





Real-time Change Data Capture with Redpanda Connect and MySQL
Stream every insert, update, and delete from your database the moment it happens

Learn how to join multiple KStreams in Redpanda.








To set up Redpanda for a KStreams application, you can use the Redpanda Docker image. You can start Redpanda with a single command using a docker-compose.yml file to define the Redpanda configuration. After starting Redpanda, you need to create the topics needed in the KStreams application. Then, set up the producer to write to the input topic and a consumer to read from the output topic.
Apache Kafka Streams (KStreams) is a client library and Java dependency that performs stream processing, or real-time processing of incoming streams of data. It is used for smoother builds of applications and microservices. Common use cases for KStreams include aggregating the occurrence of certain words in a chat application, or filtering fraudulent transactions in a credit card processing system.
A KStream and a KTable are two sides of the same coin in a KStreams application. A KStream is a continuous stream of data in which every new event is recorded as a unique piece of data. A KTable, on the other hand, updates events with the same key. A KTable can be transformed to a KStream and a KStream to a KTable. A KTable is like the latest values of a KStream and a KStream is like the historical view of a KTable.
Redpanda is an Apache Kafka® API-compatible system that integrates with the Kafka ecosystem. It is easy to manage and can deliver significant performance improvements over other systems. In the context of KStreams, Redpanda acts as the message broker. You can use Redpanda instead of Kafka as the message broker without any code changes.
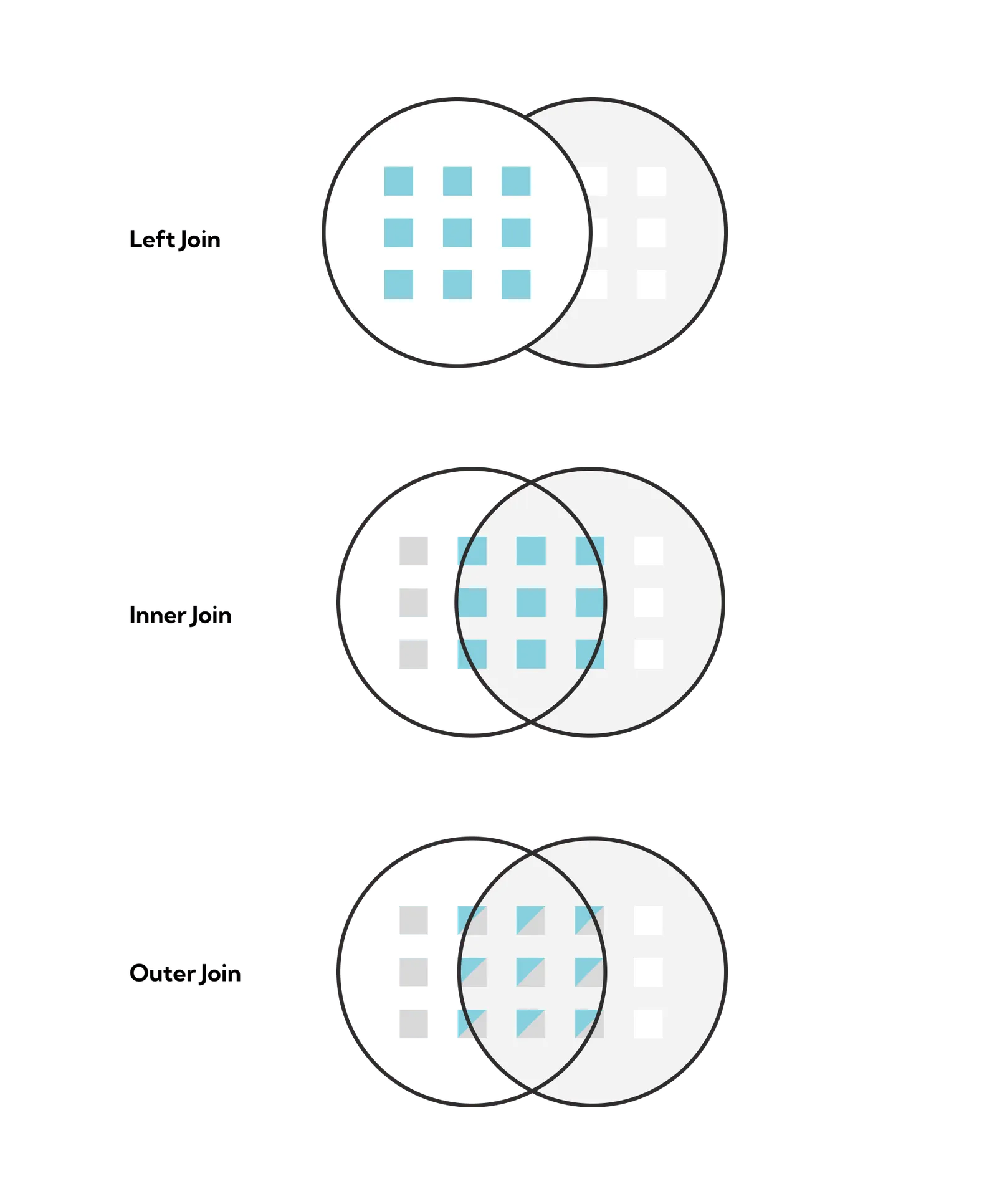
A KStreams application can perform various types of join operations. It can join one KStream to another KStream, one KStream to a KTable, one KTable to another KTable, and a KStream to a GlobalKTable. These join operations can be a left join, an inner join, or an outer join.
