





Deploy agents you can trust with centralized AI governance
You can't scale what you can't trust. A governance layer fixes that.
Understand the risks and rewards of data streaming with Kubernetes.








On Kubernetes, Kafka requires two components: the Kafka cluster itself, and a ZooKeeperⓇ cluster to handle elections, membership, service state, configuration data, ACLs, and quotas. Kafka and ZooKeeper are mapped to Kubernetes resources as StatefulSets with stable, unique names and network identifiers, and stable, persistent storage that moves with the Pod when it's scheduled to any other node. A headless Service controls the domain of the Pod, allowing DNS queries for the Pod name as part of the Service domain name.
Containers allow you to build an application once and then run it anywhere with a compatible container engine. They eliminate issues with dependencies in a runtime environment. Containers isolate processes without adding significant latency over running the application directly on a host. They increase application density, allowing you to make better use of the resources of a host, thereby improving the ROI for your infrastructure.
Challenges arise when one of the Kafka cluster components is outside of the Kubernetes cluster. For instance, if a producer is outside the cluster, it needs to know the addresses of some of the brokers to connect to them. However, the list it receives may contain the Pod IP (which won't work unless you have a CNI where the Pod IPs are directly accessible) or the Node IP where the Pod is running, coupled with the port where the Pod is listening (which won't work because the Node won't have an open port at the same location).
Kubernetes is necessary to orchestrate Kafka in a container. It connects the container runtime interface (CRI) with the container network interface (CNI) and the container storage interface (CSI), and provides the plumbing and glue to turn one or more containers into an application. It handles all aspects of getting user traffic to the software and back again, including installation, configuration, and connection to the outside world.
"But I want to run KafkaⓇ on Kubernetes. I want to run everything on Kubernetes."
It was hard not to roll my eyes when Karl said that to me. We were sitting outside of a Starbucks near my house, enjoying the morning air before the summer heat drove us back inside. He was drinking something green and healthy, and I was drinking a black iced americano. I took another sip while I counted slowly in my mind. One...two...three...and then the words fell out of my mouth, unbidden in their cold, honest truth.
"In nearly every situation, the benefit of running Kafka on Kubernetes isn't worth the trouble. I won't go so far as to say that it's wrong, but it's not far from it."
The place where Karl works is one of the companies that still hasn't made the leap to modern infrastructure. They have a large, legacy application, and Karl was hired recently as a DevOps Manager to help them with "digital transformation" and the "move to cloud native." Like many companies on that journey, he works with people who believe and also with people who are just going along with the industry trend. Karl believes. He's a Kubernetes fanboy to the core, and hearing me throw shade on Kubernetes makes him narrow his eyes.
"Running apps on Kubernetes is better than running them any other way."
But is it?
There are two types of applications that run inside of Kubernetes: cloud native apps that are purpose-built for a microservices environment like Kubernetes, and applications that were ported to that environment. For the second group, the performance of the application varies wildly. A web application with a static frontend and a PHP backend is an easy lift. For more complex applications that have expectations about the direct availability of their processes, the story is different.
"What benefit does a container provide?" I asked Karl.
He leaned back in his chair, confident that he was going to win the debate.
"Containers let you build an application once and then run it anywhere with a compatible container engine. They eliminate issues with dependencies in a runtime environment."
I nodded, and he looked up at the patio cover above us and thought for a moment. "They isolate processes without adding significant latency over running the application directly on a host," he continued. They increase application density, allowing you to make better use of the resources of a host. That gives you better ROI for your infrastructure."
"But you can't just run Kafka in a container," he said, thinking that's what I was going to suggest. "You need Kubernetes to orchestrate it."
Kubernetes connects the container runtime interface (CRI) with the container network interface (CNI) and the container storage interface (CSI), and then it provides the plumbing and glue to turn one or more containers into an application.
An application is more than software running in a container or on a host. It's everything involved in getting user traffic to that software and back again. Software by itself doesn't do anything. It has to be installed. It has to be configured. It has to be connected to the outside world. Developers shouldn't have to care about any of that. They should just be able to push code out to a repository, and something else should deploy it and make it available.
"Look," I said. "What we do with Kubernetes isn't magic. All we've done is virtualize the way that we used to do things in hardware. Kubernetes is like a mini datacenter, where each node is a rack, and each Pod is a server. It comes with all the switching, cabling, and routing pre-installed, so when you deploy your workloads, everything just works. Or at least it's supposed to."
