




Full CDC semantics land in the Iceberg output for Redpanda Connect
Your lakehouse mirrors the database, instantly.
Learn how to build a real-time fraudulent click detection system using Redpanda, Spark, and Python









Fraud detection involves identifying fraudulent activities by analyzing patterns, behaviors, and anomalies in various types of data. Although to properly safeguard individuals, businesses, and financial institutions from fraudulent actions, it needs to happen as soon as the fraudulent activity occurs — in real time.
Fraud detection can be broadly classified into three categories:
In this post, you'll learn how to create a real-time fraudulent click detection system with Python, Redpanda, and Apache Spark.
Click fraud involves generating fake clicks on online content, usually ads, often through automated bots. You pay for each click, but they never lead to sales or desired actions, essentially wasting your resources. Additionally, click fraud inflates click-through rates and other metrics, creating a false picture of how users interact with online content, which can lead to misguided strategies and campaigns.
In this tutorial, you'll build a system that flags three or more clicks on a URL in the same session within the last ten seconds as fraudulent. Users interact with a basic Python application ("The Application") to click a link. The system's producer application ("Fraud Detection Producer") then sends the JSON data to a Redpanda topic (fcd-producer). The streamer application ("Fraud Detection Streamer App") accesses and processes this data using fraud detection logic and forwards the results to another Redpanda topic (fcd-consumer).
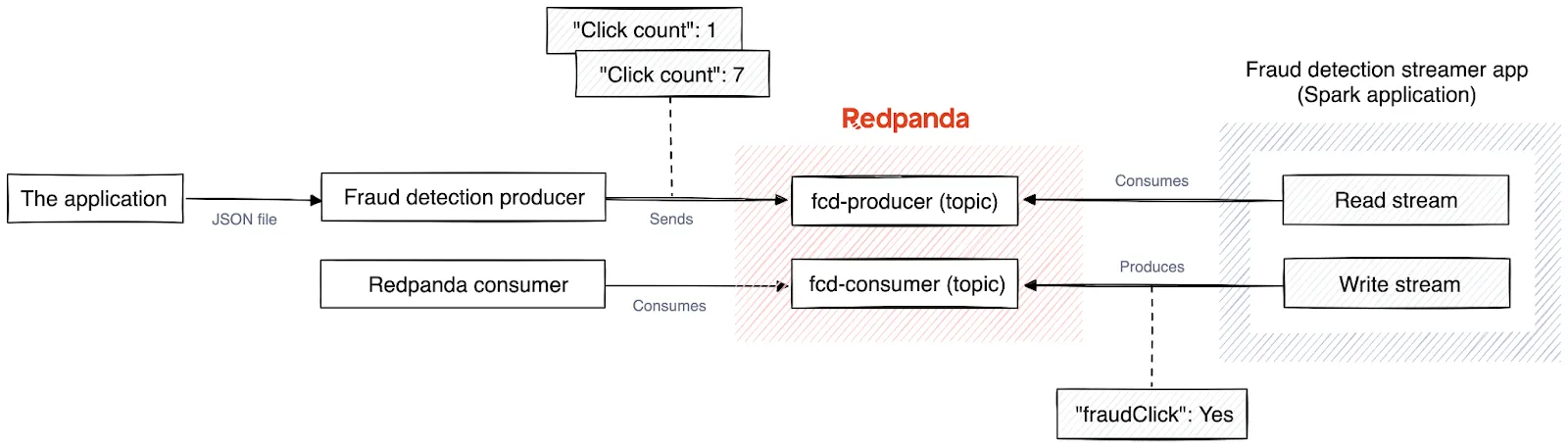
Fraudulent click detection system architecture
Redpanda offers low latency reads and high throughput processing to click events, allowing your real-time fraud detection system to respond to potential threats in real time. Apache Spark contributes to the system by providing features like batch and streaming data, SQL analytics, data science, and machine learning computations at scale.