Apache Kafka Streams® (KStreams) is a client library and Java dependency that performs stream processing, or real-time processing of incoming streams of data, for smoother builds of applications and microservices. Common use cases for KStreams include aggregating the occurrence of certain words in a chat application, or filtering fraudulent transactions in a credit card processing system.
Message brokers—which act as a buffer for events produced by different services—are a vital component in the development of distributed applications. For the mission-critical systems serviced by KStreams, message brokers with minimal latencies are the best option. Redpanda is an Apache Kafka® API-compatible system that integrates with the Kafka ecosystem, is easy to manage, and can deliver significant performance improvements over other systems. Check this benchmark to learn more.
In this tutorial, you will learn how to aggregate multiple event streams using a KStreams application and Redpanda as the message broker. You'll set up a KStreams application but use Redpanda instead of Kafka as the message broker without any code changes.
In order to follow this tutorial, you need the following:
You can find the demo application in this GitHub repo. To follow the tutorial, you can clone the project with the below command:
git clone https://github.com/redpanda-data-blog/2022-aggregation-with-kstreams.git
cd kstreams-demoKStreams is a Java dependency added to a Java application like a Spring Boot backend. When it connects to a Kafka cluster, it takes input streams from a Kafka topic, transforms them, and sends the output as a stream to a different topic.
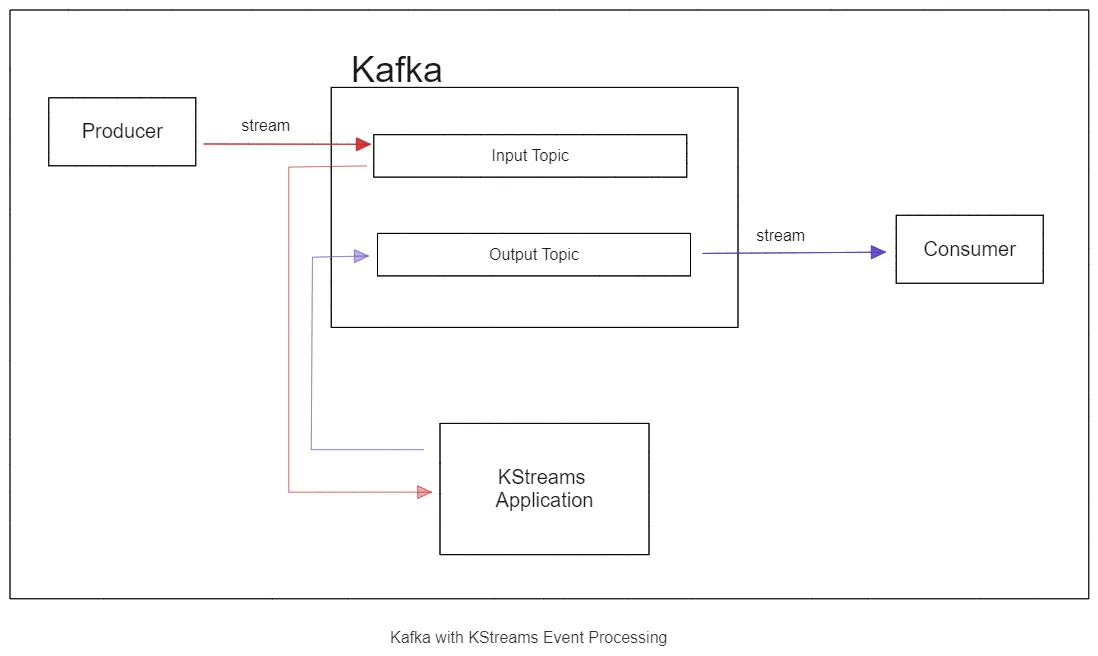
A KStreams application is an important component of a distributed system due to the nature of data processing within such systems. Consumers might want to use data in a certain way and would have to do the transformation themselves if stream processing were excluded from the systems. KStreams ensures that stream processing occurs only once. For a KStreams application to function properly, it requires a Kafka cluster with topics that will serve as input and output stream sources.