I grabbed a clean napkin and started drawing on it.
Apache Kafka (currently) requires two components: the Kafka cluster itself, and a ZooKeeperⓇ cluster to handle elections, membership, service state, configuration data, ACLs, and quotas. If we were building these on real hardware, we might have a 3-node Kafka cluster and a 3-node ZooKeeper cluster. Each Kafka broker would have its own low-latency disks, lots of RAM for caching, and a reasonable amount of CPU cores. It would also know about each ZooKeeper node, and each producer and consumer would know about each Kafka broker.
This is a crucial part of how Kafka works -- producers and consumers have a list of bootstrap addresses to connect to. When they start, they connect to one of these addresses and are then given a specific broker to connect to for the partition they're working with. If that broker goes down, they'll reconnect to the bootstrap nodes and be assigned to a different broker. The communication between Kafka and ZooKeeper is similar -- each broker will connect to one of the ZooKeeper nodes in its list, and if that node fails, the broker will connect to a different node.
This awareness and automatic healing means that you never put a load balancer in front of Kafka or between Kafka and ZooKeeper.
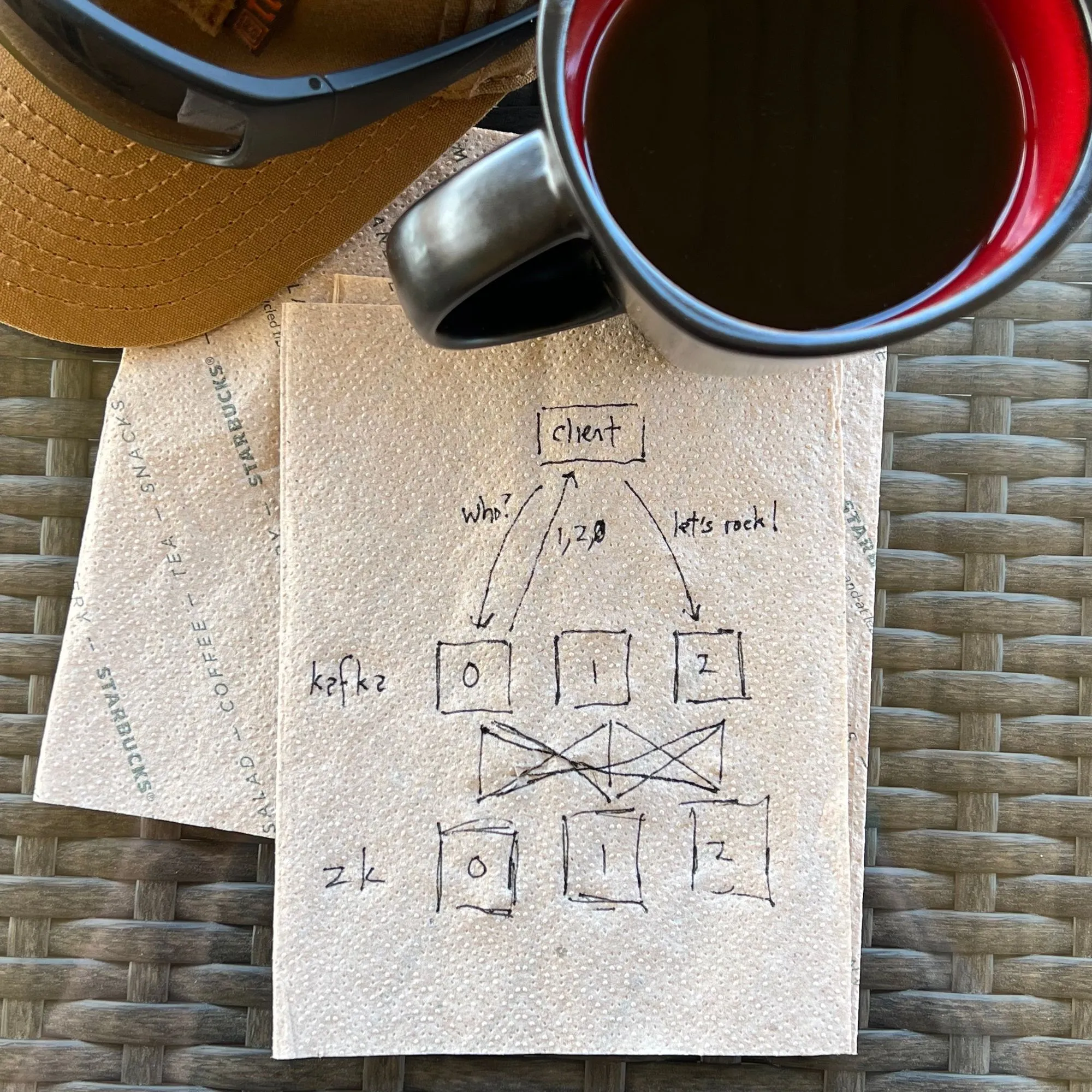
If we take what we've defined above and map it to Kubernetes resources, we end up with one StatefulSet for ZooKeeper and another for Kafka, each with three replicas. StatefulSets are a Kubernetes resource designed for stateful applications, and they guarantee:
A StatefulSet requires a headless Service to control the domain of the Pod. Where a normal Service presents an IP and load balances the Pods behind it, a headless Service returns the IPs of all its Pods in response to a DNS query. When a headless Service sits in front of a StatefulSet, Kubernetes takes this one step further and allows DNS queries for the Pod name as part of the Service domain name.
