




Full CDC semantics land in the Iceberg output for Redpanda Connect
Your lakehouse mirrors the database, instantly.
Learn when to use an event-driven, layered, or microservice architecture pattern









There are several common software architecture patterns. The Layered (n-tier) architecture divides an application into single-purpose layers such as presentation, business logic, and data access to enhance modularity, maintainability, and reusability. The Event-driven architecture focuses on the production, detection, consumption, and reaction to events, allowing loose coupling, scalability, and responsiveness. The Microservices architecture decomposes a system into individually deployable services, promoting scalability, fault isolation, and team autonomy.
The benefits of a layered architecture pattern include excellent separation of concerns, easier maintenance, testing, and development, and clear abstraction. However, the limitations include the potential for the application to be monolithic, scalability implications, and the impact of tightly coupled layers or tiers. It's also important to consider the dependency between layers when modifying the codebase.
Event-driven architecture (EDA) encourages loose coupling between components through asynchronous messaging, making systems more modular and components easier to update and change. EDA also has excellent horizontal scalability potential, and workloads running in an EDA application are intrinsically asynchronous, which can be beneficial for long-running or expensive jobs.
Layered architecture is popular for traditional web applications and can be leveraged either on-premise or with common infrastructure-as-a-service (IaaS) cloud providers like AWS, GCP, and Azure. It's often a good choice for web applications and an effective choice for migrating on-premise applications to the cloud with minimal changes.
Software architecture patterns are an essential part of building complex systems. These patterns represent the different well-known ways systems can be built, typically with particular characteristics in mind.
Most common software architecture patterns result from extensive refinement over many years and, as such, can serve as a solid foundation when you need to build a system with particular traits. Some patterns offer superior availability, while others might be better suited for modularity. There is no single "best" pattern for software architecture, as the suitability of a given pattern will depend on your requirements and use case.
In this post, you'll learn about three different software architecture patterns to help you choose which is right for you. You’ll get an overview of each pattern, when it’s commonly used, as well as its benefits and limitations. Very handy stuff—so let’s get started.
Software architecture patterns are like recipes or blueprints for your applications. They describe different ways your application can be structured to achieve specific outcomes or overcome and mitigate limitations.
As a builder of complex systems, you should be familiar with various architectural patterns as well as their benefits and limitations, because this will equip you to make better decisions when it comes to building a system that needs to solve more advanced problems. For instance, consider the following architectural patterns and a high-level overview of their purpose:
However, being familiar with a range of architectural patterns is only the first step. To effectively leverage this knowledge, you need to know how to choose the right pattern for your use case, which necessitates a deeper familiarity with the benefits and limitations of each architectural pattern.
To make an informed decision about which architectural pattern is suitable for your use case, you need to have an in-depth understanding of each pattern you are considering. This section examines the above patterns to give you an idea of what to look for when making this decision.
In a layered architecture, the application is divided into several discrete layers and tiers, where layers represent logical divisions of responsibility and tiers correspond to the physical or deployment aspects of the system. In practice, it's common for tiers and layers to align so they map directly.
