





Real-time Change Data Capture with Redpanda Connect and MySQL
Stream every insert, update, and delete from your database the moment it happens
Getting up-close and personal with producer configs and how to optimize them for various use cases.








Producers in a Redpanda deployment are responsible for sending messages to a topic in the cluster. They communicate with Redpanda through the Apache KafkaⓇ Producer API. When a producer publishes a message to a Redpanda cluster, the leader broker of the partition being written to receives it, appends it to that partition in the target topic, and sends the message to the follower brokers for replication.
The essential components of a Redpanda deployment include brokers, topics, producers, and consumers. These components form the core of a durable streaming system. Producers send data to brokers, which are stored in topics made up of partitions.
The 'enable.idempotence' parameter in a Redpanda producer configuration, when enabled, ensures that exactly one copy of every message is written to the broker. This is implemented using a special identifier that is assigned to every producer (the producer ID or “PID”). This ID, along with a "sequence number", is included in every message that is being sent to the broker. The broker will check if the PID/sequence number combination is larger than the previous one and, if not, it will discard the message.
The 'max.in.flight.requests.per.connection' parameter in a Redpanda producer configuration controls how many unacknowledged messages are allowed to be sent to the broker simultaneously at any given time. The default value is 5. If this parameter is set to 1, the producer will not send any more messages until the previous one is either acknowledged or an error happens. If set to a higher value, the producer will send more messages at the same time, increasing throughput but adding a risk of message reordering if retries are enabled.
The 'acks' parameter in a Redpanda producer configuration controls the behavior of the producer when a message is not acknowledged by the broker. It determines when a message is considered "acknowledged", which is when replication of the message to the majority of other brokers responsible for the partition in the cluster is complete. The possible values for this configuration can instruct the broker on when replication is considered complete, when to return to the producer, and when to consider a message acknowledged.
In a nutshell, the most essential components of a Redpanda deployment are: the brokers, topics, producers, and consumers. These make up the core of a durable streaming system.
In streaming applications, producers are responsible for sending data to the brokers, which are stored in topics made up of partitions.
In this article, we'll go into more detail about producers, explore their configuration options, and see how to optimize them for various use cases.
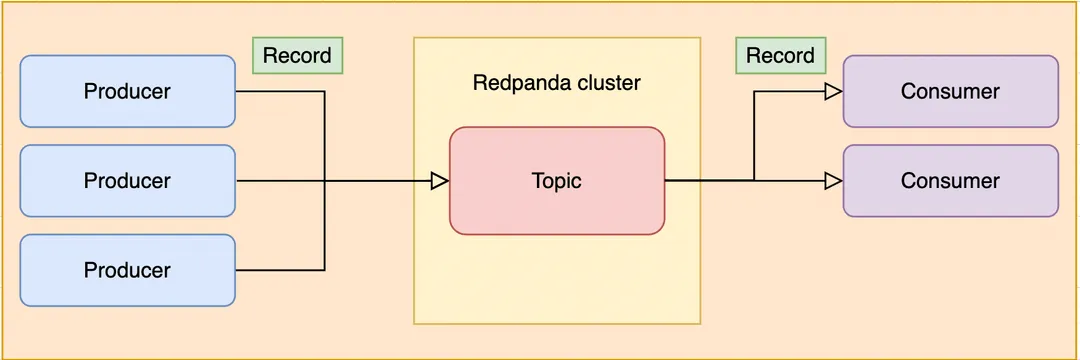
As mentioned above, the role of the producer is to send messages to a topic in the cluster. Producers communicate with Redpanda through the Apache KafkaⓇ Producer API, a well-defined interface collection.
In the picture above, we can see on the left side three producer applications. Think of these as programs written in your favorite programming language that do some work (like collecting clickstream data from user interactions) and then send the results to Redpanda.
When a producer publishes a message to a Redpanda cluster, the leader broker of the partition being written to receives it and appends it to that partition in the target topic and sends the message to the follower brokers for replication, making the message immediately durable and resilient to node loss. Producers can also publish messages to a particular partition they choose (more on this later).
Redpanda provides multitudes of configuration options for all components of a cluster. Finding the optimal combination of these components depends largely on the use case. We'll go into detail about the producer, see what configuration options it has, and see how to combine these options with some of the other components’ configurations to achieve specific results.
acksacks — short for “acknowledgments” — is the parameter that controls the behavior of the producer when a message is not acknowledged by the broker. This is a useful parameter to understand when you are working with a Redpanda cluster. At first glance, it may seem logical that the producer should wait for the broker to acknowledge the message in every circumstance, but there are many cases when we gain more by letting the messages fly to the broker, unconfirmed.
Sometimes trading speed for durability is the best strategy, but sometimes we want it the other way around. A message is considered "acknowledged" when replication of the message to the majority of other brokers responsible for the partition in the cluster is complete.
The possible values for this configuration are as follows:
acks = allSometimes referred to as acks = -1, this option instructs the broker that replication is considered complete when the message has been replicated (and fsynced, meaning flushed to disk, making it durable in case of broker crashes) to the majority of the brokers responsible for the partition in the cluster. As soon as the fsync call is complete, the message is considered acknowledged and is made visible to readers.