For example, imagine that we have a StatefulSet named kafka with three replicas, running in the namespace production. The Pods would be named kafka-0, kafka-1, and kafka-2. If we put a headless Service called kafka in front of them, then a DNS request for kafka.production.svc.cluster.local would return all three Pod IPs. We could also query DNS for kafka-0.kafka.production.svc.cluster.local to get the IP for kafka-0, and so on.
➤ kubectl get po
NAME READY STATUS RESTARTS AGE
kafka-0 1/1 Running 0 9m7s
kafka-1 1/1 Running 0 8m55s
kafka-2 1/1 Running 0 8m54s
➤ kubectl get service
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kafka ClusterIP None <none> 9092/TCP 11m
➤ kubectl run -i --tty --image busybox dns-test --restart=Never --rm
If you don't see a command prompt, try pressing enter.
/ # nslookup kafka-0.kafka
Server: 10.43.0.10
Address 1: 10.43.0.10 kube-dns.kube-system.svc.cluster.local
Name: kafka-0.kafka
Address 1: 10.42.0.14 kafka-0.kafka.production.svc.cluster.local
/ # nslookup kafka
Server: 10.43.0.10
Address 1: 10.43.0.10 kube-dns.kube-system.svc.cluster.local
Name: kafka
Address 1: 10.42.0.15 kafka-1.kafka.production.svc.cluster.local
Address 2: 10.42.0.16 kafka-2.kafka.production.svc.cluster.local
Address 3: 10.42.0.14 kafka-0.kafka.production.svc.cluster.localIf we did the same with ZooKeeper, we might end up with zk-0 through zk-2 as part of zookeeper.production.svc.cluster.local.
Our producers and consumers would use each of the Kafka replicas in their bootstrap configuration, and each of the Kafka brokers would use the ZooKeeper replicas as well.
If your Kafka cluster (with or without ZooKeeper), your producers, and your consumers all exist within the same Kubernetes cluster," I said, "then everything can talk to everything else.
"But what happens when one of those components is outside of the cluster?"
Let's say that you have a producer that's outside the cluster. It needs to know the addresses of some of the brokers so that it can connect to them and be told where to connect for the partition it's using.
You could use a NodePort or LoadBalancer Service for the bootstrap servers. As long as one broker was online (and hopefully you have at least one broker online...), then it will connect and get this information...except that that list will contain one of the following:
:9092 - this will be translated to 127.0.0.1:9092. Your producer will try to connect to itself and will fail.For all scenarios other than the conditions around the first one, your producer will not be able to connect to the broker.
It's tempting to solve this with Kubernetes Services, but Services are load balancers. Not only does a load balancer break how Kafka operates, where producers and consumers need to connect to a specific broker, but it would also require that the brokers themselves know the Service's external IP and instruct clients to connect to that IP. Some Kafka deployments handle this with initContainers or special configurations that admins manually maintain, but this breaks the dynamic nature of Kubernetes.
As soon as you're manually maintaining a configuration file with node IPs for where your Pods are deployed...you're off the reservation. It's only a matter of time before something terrible happens.
These issues notwithstanding, adding another layer of abstraction to the communication path (especially if that layer is an external LoadBalancer) adds latency, and latency is anathema to real-time data applications.
You can't create a Service for each Pod either. That's not how Kubernetes works. For nearly every other application in the world, there's no benefit to having multiple load balancers, each with a single backend Pod. Kubernetes wants you to build your applications so that everything that comes in from the outside can be load balanced across multiple Pods.
