




Bridge Queries in Redpanda SQL
Have your real-time cake and eat your analytics too
Seamlessly integrate batch and real-time analytics while preserving data quality









Open file formats like Parquet and ORC ensure data is stored in highly compressed, efficient structures that support complex queries and analytics while remaining accessible to processing engines. Table formats like Apache Iceberg add powerful management capabilities that enhance the functionality of open file formats in Medallion-style data pipelines. They provide schema evolution, partitioning, and versioning capabilities, and ACID compliance for consistent and safe updates.
Redpanda's upcoming feature set, including the R1 engine, will be crucial in building data-intensive applications, unifying batch and real-time analytics in one place. Redpanda's topic-level integration with Iceberg enables creating Iceberg tables from your topics—storing row-oriented data in a Redpanda topic inside object storage in a columnar format, supporting the Iceberg table format. This unification enables a smooth segway into the Medallion architecture implementation without requiring additional connectors or complex configurations.
Redpanda's integration with Iceberg eliminates the need for any ETL processes to transfer data from Redpanda to a data lake or a data lakehouse. Producers simply write their row-oriented data into Redpanda topics, and Redpanda takes care of projecting records into a column-oriented file format, reliably writing them to the object storage, and making required updates to the Iceberg catalog. This ensures the provenance of the original data and technical metadata is preserved.
The Bronze layer is the foundational stage where raw, unprocessed data is ingested from various sources. The Silver layer is where data cleansing, transformation, and enrichment occur, refining the raw data into a more structured and usable form. The Gold layer is the final and most refined stage where data is fully prepared and optimized for analysis and reporting.
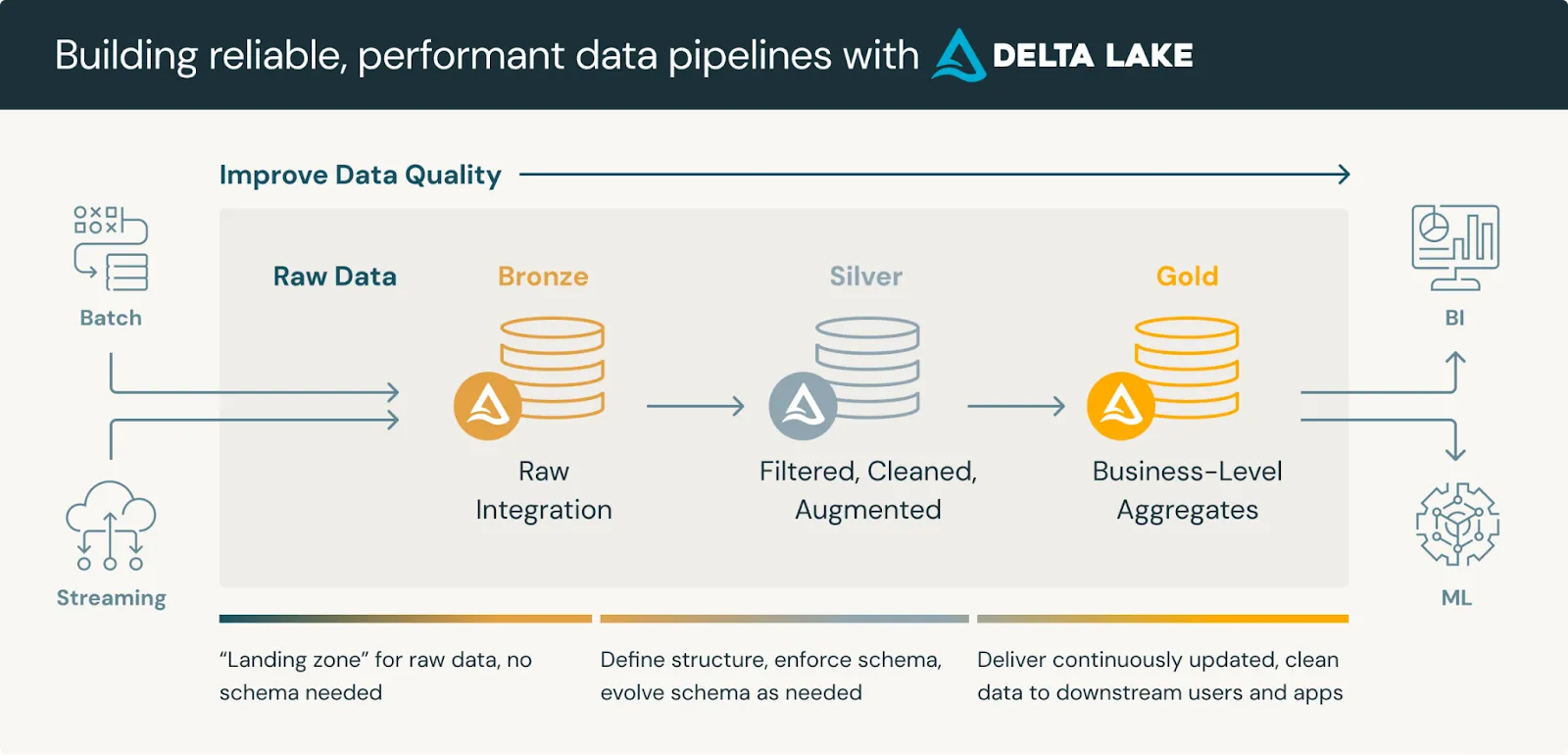
The Medallion Architecture is a systematic approach to structuring data storage into three distinct layers: Bronze, Silver, and Gold. Each layer represents progressively higher levels of data quality. As data progresses through these layers, it undergoes increasing refinement, resulting in higher business value at each stage.
Originally coined and popularized by Databricks, the Medallion Architecture stands out as a systematic approach to structuring data storage in three distinct layers—Bronze, Silver, and Gold—each representing progressively higher levels of data quality.
