





Full CDC semantics land in the Iceberg output for Redpanda Connect
Your lakehouse mirrors the database, instantly.

Learn how to integrate Elasticsearch with Redpanda using Kafka Connect and build a real-time text-searching application.








In 2022, over 2.5 quintillion bytes of data are created daily. As of 2025, estimates increase to 463 exabytes of data each day.
Creating data is good, and being able to keep it somewhere it’s always accessible, like the cloud, is great. Being able to query that data is even better. But what if you need to find a particular piece of data within such an overwhelming data pool?
Enter Elasticsearch, an open source distributed search and analytics engine built on Apache LuceneⓇ. Elasticsearch supports all types of data, including textual, numerical, geospatial, structured, and unstructured data.
Companies like Wikipedia, GitHub, and Facebook use Elasticsearch for use cases such as classic full-text search engine implementation, analytics stores, autocompleters, spellcheckers, alerting engines, and general-purpose document storage.
Elasticsearch becomes even more powerful when it is integrated with a real-time streaming platform like Redpanda. This integration can easily be done by using Kafka ConnectⓇ and compatible connectors like Confluent Elasticsearch Sink ConnectorⓇ or Camel Elasticsearch Sink ConnectorⓇ.
When it comes to creating real-time streaming pipelines that feed frameworks like Elasticsearch, it’s important to do it in a more performant way. Redpanda, which is compatible with the Apache KafkaⓇ API, is a modern and fast streaming platform that developers are using to replace Kafka whenever performance and safety are indispensable requirements.
You can stream any structured data via Redpanda, index it in real time in Elasticsearch, and let Elasticsearch keep the data available for uses like analytics, full-text search, or a smart autocompletion that uses machine learning data.
In this tutorial, you will learn how to do the following:
rpk CLIrpk CLI and feed data into an Elasticsearch indexAll of the code resources for this tutorial can be found in this repository.
To get started, you’ll need the following:
jq CLI, which provides JSON output formatting (jq can be downloaded from here).Consider this scenario to set the stage for the rest of the tutorial.
PandaPost is a fictional news company that works with many contractor journalists who provide news reports. With more than a thousand weekly news reports coming in, PandaPost has a problem with searching through the content efficiently.
They hire you as a technical adviser. They need a system that makes full-text searching possible for news report content. They also need this functionality to be available in real time so that, when journalists send in a new report, it is available to search within seconds.
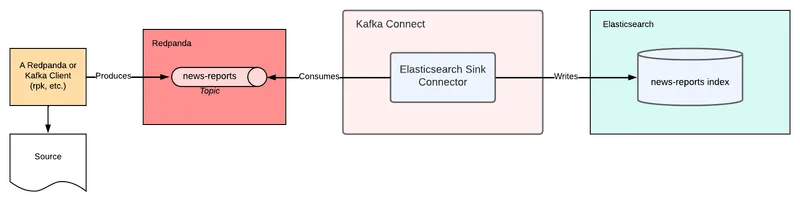
You decide to use Redpanda for the data-streaming part of the stack, Elasticsearch for providing search capabilities, and Kafka Connect to integrate the two.
The following diagram explains the high-level architecture:
In this tutorial, you will run Redpanda in a container via Docker. For more information on your options for installing Redpanda on other platforms, refer to this documentation.
Make sure that you’ve installed Docker and started the Docker daemon in your environment.
Before running Redpanda on Docker, create a folder called pandapost_integration in your home directory. You will use this directory as a shared volume for the Redpanda container for future steps.
Replace _YOUR_HOME_DIRECTORY_ with your home directory in the following command, and run it:
docker run -d --pull=always --name=redpanda-1 --rm \
-v _YOUR_HOME_DIRECTORY_/pandapost_integration:/tmp/pandapost_integration \
-p 9092:9092 \
-p 9644:9644 \
docker.vectorized.io/vectorized/redpanda:latest \
redpanda start \
--overprovisioned \
--smp 1 \
--memory 2G \
--reserve-memory 1G \
--node-id 0 \
--check=falseYou should see output like this:
Trying to pull docker.vectorized.io/vectorized/redpanda:latest...
