




5 predictions about agentic AI and analytics in 2026
What AI trends will shape analytics in the coming months?
Effects of fault injections on an availability of Redpanda and Apache Kafka.









We are building a streaming engine for modern applications. One that extends beyond the Apache Kafka® protocol, into inline Wasm transforms and geo-replicated hierarchical storage. However, to build our house, we need a solid foundation.
In my last post, I talked at length about how our consistency and validation testing puts Redpanda through the paces, including unavailability windows. Fundamentally, we left a big question unanswered: does Raft make a difference?
As a quick recap, our previous consistency testing helped us fix an unavailability blip when a follower who was on a network partition rejoined the cluster. This disruption is common among Raft-based protocols. We hypothesize this is due to the fact that only Diego’s dissertation (not the Raft paper) mentions the anomaly below and a countermeasure. This got us thinking about walking through and comparing our consensus protocol with upstream Apache Kafka with a fine tooth comb.
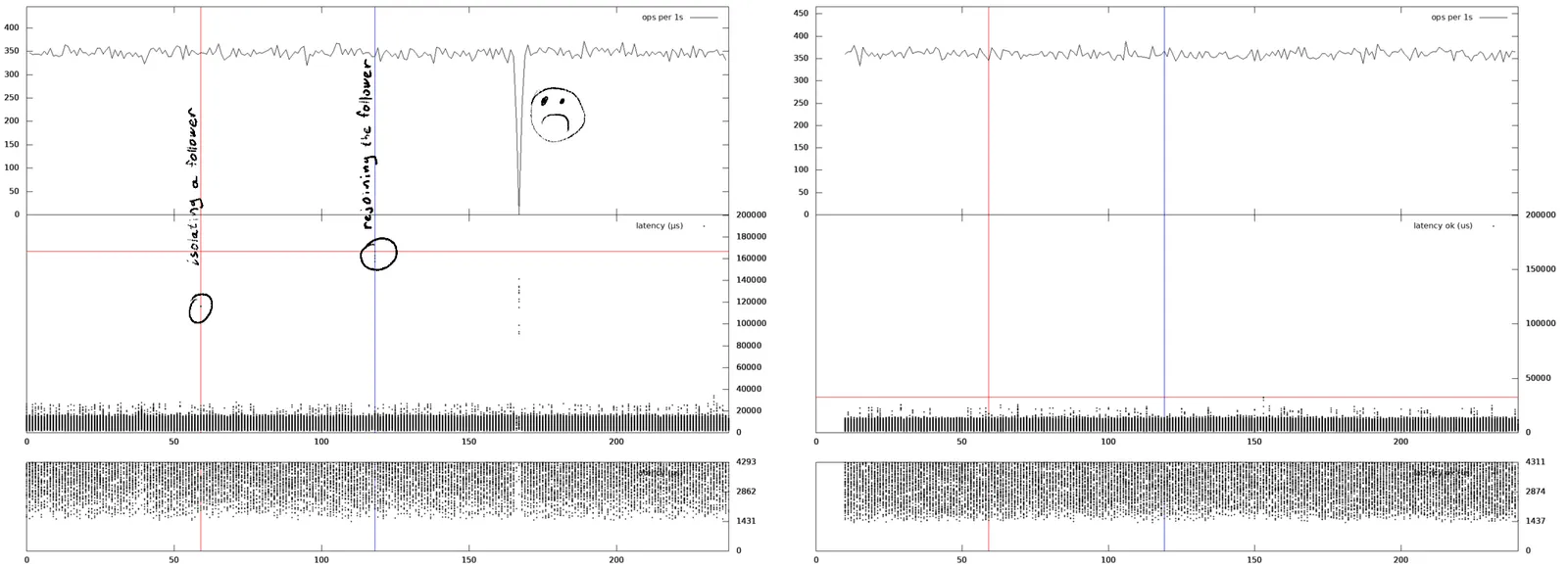
Redpanda uses the Raft replication protocol which tolerates F failures given 2F+1 nodes.
Apache Kafka uses synchronous replication and relies on Apache ZooKeeper for the cluster view management.
