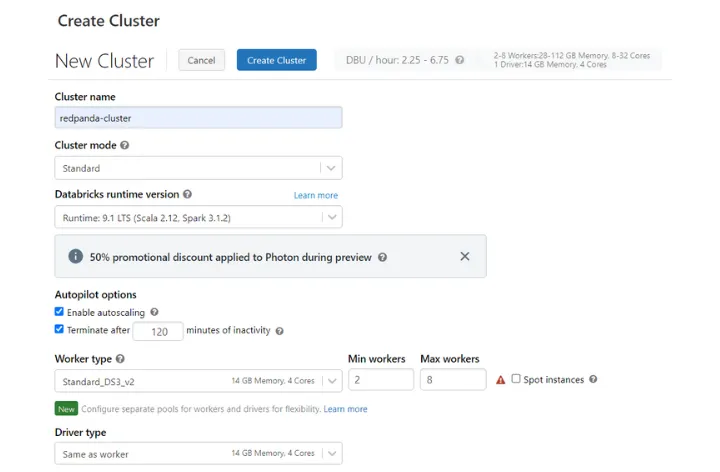
Your first task is to create a Databricks cluster. A cluster is a set of computational resources and configurations that lets you run data science and engineering workloads. In this case, you’ll be running a data engineering workload to stream data from a Redpanda topic to a CSV file within Databricks.

On the dashboard, click on the Create button at the top left to create a new cluster. By clicking on Cluster, you’ll be taken to a page to configure your cluster’s properties. Choose a name for your cluster and leave the other fields unchanged; then, click on Create Cluster.
You’ll be using a Databricks notebook to carry out all the tasks in this tutorial. A Databricks notebook is an interface that can contain runnable code, documentation, and visualization, similar to a Jupyter notebook. This notebook will serve as the scratchpad for running your commands. Again, click on the Create button at the top left of your dashboard and this time select the option to create a new Notebook. Choose a descriptive name like redpanda-kconnect-scratchpad and set Scala as the default language.

After setting up your first notebook, paste the content below in the notebook’s first cell:
import org.apache.spark.sql.functions.{get_json_object, json_tuple}
var streamingInputDF =
spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "SERVER_IP:9092")
.option("subscribe", "csv_input")
.option("startingOffsets", "latest")
.option("minPartitions", "10")
.option("failOnDataLoss", "true")
.load()
.select($"value".cast("string"))
.as[(String)]import org.apache.spark.sql.functions.{get_json_object, json_tuple}
var streamingInputDF =
spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "SERVER_IP:9092")
.option("subscribe", "csv_input")
.option("startingOffsets", "latest")
.option("minPartitions", "10")
.option("failOnDataLoss", "true")
.load()
.select($"value".cast("string"))
.as[(String)]
The code snippet above creates a streaming data frame assigned to the variable streamingInputDF. This data frame subscribes to the topic of interest, csv_input, in the Redpanda cluster. The cluster is identified by the server IP and port. The port in this case is 9092, the same port that Kafka exposes.
Replace SERVER_IP with the deployed IP address of your server. After setting the SERVER_IP, run the cell to initialize the configuration. You should get an output similar to the one below:
streamingInputDF:org.apache.spark.sql.Dataset[String] = [value: string]
import org.apache.spark.sql.functions.{get_json_object, json_tuple}
streamingInputDF: org.apache.spark.sql.Dataset[String] = [value: string]streamingInputDF:org.apache.spark.sql.Dataset[String] = [value: string]
import org.apache.spark.sql.functions.{get_json_object, json_tuple}
streamingInputDF: org.apache.spark.sql.Dataset[String] = [value: string]
In order to save data in Databricks, you need to define a write stream to a file. This write stream should be of the same file type as the input stream. The snippet below reads data from the streamingInput data frame and writes it to a CSV file. The write operation is performed every thirty seconds and all new entries to the Redpanda topic will be read and written to a new CSV file.
Create a second cell and add the content in the snippet below:
import org.apache.spark.sql.streaming.Trigger
val query =
streamingInputDF
.writeStream
.format("csv")
.outputMode("append")
.option("path", "/FileStore/tables/user-details-data")
.option("checkpointLocation", "/FileStore/tables/user-details-check")
.trigger(Trigger.ProcessingTime("30 seconds"))
.start()import org.apache.spark.sql.streaming.Trigger
val query =
streamingInputDF
.writeStream
.format("csv")
.outputMode("append")
.option("path", "/FileStore/tables/user-details-data")
.option("checkpointLocation", "/FileStore/tables/user-details-check")
.trigger(Trigger.ProcessingTime("30 seconds"))
.start()
Now, run the command to start the streaming operation. Your output should look similar to the image below.