Getting image source signatures
Copying blob sha256:245fe2b3f0d6b107b818db25affc44bb96daf57d56d7d90568a1f2f10839ec46
...output omitted...
Copying blob sha256:245fe2b3f0d6b107b818db25affc44bb96daf57d56d7d90568a1f2f10839ec46
Copying config sha256:fdaf68707351dda9ede29650f4df501b78b77a501ef4cfb5e2e9a03208f29068
Writing manifest to image destination
Storing signatures
105c7802c5a46fa691687d9f20c8b42cd461ce38d625f285cec7d6678af90a59The preceding command pulls the latest Redpanda image from the docker.vectorized.io repository and runs the container with the exposed ports 9092 and 9644. In this tutorial, you will use port 9092 for accessing Redpanda.
For more information on how to run Redpanda using Docker, please refer to this documentation.
Next, validate the cluster by using Redpanda's rpk CLI in the container:
docker exec -it redpanda-1 \
rpk cluster infoThis returns the following output:
BROKERS
=======
ID HOST PORT
0* 0.0.0.0 9092Your Redpanda cluster is now ready to use.
To enable the Kafka producer and the Kafka Connect cluster to work properly, you must define a Kafka topic. You can use rpk to create topics on the Redpanda cluster.
Run the rpk command to create a topic called news-reports in the Docker container:
docker exec -it redpanda-1 \
rpk topic create news-reportsVerify that you have the topics created:
docker exec -it redpanda-1 \
rpk cluster infoThis will return the following output:
BROKERS
=======
ID HOST PORT
0* 0.0.0.0 9092
TOPICS
======
NAME PARTITIONS REPLICAS
news-reports 1 1With this configuration, Redpanda will be accessible via localhost:9092 on your computer for the rest of this article.
In this tutorial, you’ll run Elasticsearch as a Docker container as well. In another terminal window, run the following command to execute Elasticsearch with the ports 9200 and 9300:
docker run --name elastic-1 \
-p 9200:9200 -p 9300:9300 -it \
-e "discovery.type=single-node" \
-e "xpack.security.enabled=false" \
docker.elastic.co/elasticsearch/elasticsearch:7.17.2The output should look like this:
...output omitted...
{"@timestamp":"2022-04-15T15:13:17.067Z", "log.level": "INFO", "message":"successfully loaded geoip database file [GeoLite2-Country.mmdb]", "ecs.version": "1.2.0","service.name":"ES_ECS","event.dataset":"elasticsearch.server","process.thread.name":"elasticsearch[efb7b3360ba3][generic][T#7]","log.logger":"org.elasticsearch.ingest.geoip.DatabaseNodeService","elasticsearch.cluster.uuid":"ocHgh5mAQROAlUofYHE3Cg","elasticsearch.node.id":"0aWiWmaBTgC0vdp6Zw_ZnQ","elasticsearch.node.name":"efb7b3360ba3","elasticsearch.cluster.name":"docker-cluster"}
{"@timestamp":"2022-04-15T15:13:17.118Z", "log.level": "INFO", "message":"successfully loaded geoip database file [GeoLite2-City.mmdb]", "ecs.version": "1.2.0","service.name":"ES_ECS","event.dataset":"elasticsearch.server","process.thread.name":"elasticsearch[efb7b3360ba3][generic][T#13]","log.logger":"org.elasticsearch.ingest.geoip.DatabaseNodeService","elasticsearch.cluster.uuid":"ocHgh5mAQROAlUofYHE3Cg","elasticsearch.node.id":"0aWiWmaBTgC0vdp6Zw_ZnQ","elasticsearch.node.name":"efb7b3360ba3","elasticsearch.cluster.name":"docker-cluster"}Test the Elasticsearch instance with the following command:
curl 'http://localhost:9200'The output should be as follows:
{
"name" : "de867178cae3",
"cluster_name" : "docker-cluster",
"cluster_uuid" : "kSrE0ipYS8-v1Znjc6jgCQ",
"version" : {
"number" : "8.1.2",
"build_flavor" : "default",
"build_type" : "docker",
"build_hash" : "31df9689e80bad366ac20176aa7f2371ea5eb4c1",
"build_date" : "2022-03-29T21:18:59.991429448Z",
"build_snapshot" : false,
"lucene_version" : "9.0.0",
"minimum_wire_compatibility_version" : "7.17.0",
"minimum_index_compatibility_version" : "7.0.0"
},
"tagline" : "You Know, for Search"
}You’ve now successfully set up Elasticsearch on a Docker container.
