





Bridge Queries in Redpanda SQL
Have your real-time cake and eat your analytics too
Move over, Kafka Connect. Say hello to efficient, easy-to-use data streaming with Snowflake using Redpanda Connect








To get started with the new Redpanda Snowflake Connector, you need to have an account with both Redpanda and Snowflake. Once registered, you can check out the Quickstart guide for a complete introduction and walkthrough.
Redpanda Connect leverages Snowpipe Streaming to craft data pipelines. To do this, it uses a growing portfolio of input connectors and a variety of transforms using the custom transformation language, bloblang. Redpanda Connect can read data, perform small transformations, and then write the data to Snowflake, managing the schema automatically for you. A step-by-step guide is available in the Snowpipe Streaming with Redpanda Connect Quickstart guide.
Redpanda Connect has been benchmarked against Kafka Connect and the results show that Redpanda Connect can produce data at double the throughput on the same hardware. This was tested by provisioning a Tier 2 cluster on GCP in Redpanda Cloud and creating a Redpanda Connect pipeline to produce data into a topic as fast as it would go.
The Redpanda Snowflake Connector helps developers streamline how they build data-intensive applications on Snowflake. It allows you to create a production-ready, efficient ingestion pipeline in a few lines of YAML. The same approach works for the dozens of input sources supported by Redpanda Connect, like MQTT server, Google Pub/Sub, or Postgres CDC.
Redpanda has announced a new feature called Snowflake Connector in Redpanda Connect. This new connector is now available on all major cloud providers including AWS, GCP, and Microsoft Azure. It offers up to 2X higher throughput on the same hardware compared to Kafka Connect, enabling fast, efficient, and flexible data streaming for Snowflake customers.
Redpanda is once again redefining how developers approach streaming and data integration. We’re excited to announce our latest game-changer: Snowflake Connector in Redpanda Connect — now available on all major cloud providers: AWS, GCP, and Microsoft Azure.
In industries that hinge on real-time analytics, milliseconds can mean the difference between seizing opportunities or falling behind. Redpanda’s new Snowflake connector delivers up to 2X higher throughput on the same hardware compared to Kafka Connect, which means fast, efficient, and flexible data streaming for Snowflake customers.
For the uninitiated, Snowflake's Snowpipe Streaming is a native feature that enables high-throughput data ingestion into a destination table, supporting up to 5 GB/s with exactly-once semantics and P99 latencies of five seconds or less.
Snowpipe streaming can simplify a world of use cases, including:
Simplicity is a core principle at Snowflake, so naturally, they found a kindred soul in Redpanda. In this post, we walk through how we designed our new Snowflake connector to be lightning-fast and ultra-flexible and outline our benchmark against Kafka Connect so you can put Redpanda Connect to the test yourself.
Snowpipe Streaming is designed for rowsets with variable arrival frequency, focusing on lower latency and cost for smaller data sets. This helps data workers stream rows into Snowflake without requiring files with a more attractive cost/latency profile.
Redpanda Connect can now leverage Snowpipe Streaming to craft data pipelines using a growing portfolio of input connectors and endless possibilities of transforms using our custom transformation language, bloblang (or any of our other processors).
To create our new Snowpipe Streaming output in Redpanda Connect, we collaborated closely with the Snowflake team to rewrite their Java SDK into Golang. At the same time, we improved the performance with parallelized file construction, optimized assembly to compute query engine statistics, and tightly benchmarked validation routines.
The flexibility of Redpanda Connect allows for easily shifting transformations left in your data pipelines, saving you serious cash. Here's a birds-eye view of a data pipeline that does exactly that — reads data from Redpanda, does some small transforms then writes the data to Snowflake, managing the schema automatically for you.
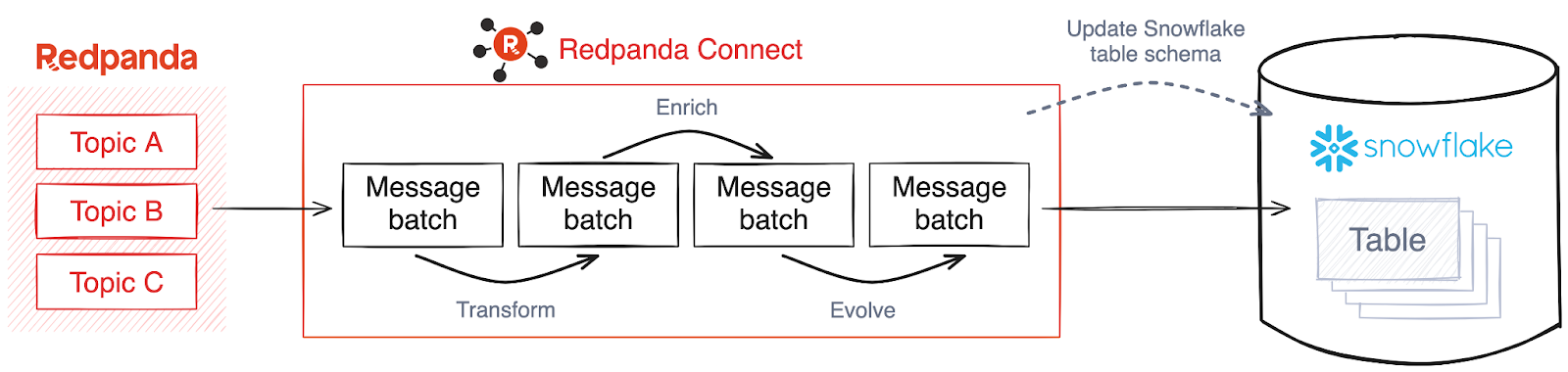
In the demo, we walk through how to stream data from Redpanda, perform some light processing, write the data into Snowflake, automatically create the table in Snowflake, and evolve the table as the data schema changes.