You'll need the following to complete this tutorial:
Fraud_Click_Detection in your home directory to use as a workspace.Your Redpanda instance is already running on Docker, so you can create the producer and consumer topics using the following command:
docker exec -it redpanda-1 \
rpk topic create fcd-producer fcd-consumerYou should get the following output:
TOPIC STATUS
fcd-producer OK
fcd-consumer OKThe application you're creating consists of two primary components: one for users to click a link, and another that uses Spark to send data to the Redpanda topic.
To implement the link-clicking component, you'll need the Flask and JSON libraries. You can download them by running the following command:
pip install flask jsonOnce installed, create a folder named click_link_app inside the Fraud_Click_Detection directory, and then create a Flask app named app.py inside this click_link_app folder to perform the clicking action. Use the following Python code:
from flask import Flask, render_template, jsonify
import json
app = Flask(__name__)
# Initialize click count
click_count = 0
json_file_path = "click_count.json"
# Load existing click count from JSON file
try:
with open(json_file_path, "r") as file:
click_count_data = json.load(file)
click_count = click_count_data.get("click_count", 0)
except FileNotFoundError:
# If the file is not found, create a new one
with open(json_file_path, "w") as file:
json.dump({"click_count": click_count}, file)
@app.route('/')
def index():
return render_template('index.html', click_count=click_count)
@app.route('/click')
def click():
global click_count
click_count += 1
# Update the JSON file with the new click count
with open(json_file_path, "w") as file:
json.dump({"click_count": click_count}, file)
return jsonify({"click_count": click_count})
if __name__ == '__main__':
app.run(debug=True)All HTML and CSS scripts should be stored in the templates folder inside the Fraud_Click_Detection/click_link_app/ directory. Before running the application, you need to download the index.html file and place it inside the templates folder.
This application is designed with simplicity in mind, giving you the flexibility to customize it to meet your specific needs. It's important to note that the app is currently configured to manage one session at a time.
To initiate the app, use the command python app.py. You can click the button as many times as you like, and the resulting data will be stored in a JSON file named click_count.json.
Now that you have the JSON file containing the click counts, you can send that data to Redpanda. You'll employ a Python script that uses Kafka to send the click count data to the Redpanda topic. To do so, you need to install the Kafka dependency using the following command:
pip install kafka-python
Then, create a folder called fraud_detection_producer in the Fraud_Click_Detection project directory. Inside the new folder, create a new Python file named fraud_detection_producer.py with the following code:
import time
import json
from kafka import KafkaProducer
def get_click_count():
file = open('/Users/userabc/click_count.json')
click_data = json.load(file)
return click_data['click_count']
def get_json_data():
data = {}
data["click_count"] = get_click_count()
return json.dumps(data)
def main():
producer = KafkaProducer(bootstrap_servers=['localhost:9092'], api_version=(0, 10, 1))
json_data = get_json_data()
print(json_data)
kafka_topic = 'fcd-producer'
kafka_topic = kafka_topic.encode(encoding = 'UTF-8')
producer.send(kafka_topic, bytes(f'{json_data}','UTF-8'))
print(f"Ad click data is sent: {json_data}")
time.sleep(5)
if __name__ == "__main__":
main()The above code creates a connection to the bootstrap server, then reads the click count data from the JSON file and sends it to the Redpanda topic.
Run this Python application using the following command:
python fraud_detection_producer.py
Note: If you want to run this application as a Docker image, you can create a Dockerfile inside the fraud_detection_producer folder with this configuration.
As soon as the Python code runs, you can open a terminal and check if the data is sent to the Redpanda topic using the following command:
docker exec -it redpanda-1 \
rpk topic consume fcd-producerYou should get an output similar to the following:
{
"click_count":7,
}Now that you have data in your Redpanda topic, you can create a Spark application to read the data from the Redpanda topic, process it, and send the processed data to another Redpanda topic.
To do so, inside the Fraud_Click_Detection directory, create another folder with the name fraud_detection_streamer. Inside fraud_detection_streamer, create a Python file named fraud_detection_streamer.py.