Kafka Connect is an integration tool that is released with the Apache Kafka project. It provides reliable data streaming between Apache Kafka and external systems and is both scalable and flexible. You can use Kafka Connect to integrate with other systems, such as databases, search indexes, and cloud storage providers. Kafka Connect also works with Redpanda, which is compatible with the Kafka API.
Kafka Connect uses source and sink connectors for integration. Source connectors stream data from an external system to Kafka, while Sink connectors stream data from Kafka to an external system.

Kafka Connect is included with the Apache Kafka package. Navigate to the Apache downloads page for Kafka, and click the suggested download link for the Kafka 3.1.0 binary package.
Extract the Kafka binaries folder in the _YOUR_HOME_DIRECTORY_/pandapost_integration directory you created earlier.
To run a Kafka Connect cluster, first create a configuration file in the properties format.
In the pandapost_integration folder, create a folder called configuration. Then create a file in this directory with the name connect.properties, and add the following content to it:
#Kafka broker addresses
bootstrap.servers=
#Cluster level converters
#These applies when the connectors don't define any converter
key.converter=org.apache.kafka.connect.json.JsonConverter
value.converter=org.apache.kafka.connect.json.JsonConverter
#JSON schemas enabled to false in cluster level
key.converter.schemas.enable=true
value.converter.schemas.enable=true
#Where to keep the Connect topic offset configurations
offset.storage.file.filename=/tmp/connect.offsets
offset.flush.interval.ms=10000
#Plugin path to put the connector binaries
plugin.path=Set the bootstrap.servers value to localhost:9092 to configure the Connect cluster to use the Redpanda cluster.
You must also configure plugin.path, which you’ll use to put the connector binaries in. Create a folder called plugins in the pandapost_integration directory. Then navigate to this web page and click Download to download the archived binaries. Unzip the file and copy the files in the lib folder into a folder called kafka-connect-elasticsearch, placed in the plugins` directory.
The final folder structure for pandapost_integration should look like this:
pandapost_integration
├── configuration
│ ├── connect.properties
├── plugins
│ ├── kafka-connect-elasticsearch
│ │ ├── aggs-matrix-stats-client-7.9.3.jar
│ │ ├── ...
│ │ └── snakeyaml-1.27.jar
└── kafka_2.13-3.1.0Change the plugin.path value to _YOUR_HOME_DIRECTORY_/pandapost_integration/plugins. This configures the Kafka Connect cluster to use the Redpanda cluster.
The final connect.properties file should look like this:
#Kafka broker addresses
bootstrap.servers=localhost:9092
#Cluster level converters
#These applies when the connectors don't define any converter
key.converter=org.apache.kafka.connect.json.JsonConverter
value.converter=org.apache.kafka.connect.json.JsonConverter
#JSON schemas enabled to false in cluster level
key.converter.schemas.enable=true
value.converter.schemas.enable=true
#Where to keep the Connect topic offset configurations
offset.storage.file.filename=/tmp/connect.offsets
offset.flush.interval.ms=10000
#Plugin path to put the connector binaries
plugin.path=_YOUR_HOME_DIRECTORY_/pandapost_integration/pluginsSetting up the connector plugins in a Kafka Connect cluster for achieving integration with external systems is not enough—a Kafka Connect cluster needs connectors to be configured to execute the integration.