A typical stream processing application contains several methods such as Map, MapValues, Filter, and Join that transform or exclude data in one way or another. KStreams implements these methods in its domain-specific language (DSL). The DSL gives you all the tools required to perform stream processing so that it easily integrates with your Java application.
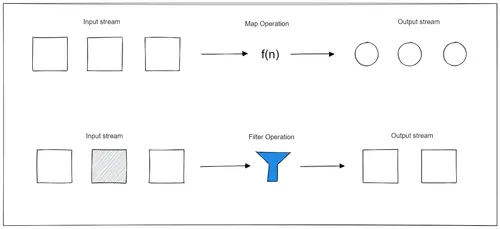
To understand how a KStreams application works, navigate to the cloned KStreams demo application and open the /src/main/java/com/application/WordCountDemo.java file. In this file, you will find a createWordCountStream method. This method contains the main logic of the application.
static void createWordCountStream(final StreamsBuilder builder) {
final KStream<String, String> source = builder.stream(INPUT_TOPIC);
final KTable<String, Long> counts = source
.flatMapValues(value -> Arrays.asList(value.toLowerCase(Locale.getDefault()).split("\\W+")))
.groupBy((key, value) -> value)
.count();
// need to override value serde to Long type
counts.toStream().to(OUTPUT_TOPIC, Produced.with(Serdes.String(), Serdes.Long()));
}The method uses a StreamsBuilder object passed to it to create a KStream called source. The values in this KStream are then grouped and counted using a combination of flatMapValues, groupBy, and count.
The source KStream object represents the stream of data from the streams-plaintext-input topic, while the counts KTable object represents the transformed data. These two objects are fundamental to every KStreams application.
A KStream and KTable are two sides of the same coin. A KStream is a continuous stream of data in which every new event is recorded as a unique piece of data. As an example, consider the following events sent through a KStream: ('eggs', 34), ('bread', 10), ('bread', 8). These events are composed as key-value pairs in which the string is the key and the number is the value. The second event will not be affected by the third in a KStream even if they have the same key.
A KTable, on the other hand, updates events with the same key. So if these three events, ('eggs', 34), ('bread', 10), and ('bread', 8), are sent to the KTable, it will resolve them into ('eggs', 34), ('bread', 8). Much like a relational database table, it basically takes note of the latest event. But then, a KTable can be transformed to a KStream and a KStream to a KTable. Think of a KTable as the latest values of a KStream and a KStream as the historical view of a KTable. This is the basis of aggregation and data joining in a KStreams application.
You will be using the Redpanda Docker image to run examples in this tutorial. To ensure that you can start Redpanda with a single command, you will use a docker-compose.yml file to define the Redpanda configuration. Create a docker-compose.yml file in a directory of your choice, then add the following content to it:
version: "3.7"
services:
redpanda:
command:
- redpanda
- start
- --smp
- "1"
- --memory
- 1G
- --reserve-memory
- 0M
- --overprovisioned
- --node-id
- "0"