This architecture has gained significant traction in the data industry. For example, Microsoft has adopted it for their central data storage solution called One Lake, which is part of the Microsoft Fabric platform launched in 2023. The widespread adoption by major companies like Databricks and Microsoft underscores the importance and effectiveness of the Medallion architecture in modern data management practices.
This post explores how to use Redpanda and its ecosystem to implement the Medallion Architecture. We also detail how Redpanda’s Apache Iceberg™ integration contributes to streams being an integral part of this data architecture, facilitating a seamless integration of batch and real-time analytics while preserving data quality.
The Medallion Architecture is a logical approach to divide data storage into three layers: Bronze, Silver, and Gold. Each layer serves a specific purpose in the data lifecycle, from raw ingestion to refined, analytics-ready datasets. As data progresses through these layers, it undergoes increasing refinement, resulting in higher business value at each stage.
The foundational stage in the Medallion Architecture. It’s where raw, unprocessed data is ingested from various sources. This layer is a landing zone for all incoming data, whether from streaming services, IoT devices, or batch processing jobs.
At this stage, data is stored as-is, preserving its original form and structure, which is crucial for maintaining data lineage and allowing for a full history of all ingested records. Although data in the Bronze layer may contain errors, duplicates, and inconsistencies, it is essential as it provides a reliable audit trail and the flexibility to revisit unaltered data if needed.
This is where data cleansing, transformation, and enrichment occur, refining the raw data from the Bronze layer into a more structured and usable form. Here, data quality improves significantly through processes like deduplication, null value handling, and standardization of formats. Enrichment processes, such as adding metadata or joining data from other sources, can also occur in this layer, making the data more relevant and consistent for analytical tasks.
The Silver layer’s structured approach ensures that data is ready for intermediate analytics, and it serves as a bridge between raw data and high-value insights, giving data analysts and engineers cleaner, more reliable datasets.
The final and most refined stage in the Medallion Architecture where data is fully prepared and optimized for analysis and reporting. In this layer, data is aggregated and summarized to produce high-value, business-ready insights that can directly support decision-making, reporting, and machine learning applications.
