





Deploy agents you can trust with centralized AI governance
You can't scale what you can't trust. A governance layer fixes that.

Discover the key differences in performance and use cases between Kafka Streams vs Spark Streaming for real-time data processing.








Kafka Streams has inherent data parallelism, which allows it to distribute and assign input data stream partitions (or topics) to different tasks created from the application processor topology. It runs anywhere the Kafka Stream application instance is run, and it allows you to scale for high-volume workloads by running extra instances on many machines. Kafka Streams also has built-in fault tolerance, meaning if an application instance fails, another instance can simply pick up the data automatically and restart the task.
Kafka Streams has a few limitations. It only supports JVM languages, making its language support limited compared to other stream processing technologies. It is built to process data directly from Kafka, which makes its integration with other data sources difficult. Moreover, it does not have a built-in ML library that easily connects with it in the Kafka ecosystem, and it does not natively provide SQL support.
Apache Kafka Streams is an open-source, scalable, event-driven streaming platform originally developed by LinkedIn in 2011. It uses Kafka’s server-side cluster technology to store input and output data in clusters. Kafka Streams can transform Kafka real-time data input streams (topics) into output topics without the need for an external stream processing cluster.
Spark Streaming is a component of Apache Spark that helps with processing scalable, fault-tolerant, real-time data streams. It is distinct from Spark Structured Streaming, a framework built on the Spark SQL engine that processes data in micro-batches. Spark Streaming allows you to connect to many data sources, execute complex operations on those data streams, and output the transformed data into different systems.
Kafka Streams and Spark Streaming are both popular data stream processing technologies. Kafka Streams uses Kafka’s server-side cluster technology to store input and output data in clusters and is built to process data directly from Kafka. On the other hand, Spark Streaming is a component of Apache Spark that helps with processing scalable, fault-tolerant, real-time data streams and allows connection to many data sources.
The continuous availability of big data is becoming increasingly important to every aspect of the human experience. Across all kinds of products, customers now expect highly-personalized, real-time experiences. To keep up, businesses rely on a continuous stream of real-time data to satisfy their customers’ rapidly changing needs.
Several data stream processing technologies exist today, two of the most popular being Apache Kafka® Streams and Spark Streaming.
So, what’s the difference between Spark vs Kafka Streams? You may already know Apache Kafka as an open-source, scalable, event-driven streaming platform originally developed by LinkedIn in 2011 to provide high throughput and permanent data storage. In short, Kafka Streams uses Kafka’s server-side cluster technology to store input and output data in clusters.
Spark Streaming is a component of Apache Spark™ that helps with processing scalable, fault-tolerant, real-time data streams. Note that it’s not the same as Spark Structured Streaming, a framework built on the Spark SQL engine that helps process data in micro-batches. Unlike Spark Streaming, Spark Structured Streaming processes data incrementally and updates the result as more data arrives.
Let’s take a closer look at the differences between Kafka vs. Spark Streams and see how these two data streaming platforms compare. We’ll dissect them along the lines of their tech stacks, the integration support they provide, their analytic capabilities, ease of use, licensing, and a few other need-to-know factors.
Let’s start with Kafka Streams. It’s one of the five key APIs that make up Apache Kafka. It was built from the need for a convenient, Kafka-native library that can transform Kafka real-time data input streams (topics) into output topics without the need for an external stream processing cluster.
In the system illustrated below, for example, Kafka Streams interacts directly with the Kafka cluster and its brokers. It collects real-time data inside a specified topic and outputs the processed data into another topic or to an external system.