As an example of where you might see this pattern in the real world, consider a simple web application that follows the Model-View-Controller (MVC) pattern. This application might be divided into three layers: user interface, business logic, and data access. Each of these layers belongs to a tier, like so:
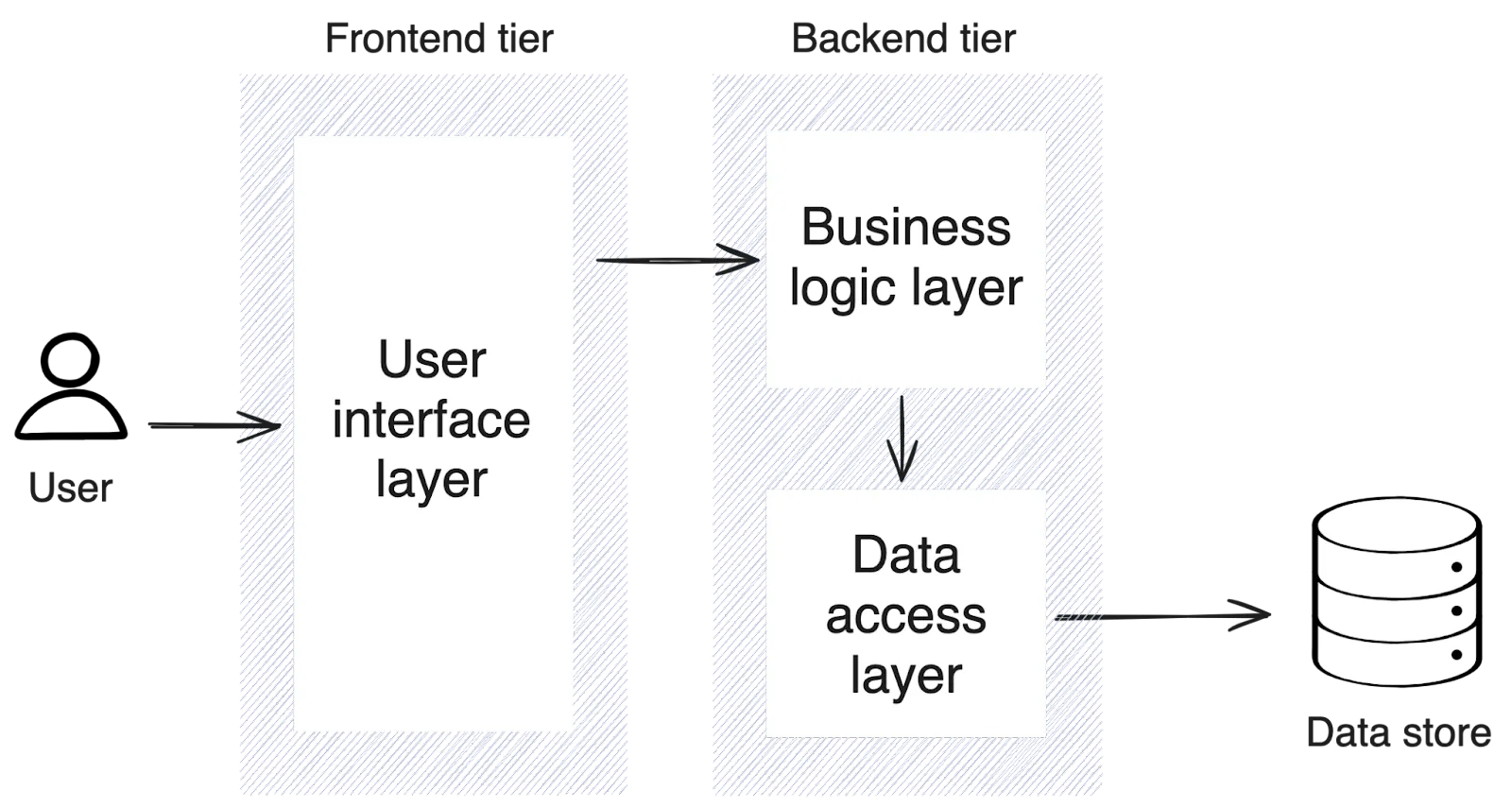
Layered architecture diagram
The layered architecture pattern has several benefits, largely stemming from the excellent separation of concerns. Because the application is split into single-responsibility layers, common development tasks like maintenance, testing, and development become easier. In a well-designed system, a developer can focus on a specific layer without much context about how the layers above and below it work.
It's also easier to reason about the system thanks to clear abstraction. The delineated nature of this architecture makes it easier for developers to understand what is going on at each level without needing to concern themselves with the intricacies of other layers. Layers can also be tested in isolation, improving overall testability and quality assurance.
The layered architecture pattern also has some limitations to consider when considering its suitability. Notably, it's common for the application—or at least each layer—to be monolithic. This means it's impossible to deploy independent features like you can with a microservices architecture.
A monolithic application also has scalability implications. If a particular feature on your application receives a lot more traffic than other features, you cannot scale this feature individually and will instead need to scale the entire application or layer.
Another limiting factor is the impact of tightly coupled layers or tiers. It's particularly important to consider this impact when dealing with a more complex layered application with several layers or tiers.
Any time you have a layer that directly calls another lower layer, you need to be mindful of this dependency when modifying the codebase. This can be somewhat mitigated through asynchronous messaging or by adopting a stricter closed-layer architecture, in which layers are only able to call the next layer immediately down.