In the terms of the CAP theorem, it may be configured to work as an AP system (tolerates N-1 failures out of N brokers, possibility of a data loss) or as a CP system (via acks=all, setting min.insync.replicas of a quorum and flushing on every message via log.flush.interval.messages=1 on all brokers).
In the latter case, the level of resiliency is the same as Raft's (up to F failed nodes), so the question is if there is any difference between the protocols at all?
To answer that question we test a topic with a single partition and a replication factor of three. We configured Kafka 2.6.0 to work as a CP system and with Redpanda we used acks=-1 (strongest) settings.
Both protocols have a notion of a stable leader so any fault injection affecting a leader also affects the end-to-end experience.
When a process is terminated with kill -9 and restarted after a minute it affects Kafka (left) and Redpanda (right).

The first section of the chart is a number of successfully executed operations per second. It isn't a stress test so we maintain a pretty low steady load (100 ops/s). But each logical operation consists of a write and a read so in reality the load is twice higher. This section is useful to detect when a system experiences availability issues.
The next two sections are about latency. Each dot represents the duration of an operation ended at this moment.The first part is a complete overview and the second part is zoom-in on the fastest operations. The x axis is in seconds and the y axis is in microseconds. Black dots are successful operations, blue is timed out (outcome is unknown) and red dots are rejections (an operation isn't applied).
We simulate disk latency spikes by adding artificial 10ms latency via FUSE to every disk I/O operation on a leader for a minute. It sends Kafka's average latency to 980ms (p99 is 1256ms) and Redpanda's to 50ms (p99 is 94ms).
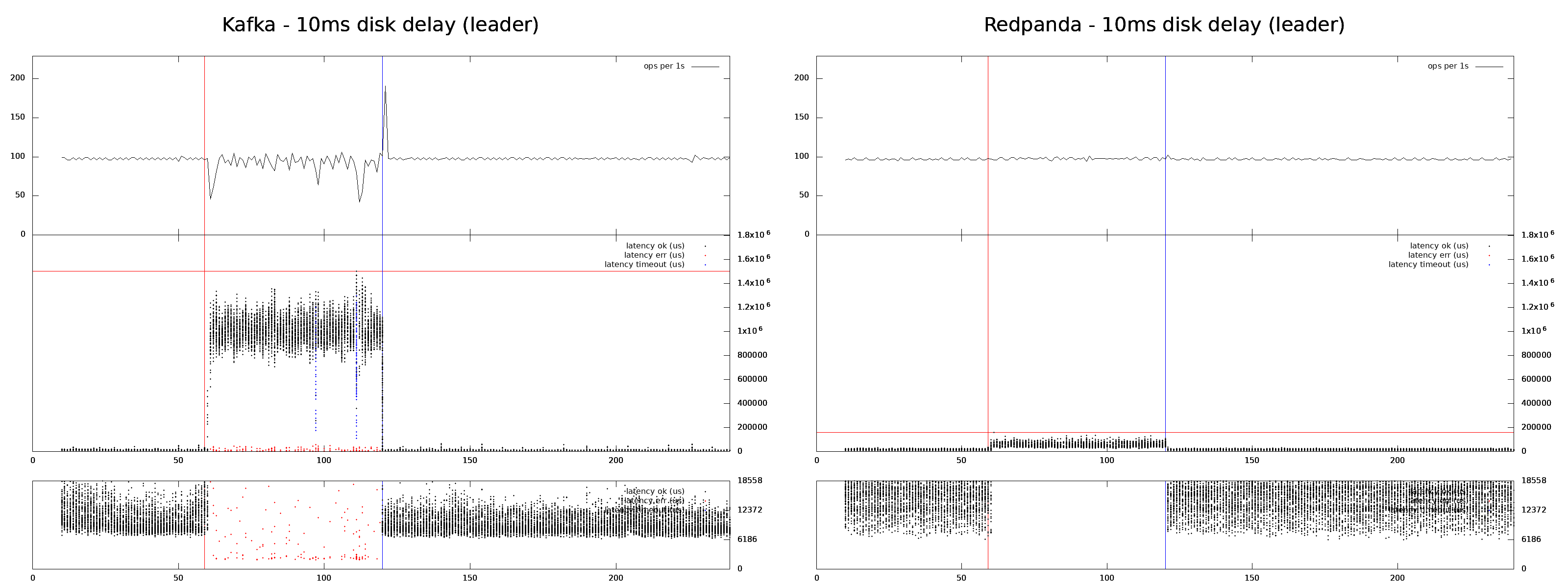
Kafka uses sync replication, so any disturbance of a follower affects user end-to-end experience until the disturbance is gone or until a faulty follower is excluded from the ISR (a list of active followers).