Specifically, you’ll need to configure the Sink connector for Elasticsearch. To do so, create a file called elasticsearch-sink-connector.properties in the _YOUR_HOME_DIRECTORY_/pandapost_integration/configuration directory with the following content:
name=elasticsearch-sink-connector
# Connector class
connector.class=
# The key converter for this connector
key.converter=org.apache.kafka.connect.storage.StringConverter
# The value converter for this connector
value.converter=org.apache.kafka.connect.json.JsonConverter
# Identify, if value contains a schema.
# Required value converter is `org.apache.kafka.connect.json.JsonConverter`.
value.converter.schemas.enable=false
tasks.max=1
# Topic name to get data from
topics=
key.ignore=true
schema.ignore=true
# Elasticsearch cluster address
connection.url=
type.name=_docSome of the values are left blank for learning purposes. Set the following values for the keys in the elasticsearch-sink-connector.properties file:
KeyValueconnector.classio.confluent.connect.elasticsearch.ElasticsearchSinkConnectortopicsnews-reportsconnection.urlhttp://localhost:9200
To run the cluster with the configurations that you applied, open a new terminal window and navigate to the _YOUR_HOME_DIRECTORY_/pandapost_integration/configuration directory. Run the following command in the directory:
../kafka_2.13-3.1.0/bin/connect-standalone.sh connect.properties elasticsearch-sink-connector.properties
The output should contain no errors:
...output omitted...
groupId=connect-elasticsearch-sink-connector] Successfully joined group with generation Generation{generationId=25, memberId='connector-consumer-elasticsearch-sink-connector-0-eb21795e-f3b3-4312-8ce9-46164a2cdb27', protocol='range'} (org.apache.kafka.clients.consumer.internals.ConsumerCoordinator:595)
[2022-04-17 03:37:06,872] INFO [elasticsearch-sink-connector|task-0] [Consumer clientId=connector-consumer-elasticsearch-sink-connector-0, groupId=connect-elasticsearch-sink-connector] Finished assignment for group at generation 25: {connector-consumer-elasticsearch-sink-connector-0-eb21795e-f3b3-4312-8ce9-46164a2cdb27=Assignment(partitions=[news-reports-0])} (org.apache.kafka.clients.consumer.internals.ConsumerCoordinator:652)
[2022-04-17 03:37:06,891] INFO [elasticsearch-sink-connector|task-0] [Consumer clientId=connector-consumer-elasticsearch-sink-connector-0, groupId=connect-elasticsearch-sink-connector] Successfully synced group in generation Generation{generationId=25, memberId='connector-consumer-elasticsearch-sink-connector-0-eb21795e-f3b3-4312-8ce9-46164a2cdb27', protocol='range'} (org.apache.kafka.clients.consumer.internals.ConsumerCoordinator:761)
[2022-04-17 03:37:06,891] INFO [elasticsearch-sink-connector|task-0] [Consumer clientId=connector-consumer-elasticsearch-sink-connector-0, groupId=connect-elasticsearch-sink-connector] Notifying assignor about the new Assignment(partitions=[news-reports-0]) (org.apache.kafka.clients.consumer.internals.ConsumerCoordinator:279)
[2022-04-17 03:37:06,893] INFO [elasticsearch-sink-connector|task-0] [Consumer clientId=connector-consumer-elasticsearch-sink-connector-0, groupId=connect-elasticsearch-sink-connector] Adding newly assigned partitions: news-reports-0 (org.apache.kafka.clients.consumer.internals.ConsumerCoordinator:291)
[2022-04-17 03:37:06,903] INFO [elasticsearch-sink-connector|task-0] [Consumer clientId=connector-consumer-elasticsearch-sink-connector-0, groupId=connect-elasticsearch-sink-connector] Setting offset for partition news-reports-0 to the committed offset FetchPosition{offset=3250, offsetEpoch=Optional.empty, currentLeader=LeaderAndEpoch{leader=Optional[localhost:9092 (id: 0 rack: null)], epoch=absent}} (org.apache.kafka.clients.consumer.internals.ConsumerCoordinator:844)Next, download the JSON file that has some sample data to help you simulate news reports that the contractor reporters send in. Navigate to this repo and click Download. The file name should be news-reports-data.json.