However, while introducing a closed-layer architecture can limit dependency between layers, it can also introduce additional overhead if some simply forward calls to lower layers due to this design decision.
Layered architecture is popular for traditional web applications and can be leveraged either on-premise or with common infrastructure-as-a-service (IaaS) cloud providers like AWS, GCP, and Azure. When implemented in this way, layered architecture applications will often be deployed with each tier running on a different set of virtual machines (VMs) or by leveraging managed infrastructure, such as managed database instances.
Layered architecture is therefore often a good choice for web applications and an effective choice for migrating on-premise applications to the cloud with minimal changes.
The idea behind an event-driven architecture (EDA) is that system components will be loosely coupled through asynchronous messages. Components in an EDA can be broadly categorized as producers, components that push messages to the message broker, or consumers, components that receive messages and execute a corresponding workload.
Consumers typically subscribe to particular topics, which are used to aggregate messages related to a specific topic. By doing this, a consumer can receive only the messages relevant to its capabilities or domain while leaving other messages for their corresponding consumers.
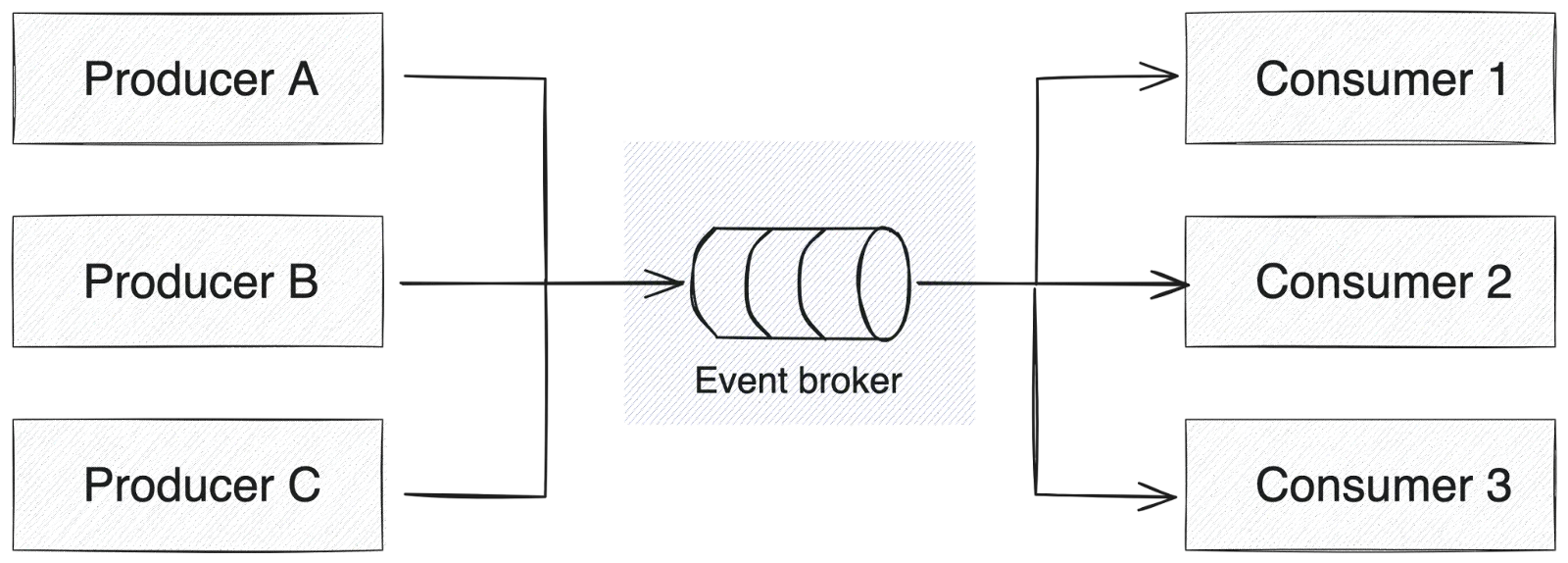
Event-driven architecture diagram
EDA has several benefits that make it an appealing choice for certain applications. One of the key traits of EDA is that it encourages loose coupling between components through asynchronous messaging. This makes systems more modular and components easier to update and change.
Another advantage is EDA's excellent horizontal scalability potential. Since consumers simply receive messages from the message broker, scaling up the number of consumers for a specific topic becomes very straightforward, effectively handling increased workloads.