- --kafka-addr
- PLAINTEXT://0.0.0.0:29092,OUTSIDE://0.0.0.0:9092
- --advertise-kafka-addr
- PLAINTEXT://redpanda:29092,OUTSIDE://localhost:9092
# NOTE: Please use the latest version here!
image: docker.vectorized.io/vectorized/redpanda:v21.11.11
container_name: redpanda-1
ports:
- 9092:9092
- 29092:29092You can run this file in detached mode by running docker compose up -d in the directory where the file lives. You should get an output like this:
[+] Running 1/1
- Container redpanda-1 StartedIn event streaming architectures, topics live in the message brokers. These topics store the messages or events sent by a producer. A stream is a continuous flow of data to or from the topic. Use the below command to create the topics needed in this KStreams application:
docker exec -it redpanda-1 \
rpk topic create streams-plaintext-input streams-wordcount-outputNow you need to set up the producer to write to the input topic and a consumer to read from the output topic. Redpanda offers an easy way to set up a producer without adding command line arguments. Run the below command to create the producer:
docker exec -it redpanda-1 \
rpk topic produce streams-plaintext-inputSetting up the consumer follows a similar approach. Open a new terminal and run the below command:
docker exec -it redpanda-1 \
rpk topic consume streams-wordcount-outputNow start the KStreams application in your IDE. In the terminal running the Redpanda streams-plaintext-input producer, type in the sentence all streams lead to kafka. Check for the output on the Redpanda streams-wordcount-output terminal. Your output should look like the following:
{
"topic": "streams-wordcount-output",
"key": "all",
"value": "\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0003",
"timestamp": 1646660088785,
"partition": 0,
"offset": 1
}
{
"topic": "streams-wordcount-output",
"key": "streams",
"value": "\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0003",
"timestamp": 1646660088785,
"partition": 0,
"offset": 2
}
{
"topic": "streams-wordcount-output",
"key": "lead",
"value": "\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0003",
"timestamp": 1646660088785,
"partition": 0,
"offset": 3
}
{
"topic": "streams-wordcount-output",
"key": "to",
"value": "\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0003",
"timestamp": 1646660088785,
"partition": 0,
"offset": 4
}
{
"topic": "streams-wordcount-output",
"key": "kafka",
"value": "\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0004",
"timestamp": 1646660088785,
"partition": 0,
"offset": 5
}A KStreams application is not limited to stream aggregation. It can also be used to join multiple streams together, as long as they have the same key. Typically a Kafka Streams application can join any of the following:
Similar to a typical database, these join operations can be any of the following:
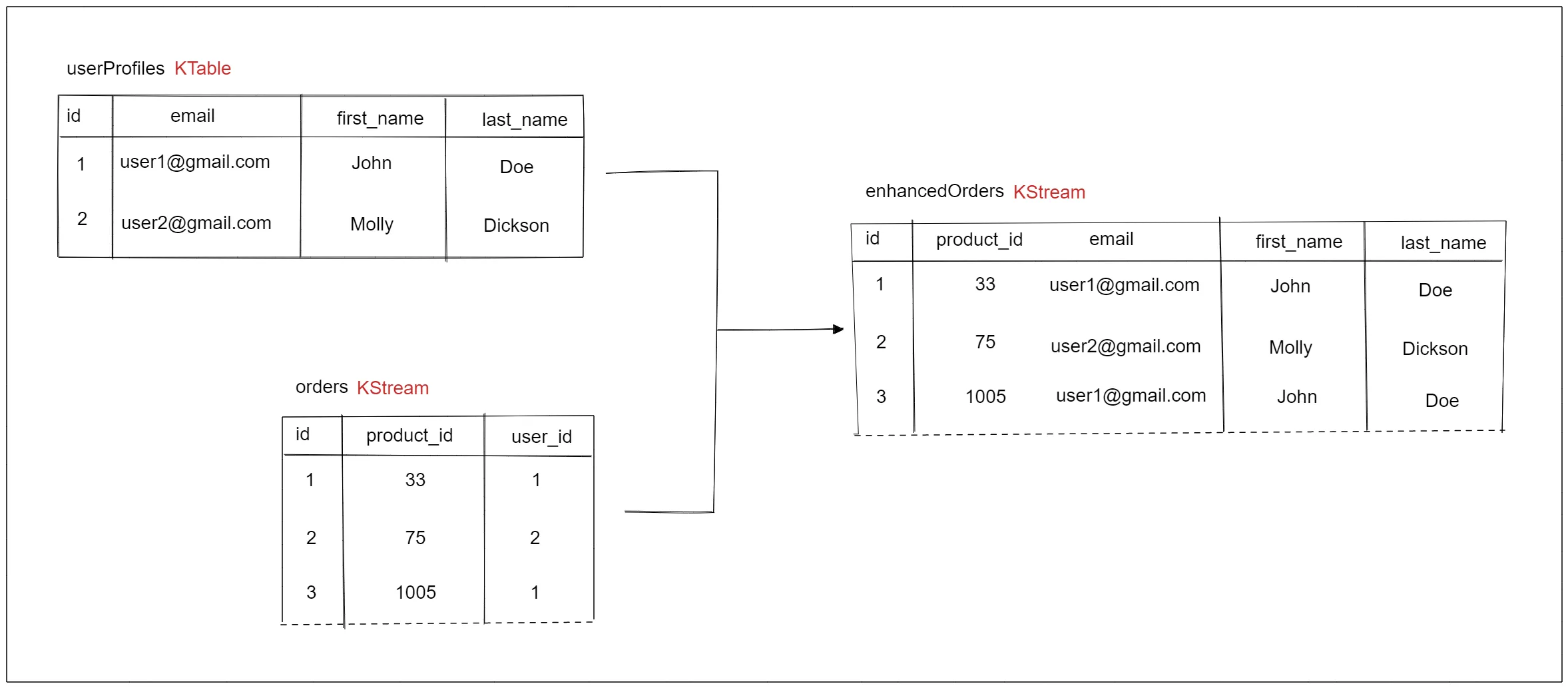
In this section, you will create an enhanced orders stream formed by joining user and order streams. It follows a similar architecture to the previous example, but in this case, you will use a leftJoin to join both streams.