In order to see actual data in Databricks, you’ll stream data to Redpanda using Kafkacat. Run the command below in your shell to create a Redpanda console producer. Replace SERVER_IP with the IP address of the server running Redpanda:kafkacat -b SERVER_IP:9092 -t csv_input1 -P
Now paste the CSV content into the producer line by line:
id,first_name,last_name
1,Israel,Edeh
2,John,Doe
3,Jane,Austin
4,Omo,Lawal
5,John,Manson
6,John,Rinzlerid,first_name,last_name
1,Israel,Edeh
2,John,Doe
3,Jane,Austin
4,Omo,Lawal
5,John,Manson
6,John,Rinzler
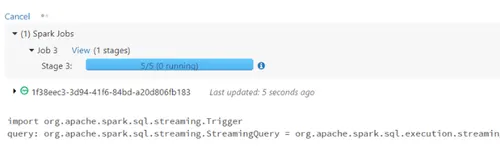
Depending on your interval of pasting the content, you should see five completed jobs in the output area of the write stream cell.
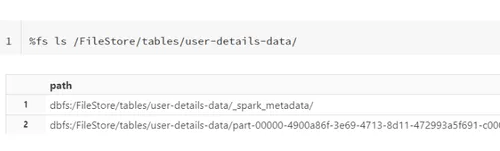
To see the CSV files, create a new cell and run the following command:%fs ls /FileStore/tables/user-details-data/
You should get a table showing all created CSV files in the output area.
Run the command below to see the actual content of the files:spark.read.csv("/FileStore/tables/user-details-data/").show()
You should get an output listing the entries you’ve streamed so far. It will look something like this:
+-------------+
| _c0|
+-------------+
|id, first_name,last_name|
|1,Israel,Edeh|
|3,Jane,Austin|
|5,John,Manson|
|6,John,Rinzler|
| 4,Omo,Lawal|
| 2,John,Doe|
+-------------++-------------+
| _c0|
+-------------+
|id, first_name,last_name|
|1,Israel,Edeh|
|3,Jane,Austin|
|5,John,Manson|
|6,John,Rinzler|
| 4,Omo,Lawal|
| 2,John,Doe|
+-------------+
Databricks offers data analysis and machine learning tools to help organizations make sense of their data. You can perform simple analysis on the data you streamed in this tutorial using Apache SparkⓇ queries. Say you want to group users by their first name to find out the number of users with the same first names. You can use the following code to achieve this:
%python
users_df = spark.read.csv("/FileStore/tables/user-details-data/", header="true", inferSchema="true")
users_df.groupBy("first_name").count().show()%python
users_df = spark.read.csv("/FileStore/tables/user-details-data/", header="true", inferSchema="true")
users_df.groupBy("first_name").count().show()
Running the command above will produce the following result:
+----------+-----+
|first_name|count|
+----------+-----+
| John| 3|
| Israel| 1|
| Omo| 1|
| Jane| 1|
+----------+-----++----------+-----+
|first_name|count|
+----------+-----+
| John| 3|
| Israel| 1|
| Omo| 1|
| Jane| 1|
+----------+-----+
You can see from the analysis that three users have "John" as their first name. You can run further analysis with a dataset with more rows.
Databricks also allows you to visualize and plot your data. You can prepare your CSV data for plotting by selecting the headers and configuring the plot options. Your first task is to display the data as a table. Run the command below in a new cell to do so:
%python
diamonds_df = spark.read.csv("/FileStore/tables/user-details-data/", header="true", inferSchema="true")
display(diamonds_df.select("id", "first_name", "last_name"))%python
diamonds_df = spark.read.csv("/FileStore/tables/user-details-data/", header="true", inferSchema="true")
display(diamonds_df.select("id", "first_name", "last_name"))
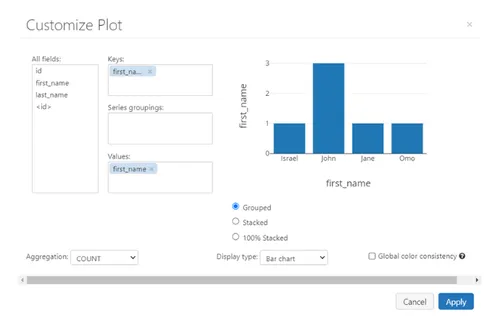
Now, change the display type to bar and then click on the Plot Options… button to customize the bar chart. Drag and drop first_name to the keys and values boxes and remove other fields. Then set the aggregation type to COUNT. Finally, click on Apply to apply your customization.
Distributed systems require speed at all levels and in every component. Redpanda scales particularly well for mission-critical systems, and without dependencies on a JVM or ZooKeeper.
Now that you know how to stream data from Redpanda to Databricks and analyze and plot data using Databricks’s native display function, you can use this setup to analyze data in real-time for nearly any project.
Interact with Redpanda’s developers directly in the Redpanda Slack community, or contribute to Redpanda’s source-available GitHub repo.To learn more about everything you can do with Redpanda, check out the documentation here.
Subscribe to our VIP (very important panda) mailing list to pounce on the latest blogs, surprise announcements, and community events!
Opt out anytime.