The Gold layer's data is designed to be easily accessible and queryable by business users, often through dashboards or BI tools, to provide insights quickly and efficiently. By structuring data in a way that balances detail with usability, the Gold layer enables organizations to deliver accurate, actionable insights, ensuring that business teams can leverage data effectively without needing technical expertise.
Although the Medallion architecture is not closely linked to any specific data storage model, it’s quite popular in data lakes and data lakehouse implementations. These environments accommodate multiple teams ingesting, processing, and consuming petabyte-scale datasets for various analytical tasks.
What’s interesting to see is how open file formats and table formats provide a foundation for implementing and optimizing the Medallion architecture. Open file formats like Parquet and ORC ensure data is stored in highly compressed, efficient structures that support complex queries and analytics while remaining accessible to processing engines. This accessibility is vital for the Medallion Architecture, as it allows data to be ingested and stored in a standard format in the Bronze layer and then transformed and queried consistently as it moves through the Silver and Gold layers.
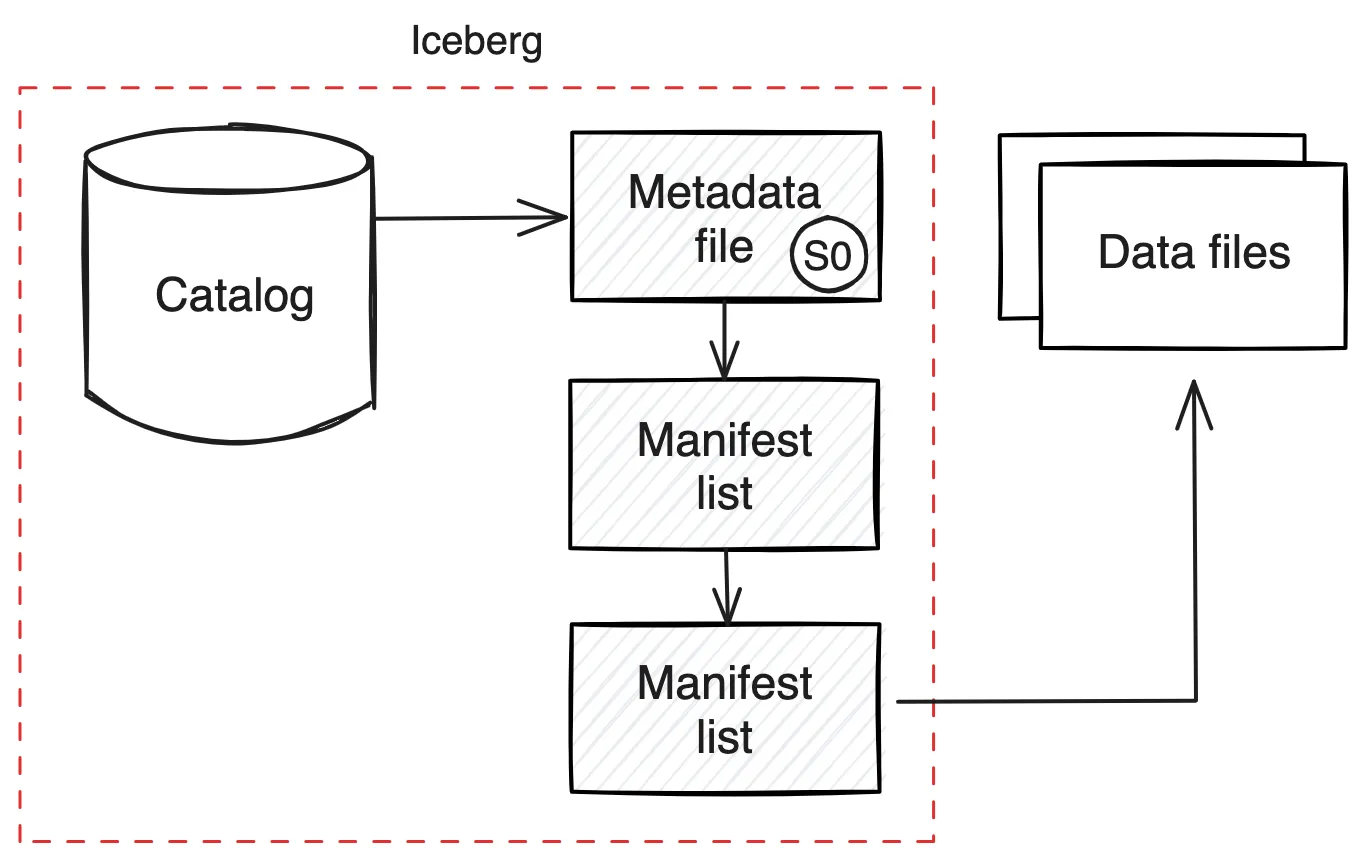
However, storing only data in open file formats wouldn’t be sufficient. We need a metadata layer on top of it to provide transactional guarantees, schema evolution, and many more. This is where table formats come into the scene.