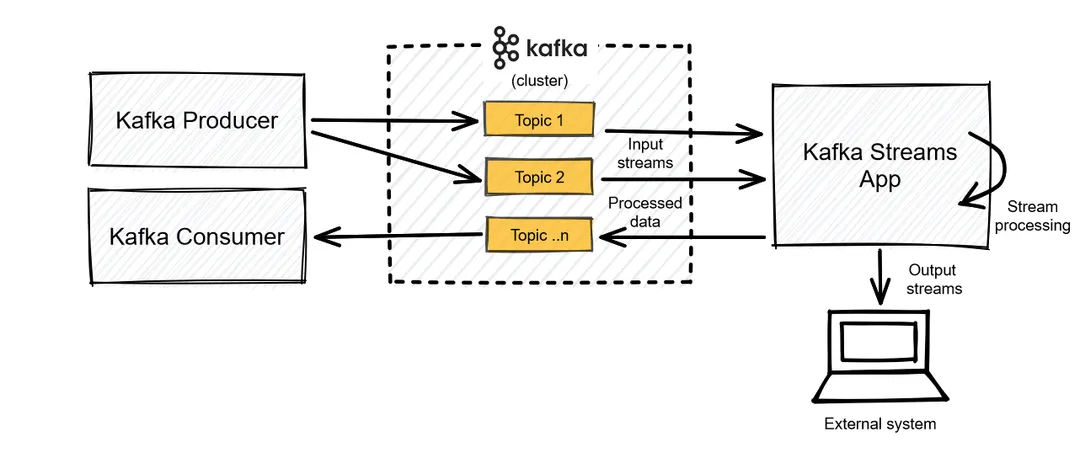
The Kafka Streams API supports JVM languages, including Java and Scala—so you can only import the library into Java and Scala applications. Although several Kafka and Kafka Stream client APIs have been developed by different user communities in other programming languages, including Python and C/C++, these solutions are not Kafka-native. So compared to other stream processing technologies, the language support for Kafka Streams is quite limited.
Kafka Streams is built to process data directly from Kafka, which makes its integration with other data sources difficult. However, it is possible to send the output data directly to other systems, like HDFS, databases, and even other applications. This is possible because your Kafka streams application is like any normal Java application that takes advantage of existing integration software and connectors.
Apache Kafka Streams gives you the power to carry out intensive data processing in real time with inherent data parallelism and partitioning in Kafka. It leverages the Kafka abstractions of the sequence of records (or streams) and a collection of streams (or tables) to perform analytical operations like averaging, minimum, maximum, etc. on data.
A limitation of Kafka Stream for machine learning is that it does not have a built-in ML library that easily connects with it in the Kafka ecosystem. Building an ML library on top of Kafka Streams is not straightforward either; while Java and Scala dominate data engineering and streaming, Python is the major language in machine learning.
As mentioned earlier, Kafka Streams has inherent data parallelism, which allows it to distribute and assign input data stream partitions (or topics) to different tasks created from the application processor topology. Kafka Streams runs anywhere the Kafka Stream application instance is run, and it allows you to scale for high-volume workloads by running extra instances on many machines. That’s a key advantage that Kafka Streams has over a lot of other stream processing applications; it doesn’t need a dedicated compute cluster, making it a lot faster and simpler to use.
Another important advantage of Kafka Streams is its built-in fault tolerance. Whenever a Kafka Streams application instance fails, another instance can simply pick up the and data automatically and restart the task. This is possible because the stream data is persisted in Kafka.
Sadly, Kafka Streams does not natively provide SQL support. Again, different communities and developers have several solutions built on Kafka and Kafka Streams that address this.
Maintaining state in stream processing opens up a lot of possibilities that Kafka Streams exploits really well. Kafka Streams has state stores that your stream processing application can use to implement stateful operations like joins, grouping, and so on. Stateless transformations like filtering and mapping are also provided.
Windowing allows you to group stream records based on time for state operations. Each window allows you to see a snapshot of the stream aggregate within a timeframe. Without windowing, aggregation of streams will continue to accumulate as data comes in.
Kafka Streams support the following types of windowing:
Kafka Streams stands out for its short learning curve, provided you already understand the Kafka architecture. The only dependency you need in order to whip up a Kafka Stream application is Apache Kafka itself and then your knowledge of a JVM language. It’s extremely simple to develop and deploy with your standard Java and Scala applications on your local machine or even in the cloud.
As part of the Apache Kafka platform, Kafka Streams licensing is currently covered under the Apache open-source License 2.0. Like all other software developed by the Apache Software Foundation, it’s free for all kinds of users. There’s also a large ecosystem that contributes and provides support if you run into any challenges with the tool.
The popular Apache Spark analytics engine for data processing provides two APIs for stream processing:
Spark Streaming is a distinct Spark library that was built as an extension of the core API to provide high-throughput and fault-tolerant processing of real-time streaming data. It allows you to connect to many data sources, execute complex operations on those data streams, and output the transformed data into different systems.