Watch the demo of our new Snowflake connector here, or try it out yourself with this step-by-step Snowpipe Streaming with Redpanda Connect Quickstart guide.
Now that you've seen how easy it is to run Redpanda Connect, let's walk through the benchmarking we did to prove our new connector can actually produce data at double the throughput on the same hardware.
We provisioned a Tier 2 cluster on GCP in Redpanda Cloud and created a Redpanda Connect pipeline to produce data into a topic as fast as it would go. The load generation pipeline was pushing zstd compressed JSON at ~28 MiB/second, running the following configuration:
input:
generate:
mapping: |
root = {
"bar": random_int(),
"baz": uuid_v4(),
"foo": uuid_v4(),
"host": nanoid(64),
"host2": nanoid(54),
"id": counter(),
"more": {
"bar": nanoid(54),
"baz": ksuid(),
"host": "fastpanda",
"nested": {
"id": snowflake_id(),
"qux": counter(),
"thud": uuid_v4(),
"timestamp": now()
},
"snowflake_id": snowflake_id(),
"timestamp": now()
},
"nested": {
"id": uuid_v4(),
"more": {
},
"qux": random_int(),
"thud": uuid_v4(),
"timestamp": now()
},
"aa": timestamp_unix_milli(),
"ab": timestamp_unix_nano(),
"abar": random_int(),
"abaz": ksuid(),
"ahost": ulid(),
"areally_long_key_what": random_int(),
"asnowflake_id": snowflake_id(),
"atimestamp": now(),
"snowflake_id": snowflake_id(),
"time?": now(),
"timestamp": now()
}
interval: 0
count: 0
batch_size: 128
auto_replay_nacks: true
pipeline:
processors: []
output:
kafka_franz:
seed_brokers: ["${REDPANDA_BROKER}"]
topic: "random_json_data"
tls: {enabled: true}
compression: zstd
sasl:
- mechanism: SCRAM-SHA-256
username: ${USER}
password: ${PASSWORD}
max_in_flight: 1024Next, we spun up Kafka Connect and Redpanda Connect on identical hardware c4-standard-4, which has 4 vCPU and 16 GiB of RAM.
For Kafka Connect, we downloaded version 3.0.0 of snowflakeinc-snowflake-kafka-connector.jar, then ran the following shell scripts — one to run Kafka Connect in a docker container, another to submit the tasks to run the Snowflake Connect using Snowpipe Streaming and enable schematization.
#!/bin/bash
set -x
CONFIG=$(cat <<EOF
key.converter=org.apache.kafka.connect.converters.ByteArrayConverter
value.converter=org.apache.kafka.connect.converters.ByteArrayConverter
group.id=connectors-cluster
offset.storage.topic=_internal_connectors_offsets
config.storage.topic=_internal_connectors_configs
status.storage.topic=_internal_connectors_status
config.storage.replication.factor=-1
offset.storage.replication.factor=-1
status.storage.replication.factor=-1
offset.flush.interval.ms=1000
producer.linger.ms=50
producer.batch.size=131072
EOF)
echo -n "$PASSWORD" > password.txt
docker run \
--name kafka-connect \
--rm \
--env "CONNECT_BOOTSTRAP_SERVERS=$REDPANDA_BROKER" \
--env "CONNECT_CONFIGURATION=$CONFIG" \
--env "CONNECT_GC_LOG_ENABLED=false" \
--env "CONNECT_LOG_LEVEL=info" \
--env "CONNECT_HEAP_OPTS=-Xms4G -Xmx4G" \
--env "CONNECT_SASL_MECHANISM=scram-sha-256" \
--env "CONNECT_SASL_USERNAME=$USER" \
--env "CONNECT_SASL_PASSWORD_FILE=password.txt" \
--mount "type=bind,readonly,src=$PWD/password.txt,dst=/opt/kafka/connect-password/password.txt" \
--env "CONNECT_TLS_ENABLED=true" \
--env "CONNECT_METRICS_ENABLED=true" \
--env "CONNECT_PLUGIN_PATH=/opt/kafka/connect-plugins" \
--mount "type=bind,readonly,src=$PWD/snowflakeinc-snowflake-kafka-connector-3.0.0/lib/,dst=/opt/kafka/connect-plugins/snowflake-sink" \
--publish "8083:8083" \
docker.redpanda.com/redpandadata/connectors:latest#!/bin/bash
set -x
CONFIG=$(
cat <<EOF
{
"name":"Sink2Snow",
"config":{
"connector.class":"com.snowflake.kafka.connector.SnowflakeSinkConnector",
"tasks.max":"4",
"topics":"random_json_data",
"snowflake.topic2table.map": "random_json_data:MY_KC_TABLE",
"snowflake.ingestion.method": "SNOWPIPE_STREAMING",
"snowflake.enable.schematization": true,
"buffer.count.records":"10000",
"buffer.flush.time":"60",
"buffer.size.bytes":"5000000",
"snowflake.url.name":"${SNOWFLAKE_ACCOUNT}.snowflakecomputing.com:443",
"snowflake.user.name":"ROCKWOODREDPANDA",
"snowflake.role.name": "ACCOUNTADMIN",
"snowflake.private.key":"${SNOWFLAKE_PRIVATE_KEY}",
"snowflake.database.name":"DEMO_DB",
"snowflake.schema.name":"PUBLIC",
"value.converter": "org.apache.kafka.connect.json.JsonConverter",
"value.converter.schemas.enable": false
}
}
EOF
)
curl -X POST localhost:8083/connectors \
-H 'Content-Type: application/json' \
-d "$CONFIG"In Redpanda Connect, we used the latest release v4.45.0, and ran the following configuration file, trying to match the Kafka Connector as best as possible. This includes a dead letter queue, and exactly-once delivery.