Table formats like Apache Iceberg add powerful management capabilities that enhance the functionality of open file formats in Medallion-style data pipelines.
Iceberg provides schema evolution, partitioning, and versioning capabilities, allowing organizations to track changes to the data schema over time without disrupting downstream workflows. This is particularly beneficial in the Silver and Gold layers, where data often requires transformations and aggregations that can introduce schema changes. Iceberg’s ACID compliance also ensures that updates are consistent and safe, even in high-concurrency environments, which is critical for reliable analytics and reporting in the Gold layer.
Redpanda’s upcoming feature set, including the R1 engine, will be crucial in building data-intensive applications, unifying batch and real-time analytics in one place. This unification enables a smooth segway into the Medallion architecture implementation without requiring additional connectors or complex configurations.
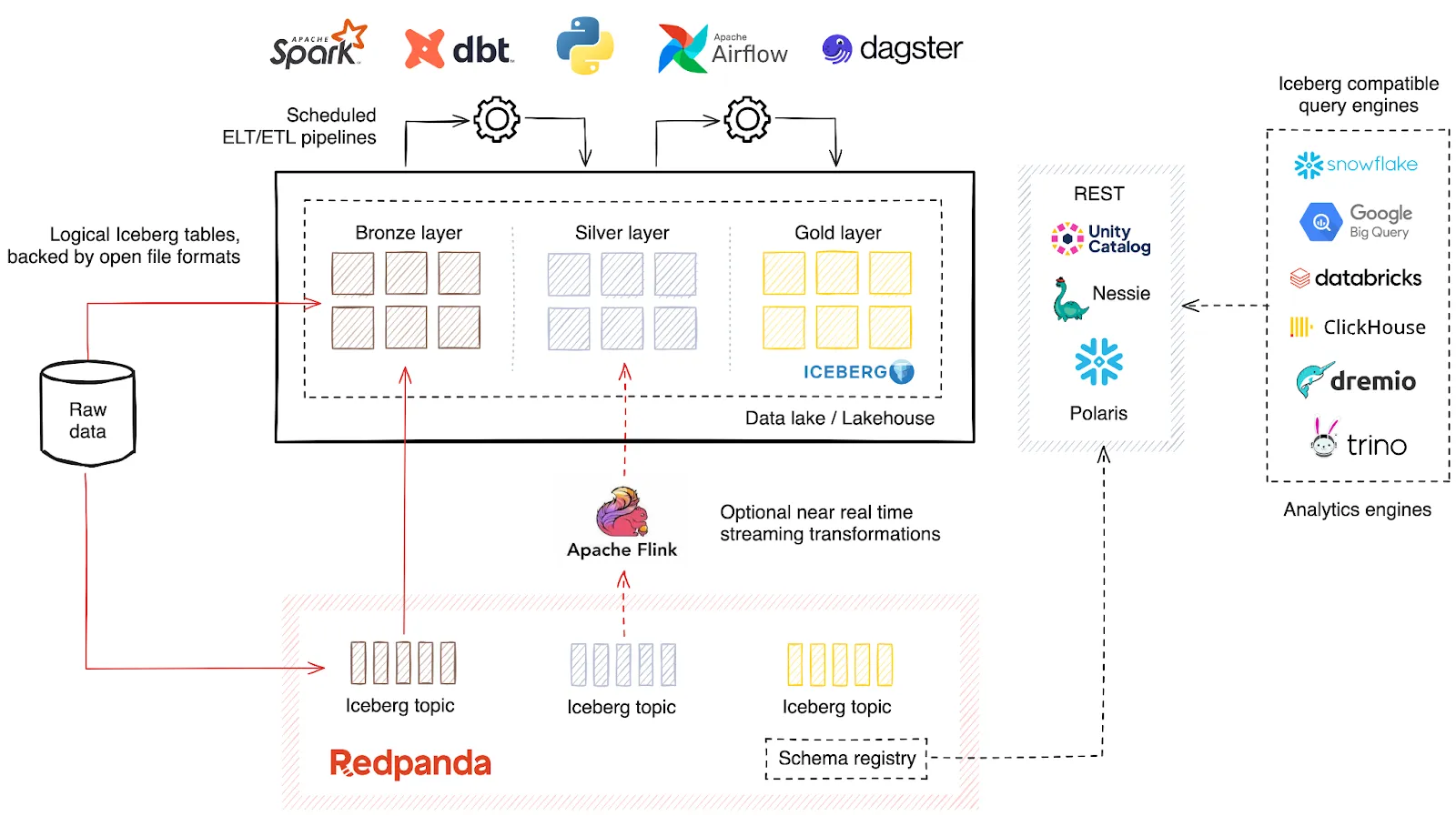
Let’s explore how different Redpanda features make it possible.
Redpanda’s newly launched feature, topic-level integration with Iceberg, enables creating Iceberg tables from your topics—storing row-oriented data in a Redpanda topic inside object storage in a columnar format, supporting the Iceberg table format. Tables can be created with or without a schema and registered with your Iceberg table catalog. Once registered, you can query them using popular Iceberg-compatible query engines like ClickHouse, Snowflake, Databricks, Dremio, and many more.
What’s compelling about the Iceberg integration is that you wouldn’t need any ETL processes to transfer data from Redpanda to a data lake or a data lakehouse. From a producer’s point of view, it’s all about writing their row-oriented data into Redpanda topics, and then Redpanda will take care of everything that happens after that—projecting row-oriented records into a column-oriented file format, reliably writing them to the object storage, and making required updates to the Iceberg catalog.