Under the hood, Spark Streaming abstracts over the continuous stream of input data with the Discretized Streams (or DStreams) API. A DStream is just a sequence, chunk, or batch of immutable, distributed data structure used by Apache Spark known as Resilient Distributed Datasets (RDDs).
As you can see from the following diagram, each RDD represents data over a certain time interval. Operations carried out on the DStreams will cascade to all the underlying RDDs.

Since the Spark 2.x release, Spark Structured Streaming has become the major streaming engine for Apache Spark. It’s a high-level API built on top of the Spark SQL API component, and is therefore based on dataframe and dataset APIs that you can quickly use with an SQL query or Scala operation. Like Spark Streaming, it polls data based on time duration, but unlike Spark Streaming, rows of a stream are incrementally appended to an unbounded input table as shown below.
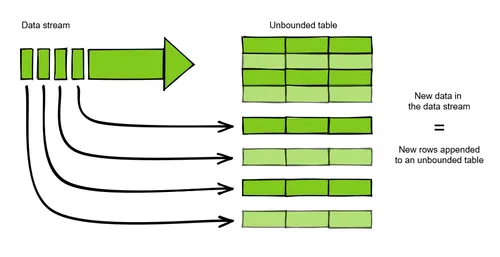
Note that we’re looking at Spark Streaming specifically in this article.
Spark Streaming provides API libraries in Java, Scala, and Python. Remember that Kafka Streams only supports writing stream processing programs in Java and Scala.
Spark Streaming integrates well with a host of other technologies, from data sources like Kafka, Flume, and Kinesis to other systems that consume stream data like HDFS and databases. It even provides support for multiple data sources through its DataFrame interface. Here again, Spark Streaming wins out over Kafka Streams.
With Spark Streaming, you have a whole suite of analytical operations available to you to process your stream data, like map, filter, count, and reduce. You can also perform many output operations on DStreams to get the stream data in a preferred format for your external systems. Some of these allow you to save files as Texts, Hadoop files, and so on
For the purposes of machine learning, Apache Spark has the MLlib library that provides ML algorithm tools you can easily apply to streamed data. In fact, it comes with a suite of algorithms that can simultaneously learn from data while applying the models to the data.
Spark Streaming also provides high-throughput, scalable, and fault-tolerant processing of messages that’s inherent in its DStreams architecture. But getting the best performance out of Spark Streaming requires you to carry out several performance tunings in your application.
For example, performance can bottleneck as your application scales; you’ll need to speed up the overall processing time for each batch of data by parallelizing the streams so you can receive multiple data streams at once. Performance tuning operations like that might have a steep learning curve when using Spark Streaming to handle large volumes of real-time messages efficiently.
You can easily use SQL with Spark Streaming, as it allows you to natively run SQL and DataFrame operations on data. It does this by converting each RDD in the DStream into a DataFrame in a temporary table, which can then be queried with SQL. A key advantage of this is that Spark Streaming is a nice balance between the imperative languages mentioned earlier and a declarative language like SQL.
Spark Streaming has state-based operations like its updateStateByKey(func) that allow you to keep an arbitrary state of stream data. In order to use state operations though, you have to define the state yourself and specify the operations you’ll perform on the state. You can also persist stream data by caching or checkpointing to carry out stateful transformations on them. Checkpointing enhances Spark Streaming's ability to recover from failures by saving either streaming metadata or generated RDDs to reliable and fault-tolerant storage systems at specific checkpoints.
Unlike Kafka Streams, which has state built into the architecture by default, you have to enable state processes by yourself.
Spark Streaming provides support for sliding windowing. This is a time-based window characterized by two parameters: the window interval (length) and the sliding interval at which each windowed operation will be performed. Compare that to Kafka Streams, which supports four different types of windowing.
You’ve probably already noticed that Spark Streaming has a steep learning curve. Apart from the time it takes to be able to effectively use the tool for your particular use case, you also need to have a good understanding of the other frameworks and tools in the Apache Spark ecosystem to maximize its features and successfully build, debug, and deploy your Spark applications. On the other hand, the support for many programming languages makes it an attractive proposition since it naturally blends with different skill sets.
Like Kafka Streams, Spark Streaming is also covered by the Apache Software Foundation 2.0 license. Even though the API has detailed documentation and a community that still uses it, Spark Streaming will remain in the past for Apache thanks to its focus on Spark Structured Streaming. Don’t expect new updates or issue fixes from the developing community.
To recap, here’s a high level view at the differences between Kafka Streams and Spark Streaming:
As far as data streaming technologies go, Kafka Streams and Spark Streaming are as good as it gets. However, while Spark Streaming edges out Kafka Streams on many metrics, Kafka Streams is extremely easy to deploy and has a shallow learning curve. Of course, Spark Streaming is a better solution in a few particular situations, say, if you have multiple data sources or need to combine batch processing with streaming pipelines.
If you’re looking for a way to integrate seamlessly with either Kafka Streaming or Spark Streaming, check out Redpanda. It’s a top-of-the-line streaming data platform that’s already API-compatible with Kafka, and you can easily stream your data to Apache Spark from Redpanda for processing.
Redpanda provides you with a Kafka API that delivers up to 10x faster data transfer with fewer nodes and a much simpler deployment. It’s built without dependencies and can reduce your total costs by up to 6x compared to Kafka—without sacrificing your data’s reliability or durability.
To learn more about Redpanda, check out our documentation and browse the Redpanda blog for tutorials and guides on how to easily integrate with Redpanda. For a more hands-on approach, take Redpanda's free Community edition for a spin!
If you get stuck, have a question, or just want to chat with our solution architects, core engineers, and fellow Redpanda users, join our Redpanda Community on Slack.
You can't scale what you can't trust. A governance layer fixes that.

Your lakehouse mirrors the database, instantly.

What is it, why enterprises need it, and how to evaluate one
Subscribe to our VIP (very important panda) mailing list to pounce on the latest blogs, surprise announcements, and community events!
Opt out anytime.