Start the Spark session using the following code:
...imports omitted...
spark = SparkSession\
.builder\
.appName("Fraud Click Detection")\
.getOrCreate()To add the component that consumes the messages from the Redpanda topic fcd-producer, use Spark's readStream() function and the subscribe option to specify the topic you need:
df = spark\
.readStream\
.format("kafka")\
.option("kafka.bootstrap.servers", "localhost:9092")\
.option("subscribe", "fcd-producer")\
.load()Use a struct array with the following field to load the data from Redpanda:
jsonschema = StructType([StructField("click_count", IntegerType())])
Once the data is loaded from Redpanda, you can write the fraud detection logic, where if the click count is greater than three, the transaction is flagged as fraudulent:
df = df\
.select(from_json(col("value").cast(StringType()), jsonschema).alias("value"))\
.select("value.*")\
.withColumn('fraudClick', when(col('click_count') > 3, "Yes").otherwise("No"))\
.withColumn("value", to_json(struct(col("fraudClick"))))The above code examines the click count and assigns the value Yes to a new column named fraudClick if the count is greater than three. Otherwise, it assigns No to fraudClick. The result is then returned as a response.
Send this response to another Redpanda topic using the writeStream() method from Spark:
query = df\
.writeStream\
.format('kafka')\
.option('kafka.bootstrap.servers', 'localhost:9092')\
.option('topic', 'fcd-consumer')\
.option('checkpointLocation', '/Users/userabc/chkpoint')\
.start()In the end, your fraud_detection_streamer.py file should contain the following code:
from pyspark.sql import SparkSession
from pyspark.sql.functions import *
from pyspark.sql.types import *
spark = SparkSession\
.builder\
.appName("Fraud Click Detection")\
.getOrCreate()
df = spark\
.readStream\
.format("kafka")\
.option("kafka.bootstrap.servers", "localhost:9092")\
.option("subscribe", "fcd-producer")\
.load()
jsonschema = StructType([StructField("click_count", IntegerType())])
df = df\
.select(from_json(col("value").cast(StringType()), jsonschema).alias("value"))\
.select("value.*")\
.withColumn('fraudClick', when(col('click_count') > 3, "Yes").otherwise("No"))\
.withColumn("value", to_json(struct(col("fraudClick"))))
query = df\
.writeStream\
.format('kafka')\
.option('kafka.bootstrap.servers', 'localhost:9092')\
.option('topic', 'fcd-consumer')\
.option('checkpointLocation', '/Users/userabc/chkpoint')\
.start()
query.awaitTermination()Open a new terminal and use the following command to read the output logs:
docker exec -it redpanda-1 \
rpk topic consume fcd-consumerLeave this terminal open to read the upcoming logs.
Finally, run the streamer Python app to read the input click count, process it, and send the data to another Redpanda topic (fcd-consumer):
python fraud_detection_streamer.py
This installs the necessary Spark packages and could take some time to execute.
Note: If you want to run this application as a Docker image, you can create a Dockerfile inside the fraud_detection_streamer folder with this configuration.
Finally, return to the previous terminal where the consumer is running. You should see output logs similar to the following:
{
"topic": "fcd-consumer",
"value": "{\"fraudClick\":Yes}",
"timestamp": 16548143011928,
"partition": 0,
"offset": 2
}Congratulations! You've created a real-time fraudulent click detection system using Redpanda, Apache Spark, and Python. You read the data from one Redpanda topic, processed it, and sent it to another Redpanda topic.
As technology advances, so do the methods employed by malicious actors, making it crucial for organizations to stay vigilant and continually enhance their fraud detection capabilities. The integration of artificial intelligence, machine learning, a rule-based approach, and real-time monitoring is key to building robust fraud prevention systems in today's digital landscape.
You can find the code used in this tutorial in this GitHub repository.
To keep exploring Redpanda, check the documentation and browse the Redpanda blog for tutorials. If you have any questions or want to chat with the team, join the Redpanda Community on Slack.
Subscribe to our VIP (very important panda) mailing list to pounce on the latest blogs, surprise announcements, and community events!
Opt out anytime.