input:
kafka:
addresses: ["${REDPANDA_BROKER}"]
tls: {enabled: true}
topics: ["random_json_data"]
consumer_group: "redpanda_connect"
auto_replay_nacks: true
sasl:
mechanism: SCRAM-SHA-256
user: ${USER}
password: ${PASSWORD}
checkpoint_limit: 1
batching:
count: 20000
period: 10s
output:
fallback:
- snowflake_streaming:
account: ${SNOWFLAKE_ACCOUNT}
user: ROCKWOODREDPANDA
role: ACCOUNTADMIN
database: DEMO_DB
schema: PUBLIC
table: MY_RPCN_TABLE
max_in_flight: 8
build_options:
parallelism: 4
chunk_size: 10000
channel_name: partition-${!@kafka_partition}
offset_token: offset-${!"%016X".format(@kafka_offset)}
schema_evolution:
enabled: true
private_key: ${SNOWFLAKE_PRIVATE_KEY}
- retry:
output:
redpanda:
seed_brokers: ["${REDPANDA_BROKER}"]
tls: {enabled: true}
topic: snowflake-dlq
sasl:
- mechanism: SCRAM-SHA-256
username: ${USER}
password: ${PASSWORD}To measure the throughput, we'll measure the number of rows written per second in Snowflake. First, we grab a snapshot of the number of rows and the current timestamp in an SQL worksheet.
SET (RC1, RD1) = (SELECT COUNT(*), CURRENT_TIMESTAMP() FROM MY_RPCN_TABLE);
SET (KC1, KD1) = (SELECT COUNT(*), CURRENT_TIMESTAMP() FROM MY_KC_TABLE);Then, we can wait approximately one minute, and run the following SQL to get the number of rows per second ingested, an estimate of the number of MBs/second, and the duration of our test run for each tool.
SELECT
(COUNT(*)-$KC1)/DATEDIFF(second, $KD1, CURRENT_TIMESTAMP())*1000/1000000 as mbs,
(COUNT(*)-$KC1)/DATEDIFF(second, $KD1, CURRENT_TIMESTAMP()) as rps,
DATEDIFF(second, $KD1, CURRENT_TIMESTAMP()) as test_duration_seconds,
'Kafka Connect' as tool
FROM MY_KC_TABLE
UNION
SELECT (COUNT(*)-$RC1)/DATEDIFF(second, $RD1, CURRENT_TIMESTAMP())*1000/1000000 as mbs,
(COUNT(*)-$RC1)/DATEDIFF(second, $RD1, CURRENT_TIMESTAMP()) as rps,
DATEDIFF(second, $RD1, CURRENT_TIMESTAMP()) as test_duration_seconds,
'Redpanda Connect' as tool
FROM MY_RPCN_TABLE;We got the following results:
The verdict? Our benchmark shows that Redpanda Connect achieved ~2X the throughput on the same hardware compared to Kafka Connect.
As companies build high-throughput applications on data lakehouses, we’re excited to see how our new Redpanda Snowflake Connector helps developers streamline how they build data-intensive applications on Snowflake.
This post showcased how to ingest data using Snowpipe Streaming using Redpanda Connect so you can create a production-ready, efficient ingestion pipeline in a few lines of YAML. The same approach works for the dozens of input sources supported by Redpanda Connect, like MQTT server, Google Pub/Sub, or Postgres CDC. (Note that the previous Snowflake connector snowflake_put will be deprecated, so we encourage all users to switch to snowflake_streaming.)
To get started with the new Redpanda Snowflake Connector, you'll need both an account with Redpanda and with Snowflake. Once you're registered, check out the Quickstart guide. For a complete introduction and walkthrough. join our webinar all about data streaming to Snowflake.
Subscribe to our VIP (very important panda) mailing list to pounce on the latest blogs, surprise announcements, and community events!
Opt out anytime.