Redpanda uses quorum replication (Raft) so as long as a majority of the nodes including a leader is stable it can tolerate any disturbances.
As a result, Raft is less sensitive to the fault injections.
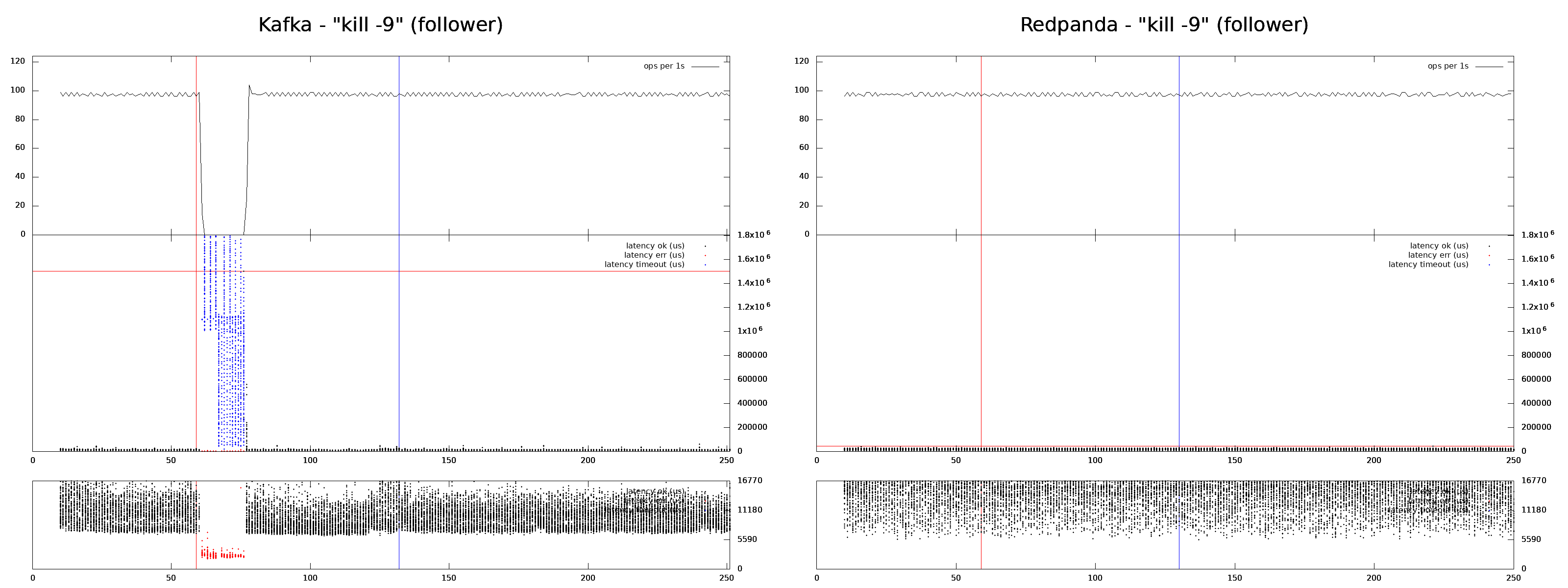
A process is terminated with kill -9 and restarted after a minute. Redpanda doesn't experience any disturbances.