Currently, Redpanda supports working with external Iceberg REST catalogs like Databricks Unity and Snowflake Polaris. Plus, the Iceberg topics also incorporate technical metadata from the upstream Redpanda infrastructure, including offset, partition, and timestamp. This ensures the provenance of the original data and technical metadata is preserved.
Traditionally, this has been done with custom data engineering jobs executed in a workflow system like Apache Airflow. These jobs are often written in a general-purpose language, like Python. This required specialized talent to write, test, and maintain them, which is error-prone and time-consuming. Furthermore, they require reading the data from Redpanda before writing it to its destination, which comes with a performance cost.
Alternatively, you could use Redpanda Connect or Kafka Connect to move data between Redpanda and any system that supports Iceberg. However, these systems introduce a middleman to the architecture, requiring you to configure and maintain a separate set of clusters for data integration—extraction, transformation, and routing. Additionally, there’s no option for a configuration-based approach to make existing topics available in Iceberg without deploying new code.
The Iceberg integration makes the data ingestion into the Bronze layer seamless, fast, and cost-efficient. From a data producer perspective, it’s just a matter of writing raw data into a Redpanda Iceberg topic, and the data will be immediately visible in the respective Iceberg table.
Although it is not mandatory to enforce schemas on the data in the Bronze layer, Redpanda allows you the option to apply schemas to an Iceberg topic. This means that the data in the related Iceberg table will have a defined structure. If you haven’t configured a schema for the topic, Redpanda uses a simple schema consisting of the record’s key, value, and the original message timestamp, offset, and partition.
While the Iceberg integration is crucial in moving data into the Bronze layer, Redpanda’s capability in the Medallion architecture doesn’t end there. There’s a lot more to it.