Workloads running in an EDA application also have the benefit of being intrinsically asynchronous. This can be beneficial for long-running or expensive jobs, as it allows components to handle events at their own pace, smoothing out request spikes and allowing you to handle larger workloads when demand on the application is not as high.
EDA is not without its limitations, however. Most of the drawbacks of EDA stem from its asynchronous nature. This architecture is inherently more complex than layered architecture due to having more moving pieces. In a simple EDA application, you would likely have at least one producer and consumer conceptually linked by the message broker.
To understand the broader scope of the application, you need to understand each subordinate component. In a real-world application, there would likely be multiple producers and consumers, each writing to and reading from the pool of messages.
In addition, because workloads are carried out asynchronously, there is extra complexity relating to consistency, error handling, and debugging.
Since workloads will be handled at some point after being written to the queue, you will typically be limited to an eventual consistency model rather than strong consistency, which may be more desirable in some applications such as financial, healthcare, and other mission-critical applications where it's vital that data is reliable and up-to-date at all times. Because workloads can even be split across multiple processes, error handling and debugging become more complex to reason about, making observability an essential trait in systems that use EDA.
EDA is most often suitable for applications where loose coupling is highly desirable or complex workflows and integrations are present. EDA naturally promotes loose coupling between components by having producers and consumers avoid direct interactions, instead relying on the message broker.
The loosely coupled nature of EDA also makes it a good fit for complex workflows by allowing components to rely on event choreography rather than tightly coupled integrations. This ultimately makes the workflows and integrations more flexible and often easier to implement. EDA is also an excellent choice for applications that need a high degree of real-time reactivity, as workflows execute as events are received rather than on a polling basis.
For example, EDA would work well for a real-time chat application, as it would allow messages to be pushed to topics representing recipients or groups. These messages would subsequently be consumed by client applications and displayed to their intended recipients.
When implementing EDA, your message broker is a key component of your architecture. There are many ready-made solutions available, each with its own characteristics. Consider Redpanda, for instance. Redpanda is a powerful, Kafka-API-compatible streaming data platform designed to give you the best possible performance. Using a highly optimized platform like Redpanda is a good idea if you want to get the most out of your EDA application.
In the microservices architecture pattern, a larger application's units of functionality are implemented as independently deployable mini-applications, or microservices. Each microservice has its own domain of responsibility and frequently needs to call on other microservices internally to access the functionality needed to complete a request.
Microservices are often used for large, complex applications, typically as a migration path away from a more monolithic architecture. It's fairly common for applications that are composed of multiple microservices to also leverage an API gateway to abstract the specifics of the underlying microservices away from consumers:
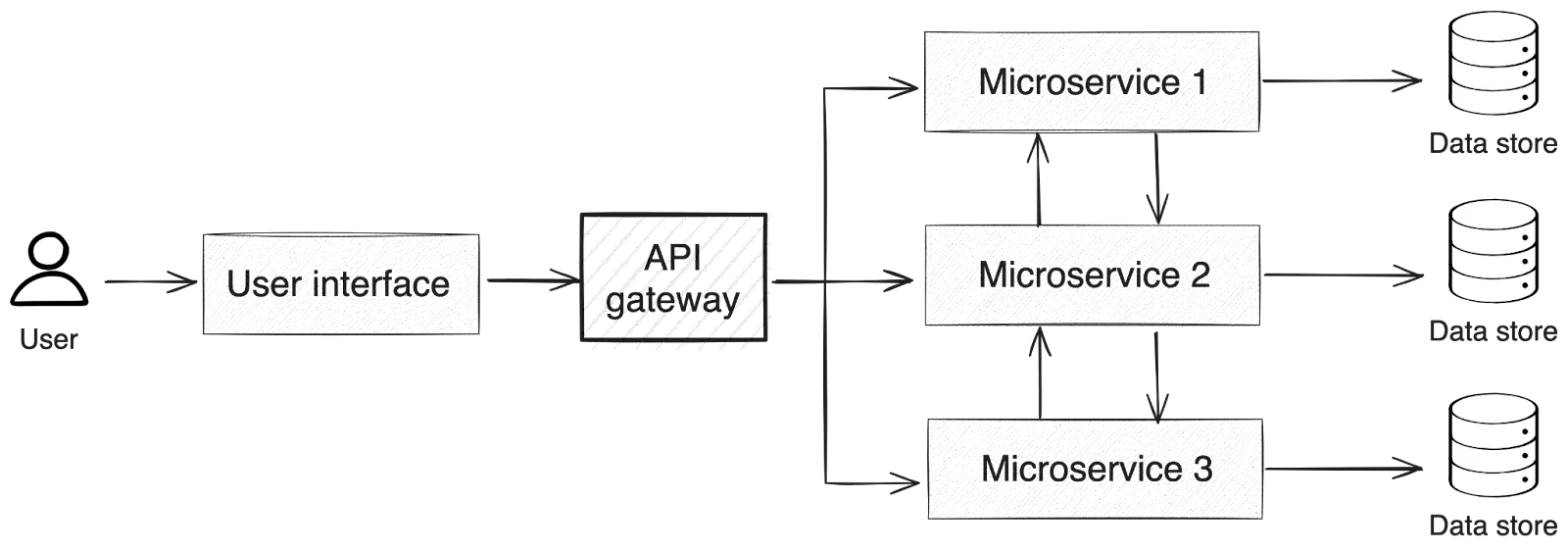
Microservices architecture diagram
One of the key benefits of microservices is scalability. Because each service can be modified, deployed, and scaled independently of the others when paired with containers and a container orchestrator like Kubernetes, it becomes almost trivial to scale specific microservices that might receive more traffic than others. This can lead to some significant cost savings by allowing you to allocate resources where they are actually beneficial, as opposed to the monolithic approach of scaling an entire application when only a subset of its functionalities might be experiencing heavy traffic.