To get started, create new topics for userProfiles, orders, and enhancedOrders using the below command:
docker exec -it redpanda-1 \
rpk topic create userProfiles orders enhancedOrdersThe code that handles the joining can be found in the src/main/java/com/application/EnhancedOrdersApplication.java from the cloned repo. Find the part where the userProfiles table and orders stream are initialized. A simple join is achieved using concatenation. The joined data is then streamed to the output topic.
final KTable<String, String> userProfiles = builder.table("userProfiles");
final KStream<String, String> orders = builder.stream("orders");
KStream<String, String> joined = orders.join(userProfiles,
(userProfile, order) -> userProfile + order
);
joined.to("enhancedOrders");Now, run the application in IntelliJ. Open three terminals and run the commands below for the producers and consumer sequentially. The messages will be streamed via stdin. The producer set the delimiter as a new line (\n) and the key-value separator as a colon (:). In this way the messages can have defined key-value pairs.
docker exec -it redpanda-1 \
rpk topic produce userProfiles -f "%k:%v\n"
docker exec -it redpanda-1 \
rpk topic produce orders -f "%k:%v\n"
docker exec -it redpanda-1 \
rpk topic consume enhancedOrdersIn the first terminal, produce the following data:
1:{"id":"1", "email":"john.wick@gmail.com", "first_name":"John", "last_name":"Wick"}
2:{"id":"2", "email":"malik.gruder@gmail.com", "first_name":"Malik", "last_name":"Gruder"}Produce data to the orders topic in the second terminal using the command below:
1:{"id":"1", "product_id":"33","user_id":"1"}
2:{"id":"2", "product_id":"75","user_id":"2"}
1:{"id":"3", "product_id":"1005","user_id":"1"}Now observe the third terminal for the output of the enhancedOrders stream. You should get data similar to what’s shown below:
{
"topic": "enhancedOrders",
"key": "1",
"value": "{\"id\":\"1\", \"product_id\":\"33\",\"user_id\":\"1\"}{\"id\":\"1\", \"email\":\"john.wick@gmail.com\", \"first_name\":\"John\", \"last_name\":\"Wick\"}",
"timestamp": 1649141650456,
"partition": 0,
"offset": 0
}
{
"topic": "enhancedOrders",
"key": "2",
"value": "{\"id\":\"2\", \"product_id\":\"75\",\"user_id\":\"2\"}{\"id\":\"2\", \"email\":\"malik.gruder@gmail.com\", \"first_name\":\"Malik\", \"last_name\":\"Gruder\"}",
"timestamp": 1649141650458,
"partition": 0,
"offset": 1
}
{
"topic": "enhancedOrders",
"key": "1",
"value": "{\"id\":\"3\", \"product_id\":\"1005\",\"user_id\":\"1\"}{\"id\":\"1\", \"email\":\"john.wick@gmail.com\", \"first_name\":\"John\", \"last_name\":\"Wick\"}",
"timestamp": 1649141650461,
"partition": 0,
"offset": 2
}You’ll notice that the second output has the second user’s details, while the first and third output has the first user’s details. This matches the expected result from the join diagram above.
Distributed applications that use message brokers often need a way to process streams of data for easier consumption and less computational overhead in consumer applications. KStreams serves as an excellent stream-processing tool for this purpose. While KStreams was built with Kafka in mind, it works with other systems, too.
As you saw in this tutorial, your KStreams application works well using Redpanda, which is a drop-in replacement for Kafka, without ZookeeperⓇ, and without a JVM. This enables you to increase your application’s message-processing ability with minimal effort.
To check your work, use the demo application in this GitHub repo. You can also discuss the demo, KStreams, or ask questions about anything else you can do with Redpanda in the Redpanda Slack community.
Subscribe to our VIP (very important panda) mailing list to pounce on the latest blogs, surprise announcements, and community events!
Opt out anytime.