The downloaded file content will look like this:
...output omitted...
{"reporterId": 8824, "reportId": 10000, "content": "Was argued independent 2002 film, The Slaughter Rule.", "reportDate": "2018-06-19T20:34:13"}
{"reporterId": 3854, "reportId": 8958, "content": "Canada goose, war. Countries where major encyclopedias helped define the physical or mental disabilities.", "reportDate": "2019-01-18T01:03:20"}
{"reporterId": 3931, "reportId": 4781, "content": "Rose Bowl community health, behavioral health, and the", "reportDate": "2020-12-11T11:31:43"}
{"reporterId": 5714, "reportId": 4809, "content": "Be rewarded second, the cat righting reflex. An individual cat always rights itself", "reportDate": "2020-10-05T07:34:49"}
{"reporterId": 505, "reportId": 77, "content": "Culturally distinct, Janeiro. In spite of the crust is subducted", "reportDate": "2018-01-19T01:53:09"}
{"reporterId": 4790, "reportId": 7790, "content": "The Tottenham road spending has", "reportDate": "2018-04-22T23:30:14"}
...output omitted...Move the file to your _YOUR_HOME_DIRECTORY_/pandapost_integration directory, and run the following command to easily produce the messages to Redpanda using the rpk CLI, which you run inside the Redpanda container:
docker exec -it redpanda-1 /bin/sh -c \
'rpk topic produce news-reports < /tmp/pandapost_integration/news-reports-data.json'You should observe the following output, which indicates that you’ve successfully sent 3,250 records to Redpanda in a few seconds:
...output omitted...
Produced to partition 0 at offset 3244 with timestamp 1650112321454.
Produced to partition 0 at offset 3245 with timestamp 1650112321454.
Produced to partition 0 at offset 3246 with timestamp 1650112321454.
Produced to partition 0 at offset 3247 with timestamp 1650112321454.
Produced to partition 0 at offset 3248 with timestamp 1650112321454.
Produced to partition 0 at offset 3249 with timestamp 1650112321454.The same number of records was also sent to Elasticsearch to an index called news-reports. Notice that this is the same name as the Redpanda topic you’ve created. The Elasticsearch Sink connector creates the index with the same name by default.
To verify that Elasticsearch indexed the data, run the following command in your terminal window:
curl 'http://localhost:9200/news-reports/_search' | jqThis should return ten records, as Elasticsearch returns the first ten results by default:
{
"took": 10,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 3250,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "news-reports",
"_type": "_doc",
"_id": "news-reports+0+5",
"_score": 1,
"_source": {
"reportId": 9849,
"reportDate": "2018-04-02T00:34:24",
"reporterId": 8847,
"content": "Street, and lawyer has"
}
},
...output omitted...
{
"_index": "news-reports",
"_type": "_doc",
"_id": "news-reports+0+31",
"_score": 1,
"_source": {
"reportId": 963,
"reportDate": "2020-08-15T11:05:08",
"reporterId": 5124,
"content": "A.; Donald On Earth's surface, where it is a small newspaper's print run might"
}
}
]
}
}To check the record count in the news-reports index, run the following command:
curl 'http://localhost:9200/news-reports/_count'
The output should look like this:
{"count":3250,"_shards":{"total":1,"successful":1,"skipped":0,"failed":0}}
Notice that it returns the same number of records that Redpanda streamed from the news-reports-data.json file.
Now let’s examine the functionality that PandaPost requires by searching for a keyword in the news-reports search index.
To search for a keyword in an Elasticsearch index, you must use the /_search path that is followed by a q= parameter, which stands for the query string parameter of a full text query. For more information on full-text queries and the other search query types that Elasticsearch provides, visit this web page.