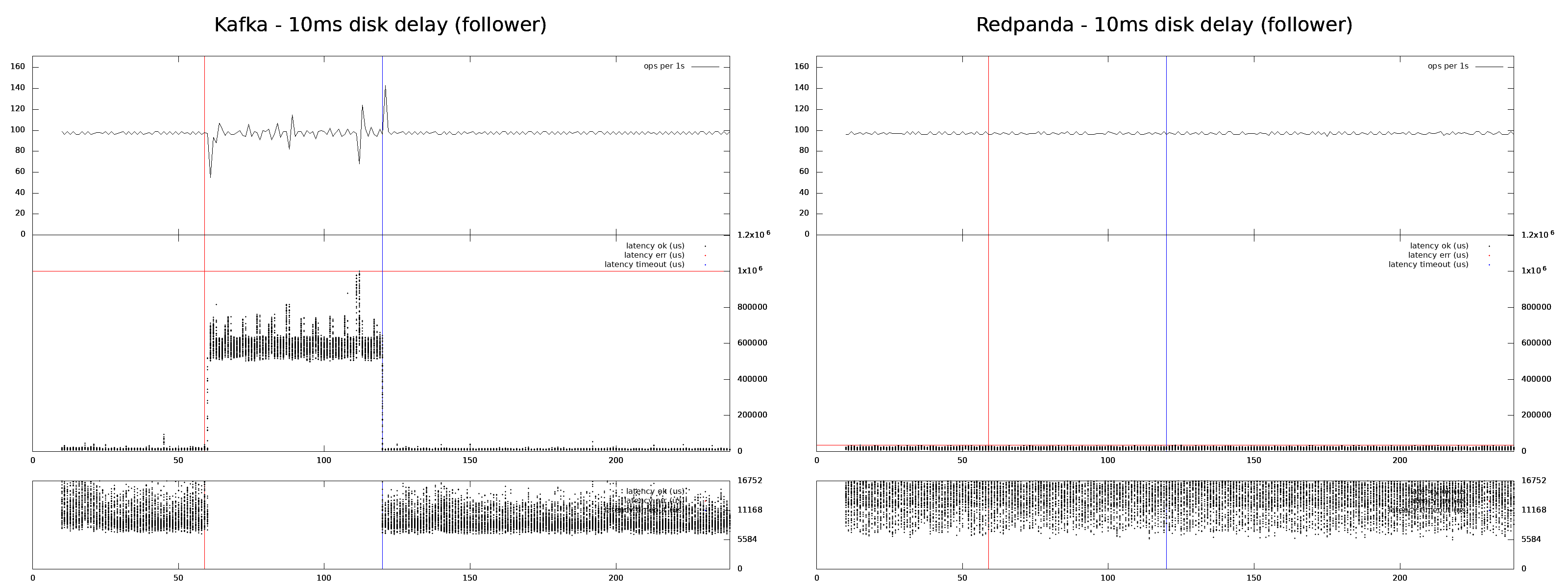
10ms latency is added to every disk I/O operation on a follower for a minute. Redpanda doesn't experience any disturbances.
Besides a termination and introducing a disk delay to a leader and a follower, we have tested the following fault injections.
And the results were the same. When a fault injection affects a leader both Redpanda and Kafka experience an availability loss, when a fault affects a follower only Kafka experiences disturbance.
The results fit the theory. Raft’s (and Redpanda’s) performance is proportional to the best of the majority of nodes, while sync replication (Kafka) works only as well as its worst-performing node.
A recipe for the performance / availability improvements is simple:
Our experiments demonstrated that an availability footprint of Redpanda (actual model) matches the theoretical limit of Raft (mental model), so the only thing left to do is take a step back from Raft.
Heidi Howard and Richard Mortier wrote an excellent paper on comparing Raft and Paxos replication protocols. Most relevantly:
"We must first answer the question of how exactly the two algorithms differ in their approach to consensus? Not only will this help in evaluating these algorithms, it may also allow Raft to benefit from the decades of research optimising Paxos’ performance and vice versa.
By describing a simplified Paxos algorithm using the same approach as Raft, we find that the two algorithms differ only in their approach to leader election."
The exciting conclusion here is that we can bring in decades of research and optimizations for Paxos-based systems to Redpanda and our Raft-based consensus and data replication protocol. The depth and breadth of these optimizations cover amortizing disk latency spikes that affect a minority of nodes including the leader, as well as figuring out a way to have natural hierarchy and WAN-based optimizations. We can’t wait to see how far we can push the system, break it and start again :)
What AI trends will shape analytics in the coming months?

Benchmark shows Vera provides 5.5x lower latencies and up to 73% higher throughputs than other leading CPU models

Learn from the leaders actually shipping and scaling AI agents today
Subscribe to our VIP (very important panda) mailing list to pounce on the latest blogs, surprise announcements, and community events!
Opt out anytime.