As microservices are independent of each other, they are also more fault tolerant. If one service suffers a fault, the failure does not necessarily need to impact the rest of the system if the microservices have been designed to contain failures within individual components.
Finally, because each microservice can be treated like its own mini-application, there are benefits for large teams. Large teams can often suffer productivity losses in monolithic applications when everyone is changing the same code simultaneously. By splitting functionalities into microservices and assigning specific teams to each microservice, teams can make changes without worrying about potential conflicts. In addition, teams can also use different technology stacks for individual microservices, allowing functionality to be implemented with whatever technology makes the most sense for the service's specific requirements.
Because microservices are distributed systems, they introduce complexity stemming from the need for services to communicate with one another. Concerns like eventual consistency and managing network faults can increase the cognitive load that developers face when working with these systems. Similarly, managing data integrity and consistency across multiple services can be challenging. Proper data synchronization requires careful design and consideration, adding further complexity to the system.
Microservice applications also have additional overhead compared to monolithic applications. This overhead can emerge in operations and engineering. On the operational side, there are concerns such as monitoring, logging, and deployment complexity. On the software engineering side, developers need to manage increased complexity for development and testing efforts.
The microservices pattern is a good fit for complex and evolving applications, large teams, and when scalability is essential.
For complex applications, having the ability to evolve and improve individual services in an isolated way can be beneficial. It can also be beneficial to have the ability to implement particular services using whatever technology is most suitable, rather than just whatever technology the rest of the application is built with.
Large teams benefit from the microservices pattern because it allows them to work autonomously on their services in parallel with other teams doing the same. This can lead to productivity and efficiency gains compared to similarly large teams working on a monolithic application.
Microservices are also a good choice for applications where scalability is anticipated to be highly important. The ability to scale individual services based on traffic demands without allocating more resources to less-used services can be a compelling point when considering architectural patterns.
There are many factors to consider when deciding which architectural pattern is most suitable for your use case. There is no single "best pattern" that solves every use case. Instead, you need to consider your requirements and decide on an architecture—or combination of architectures—that makes sense for you based on the benefits and limitations they bring.
If you're considering an event-driven architecture, you'll also need a suitable message broker. This has traditionally been the open-source Apache Kafka®, but with modern applications demanding higher throughputs, Redpanda is the streaming data engine of choice that serves as a cost-efficient Kafka replacement—but with 10x better performance and much less complexity.
To play around with Redpanda, sign up for a free trial! If you have questions or want to chat with the team, join the Redpanda Community on Slack.
Subscribe to our VIP (very important panda) mailing list to pounce on the latest blogs, surprise announcements, and community events!
Opt out anytime.