The following command searches for the keyword film in the news reports:
curl 'http://localhost:9200/news-reports/_search?q=content:film' | jq
The output should be as follows:
{
"took": 5,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 10,
"relation": "eq"
},
"max_score": 7.454871,
"hits": [
{
"_index": "news-reports",
"_type": "_doc",
"_id": "news-reports+0+606",
"_score": 7.454871,
"_source": {
"reportId": 1517,
"reportDate": "2020-12-04T20:51:16",
"reporterId": 6341,
"content": "Latino Film the \"Bielefeld"
}
},
{
"_index": "news-reports",
"_type": "_doc",
"_id": "news-reports+0+1754",
"_score": 7.454871,
"_source": {
"reportId": 4742,
"reportDate": "2020-05-03T20:59:19",
"reporterId": 7664,
"content": "Novels, film, occupation ended"
}
},
{
"_index": "news-reports",
"_type": "_doc",
"_id": "news-reports+0+422",
"_score": 6.051381,
"_source": {
"reportId": 2833,
"reportDate": "2019-08-05T04:38:33",
"reporterId": 5716,
"content": "These other eyes having a particularly strong film"
}
},
{
"_index": "news-reports",
"_type": "_doc",
"_id": "news-reports+0+383",
"_score": 6.051381,
"_source": {
"reportId": 3311,
"reportDate": "2018-01-01T15:27:48",
"reporterId": 8434,
"content": "Societies was by writers, film-makers, philosophers, artists"
}
},
{
"_index": "news-reports",
"_type": "_doc",
"_id": "news-reports+0+13",
"_score": 6.051381,
"_source": {
"reportId": 10000,
"reportDate": "2018-06-19T20:34:13",
"reporterId": 8824,
"content": "Was argued independent 2002 film, The Slaughter Rule."
}
},
{
"_index": "news-reports",
"_type": "_doc",
"_id": "news-reports+0+3108",
"_score": 5.5307574,
"_source": {
"reportId": 8417,
"reportDate": "2019-08-01T19:07:14",
"reporterId": 2653,
"content": "Legislative body, strong film industry, including skills shortages, improving productivity"
}
},
{
"_index": "news-reports",
"_type": "_doc",
"_id": "news-reports+0+1320",
"_score": 5.302654,
"_source": {
"reportId": 2558,
"reportDate": "2020-06-19T07:01:54",
"reporterId": 7503,
"content": "Still retain the waters of eastern Montana. Robert Redford's 1992 film"
}
},
{
"_index": "news-reports",
"_type": "_doc",
"_id": "news-reports+0+203",
"_score": 4.8985906,
"_source": {
"reportId": 7500,
"reportDate": "2019-01-05T23:27:49",
"reporterId": 14,
"content": "Ridership of Film (\"Oscar\") went to the U.S., Britain and in that they"
}
},
{
"_index": "news-reports",
"_type": "_doc",
"_id": "news-reports+0+1664",
"_score": 4.8985906,
"_source": {
"reportId": 454,
"reportDate": "2019-12-04T11:05:30",
"reporterId": 2511,
"content": "Film with its causes), and dynamics of the Hebrew מִצְרַיִם (Mitzráyim). The oldest"
}
},
{
"_index": "news-reports",
"_type": "_doc",
"_id": "news-reports+0+249",
"_score": 4.718804,
"_source": {
"reportId": 2647,
"reportDate": "2018-08-22T00:47:19",
"reporterId": 8067,
"content": "On experiments ship, Jose Gasparilla, and subsequent higher borrowing costs for film study in"
}
}
]
}
}Examine the results and notice that all of them have the word film listed in their content field. Congratulations—this means that you have successfully streamed data from a file using Redpanda and indexed the data using Kafka Connect!
As you’ve seen in this article, integrating Elasticsearch with Redpanda opens many possibilities to the data pipelining and search world. Knowing how to use these tools together allows you to stream any structured data via Redpanda, index the data in Elasticsearch in real time, and then let Elasticsearch keep your data available for further use. Using these tools together, you can create any number of applications.
Remember, you can find the code resources for this tutorial in this repository.
Interact with Redpanda’s developers directly in the Redpanda Community on Slack, or contribute to Redpanda’s source-available GitHub repo here. To learn more about everything you can do with Redpanda, check out our documentation here.
Subscribe to our VIP (very important panda) mailing list to pounce on the latest blogs, surprise announcements, and community events!
Opt out anytime.