"What about using the host network?" Karl asked.
"Setting hostNetwork: true will expose the container's ports to the outside," I agreed, but as Karl started to smile, I shook my head. "It also exposes every published container port on the host, and it prevents us from using the headless Service that our StatefulSet needs."
Karl's smile disappeared, and he furrowed his brow. I went on.
"In fact, it prevents all communication with the Pods from within the Kubernetes cluster, effectively turning our Kubernetes deployment into a complicated physical deployment where Kubernetes does nothing more than ensure that the Pods are scheduled and running. You could expose the port from within the Pod with a hostPort declaration, but then you still have to deal with the Pod knowing the host where it landed and returning that information to an external client."
"Fine!" Karl threw his hands up in defeat and almost knocked over his drink. "It's fine. We're not going to be producing or consuming from outside of Kubernetes anyway, so we'll be fine."
I knew that Karl might not be.
Modern operating systems allocate unused RAM as cache for the filesystem, and Kafka relies on this for speed. On a node dedicated to Kafka that has 32GB of RAM, you might see 30GB of it used for caching. This is a Good Thing™...until it isn't.
There will be many containers running on a Kubernetes node, accessing the filesystem, and using the filesystem cache. This means that less of it will be available for Kafka, so Kafka will have to go to the disk more often. Kubernetes could also move one of the StatefulSet replicas to a different node, invalidating Kafka's filesystem cache in the process.
Kubernetes takes a heavy-handed approach to terminating containers, sending them a SIGTERM signal, waiting a specified period of time (30 seconds by default), and then sending a SIGKILL. It knows nothing about the process that Kafka goes through to move partitions, elect leaders, and shutdown gracefully. Letting Kubernetes handle this is like shutting down a broker by ripping out its power. Kafka will eventually recover, but it's not pretty.
{{featured-report="/components"}}
"The problem isn't entirely with Kubernetes, Karl. The problem is also with Kafka."
Karl looked at me and scoffed.
"No, seriously," I pressed. "What if you could replace Kafka with something else, without changing your existing code, and solve the problems that I just described?"
I had his attention.
"You're not going to fix the networking issues of exposing a broker outside of the cluster, but if your producers and consumers are located inside of the same Kubernetes cluster, we can make it into a robust solution with Redpanda."
Unlike Kafka, Redpanda communicates with RAM via direct memory access (DMA) and bypasses the filesystem cache for reads and writes. It aligns memory according to the layout of the filesystem, so very little data is flushed to the actual physical device. The resources allocated to Redpanda in the Kubernetes manifest are reserved for Redpanda and more efficient than relying on the filesystem cache. Along with its single-binary architecture that doesn't use Java or ZooKeeper, this also makes it better suited for running in a container. (Learn how to start using Redpanda in Kubernetes here.)
Redpanda's Kubernetes manifests also take brokers into and out of maintenance mode as part of the Kubernetes shutdown process, ensuring that other brokers take over as partition leaders and that the broker is drained of producers and consumers before the Pod terminates. Upon returning to service, the broker's DMA cache is primed as it catches up with the partition leaders before being eligible to become a leader itself.
This is a small part of what makes Redpanda the modern streaming data platform.
I love Kubernetes. It's a powerful tool that solves a myriad of problems, but it isn't a panacea. Not everything that can run on Kubernetes should run on Kubernetes, and if you’re evaluating whether to run Kafka or Redpanda on Kubernetes, consider how you’re going to interact with it from outside of the cluster. You may have to take steps to tell the brokers what their advertised IP is, and you may have to resort to manual configuration of the network stack to preserve the behavior that exists in a non-Kubernetes deployment.
Ironically, if you run Kafka or Redpanda outside of Kubernetes, you can still use it with producers and consumers that run inside of a Kubernetes cluster. It's only the other way around that's a challenge.
Head over to our Get Started page to learn more about Redpanda and start using it for free. For more free education on Streaming Fundamentals and Getting Started with Redpanda, visit the Redpanda University. To see what other members of the Redpanda Community are building, join us on Slack!
You can't scale what you can't trust. A governance layer fixes that.

Your lakehouse mirrors the database, instantly.

What is it, why enterprises need it, and how to evaluate one
Subscribe to our VIP (very important panda) mailing list to pounce on the latest blogs, surprise announcements, and community events!
Opt out anytime.