Once the data lands in the Bronze layer, it undergoes several processing stages for incremental refinement. During these stages, operations like data cleansing, deduplication, enrichment, and transformation may be performed. These tasks are typically carried out by ELT (Extract, Load, Transform) pipelines.
For example, let’s assume the Bronze table (bronze_sensor_data) stores IoT sensor readings. We want to promote this table to the Silver layer (cleaned_data) by applying:
You can achieve this by writing a dbt (data build tool) transformation and scheduling it with an orchestrator like Apache Airflow. The resulting dbt query would look like this:
-- models/silver/silver_sensor_data.sql
WITH filtered_data AS (
SELECT
sensor_id,
timestamp,
temperature,
humidity,
status
FROM {{ ref('bronze_sensor_data') }}
WHERE status = 'active' -- Step 1: Only include active sensors
AND temperature BETWEEN -50 AND 50 -- Step 2: Filter temperature to realistic bounds
AND humidity IS NOT NULL -- Step 3: Remove readings with null humidity
),
cleaned_data AS (
SELECT
sensor_id,
timestamp,
temperature,
humidity,
-- Step 4: Create an indicator column for high temperatures, adding value for Silver layer analysis
CASE WHEN temperature > 35 THEN 'high' ELSE 'normal' END AS temperature_status
FROM filtered_data
)
SELECT *
FROM cleaned_dataThe Silver to Gold layer transformation would also follow the same, allowing you to further refine the data to have them cater to more domain-specific use cases. For example, the Gold layer table iot_dataset_ml can be used for training a weather prediction ML model while the iot_filtered_bi table can power BI dashboards and ad-hoc analysis with SQL.
While dbt has become a popular choice for data processing between layers, you can use any analytics tool that supports working with Iceberg tables, such as Apache Spark or Apache Flink (in batch mode).
While these ELT/ETL tools do a great job transforming Iceberg tables between layers, they typically run as scheduled batch jobs, adding a noticeable delay to the insights derived at the Gold layer. From a business perspective, the only drawback of this "multi-hop" architecture is the increased time to value, as it takes time for the data to traverse several layers.
What if we can do these transformations in real time when the data lands in the Bronze layer? We can do that by bringing in stream processing to this architecture.
Redpanda’s Kafka API compatibility allows you to bring any stream processor that can work with Apache Kafka. This includes Apache Flink, Apache Spark, and almost all the streaming databases out there.
Apache Iceberg provides a Flink connector that supports both reading from Iceberg tables, performing transformations, and writing the processed data back into new or existing Iceberg tables. This speeds up the data transformation between layers by shifting ELT pipelines to streaming ETL.
For example, you can write a Flink job to read a Bronze table, apply transformations, validations, and joins to write the results to a Silver table in the lakehouse via Flink’s Iceberg sink connector.
The Medallion Architecture offers a structured, layered approach to data processing that enhances data quality, accessibility, and reliability. Organizing data into Bronze, Silver, and Gold layers ensures a systematic transformation from raw to analytics-ready data. By enabling checks and cleanses at each stage, this architecture improves the data quality, allowing only refined data to reach downstream applications.
Open table formats like Apache Iceberg and file formats like Parquet and ORC democratize the data movement, storage, and processing within the Medallion architecture, allowing compatible data producers to write data and query engines to process and derive insights. Riding on those benefits, Redpanda’s Iceberg topics eliminate the need to move data between different operational and analytical data systems, standardizing the data at rest while allowing organizations to use their favorite data lakehouse technology.
The Medallion architecture also provides flexibility for managing real-time and batch data, making it ideal for companies looking to blend historical and streaming data for quick, insightful analysis. This also aligns well with Redpanda’s strategic vision of having a multi-modal engine for universal analytics needs.
To explore Redpanda and how it can streamline your architecture, check the documentation and browse the Redpanda blog for use cases and tutorials. If you have questions or want to chat with the team, join the Redpanda Community on Slack.
Subscribe to our VIP (very important panda) mailing list to pounce on the latest blogs, surprise announcements, and community events!
Opt out anytime.