Note: This parameter has an important distinction compared to Kafka's behavior. In Kafka, a message is considered acknowledged without the requirement that it has been fsynced. Messages that have not been flushed to disk will be lost in the event of a broker crash. This means that Redpanda, with its default configuration, is more resilient than Kafka.
acks = 1Setting acks = 1 means only the leader broker has to store the request before returning to the producer. This means that replication is not guaranteed with this setting because it happens in the background, after the acknowledgement is sent to the producer from the leader broker. This setting could result in data loss if the leader broker crashes before any followers manage to replicate the message.
acks = 0This option allows Redpanda to immediately consider a message acknowledged when it is sent to the broker. This means that we don't have to wait for any kind of response from the broker. This is the least safe option as a single-node crash can cause data loss. However, this setting is useful in cases where we want to optimize for the highest throughput, and we don't mind if there's a loss of data.
Because of the lack of guarantees, this setting is the most network bandwidth efficient, as well. This makes it useful for use cases like IoT/sensor data collection where we can afford some degree of data loss, but we prefer gathering as much data as possible in a given time interval.
retriesThis parameter controls the number of times a message is re-sent to the broker if the broker fails to acknowledge it. This functionality is basically the same as if the client application resends the erroneous message after receiving an error response. The default value of retries in most client libraries is 0. This means that, if the sending fails, the message is not re-sent at all.
If you increase this number to a higher value, make sure to take a look at the max.in.flight.requests.per.connection parameter as well (see below for detailed explanation about it!), as leaving that parameter at its default value can potentially cause ordering issues in the target topic where the messages arrive. This is because, if two batches are sent to a single partition and the first fails and is retired but the second succeeds, the records in the second batch may appear first.
To be able to see the big picture on how all of these parameters work together to achieve features such as idempotency, keep reading!
max.in.flight.requests.per.connectionThis number controls how many unacknowledged messages are allowed to be sent to the broker simultaneously at any given time. The default value is 5. If we set this parameter to 1, then the producer will not send any more messages until the previous one is either acknowledged or an error happens, which can prompt a retry. If we set this parameter to a higher value, then the producer will send more messages at the same time, which can help to increase throughput, but add a risk of message reordering if retries are enabled.
In a case when we configure the producer to be idempotent, up to five requests can be guaranteed to be in flight with the order preserved.
enable.idempotenceIf idempotence is enabled, the producer will try to make sure that exactly one copy of every message is written to the broker. If this is set to false and the producer retries sending a message for any reason (such as transient errors like brokers not being available or not enough replicas exception), it can lead to duplicates.
In most client libraries this is set to true by default. Internally, this is implemented using a special identifier that is assigned to every producer (the producer ID or “PID”). This ID, along with a "sequence number", is included in every message that is being sent to the broker. The broker will check if the PID/sequence number combination is larger than the previous one and, if not, it will discard the message.
To guarantee true idempotent behavior, we also need to set the acks=all parameter to ensure all brokers will record messages in order, even in the event of node failures. In this configuration, both the producer and the broker prefer safety and durability over throughput.
To enable idempotence, the enable.idempotence parameter has to be set to true in your Redpanda configuration, which is the default value.
Idempotence is only guaranteed within a session. A session starts once the producer is instantiated and a connection is established between the client and Redpanda broker. When the connection is closed, the session ends.
Note: If your application code itself retries a request, the producer client will assign a new ID to that request, which may lead to duplicate messages.
When a producer prepares to send messages to a broker, it first fills up a buffer. When this buffer is full, the producer compresses (if instructed to do so) and sends out this batch of messages to the broker. The number of batches that can be sent in a single request to the broker is effectively limited by the max.request.size parameter. The number of requests that can simultaneously be in this "sending" state is controlled by the max.in.flight.requests.per.connection configuration setting, which defaults to 5 in most client libraries.
Batching is an efficient way to save on both network bandwidth and disk size as messages can be compressed easier. The batching configuration can be tuned by three factors:
buffer.memorybatch.sizelinger.msLet's go over these one by one!
buffer.memorybuffer.memory is the value that controls the total amount of memory available to the producer for buffering. In a case where messages are sent faster than they can be delivered to the broker, the producer application may run out of memory, which will cause it to either block subsequent send calls or even throw an exception. max.block.ms is the configuration parameter which controls the amount of time the producer will block before throwing an exception if it cannot immediately send messages to the broker.
batch.sizebatch.size is the value that controls the maximum size of coupled messages that can be batched together in one request. The producer will automatically put messages being sent to the same partition into one batch. This configuration parameter is given in bytes as opposed to the number of messages.
When the producer is gathering messages to assign to a batch, at one point it will hit this byte-size limit, which will trigger it to send the batch to the broker. However, the producer does not necessarily wait (for as much time as set via linger.ms) until the batch is full. Sometimes, it can even send single-message batches. This means that setting the batch size too large is not necessarily a bad thing, as it won't cause throttling when sending messages — it will only cause increased memory usage.
On the other hand, setting the batch size too small will cause the producer to send batches of messages faster, which can cause network overhead, meaning a reduced throughput. The default value is usually 16384, but you can set this as low as 0, which will turn off batching entirely.
linger.ms
Last but not least, the third important configuration parameter related to batching is linger.ms. This parameter controls the maximum amount of time the producer will wait before sending out a batch of messages, if it is not already full. This means you can somewhat force the producer to make sure that batches are being filled up as efficiently as possible.
If you can sacrifice a bit of latency, setting this value to a number larger than the default 0 will cause the producer to send fewer, more efficient batches of messages. If you set this value to 0, there is still a high chance of messages arriving around the same time to be batched together.
This algorithm is analogous to Nagle's algorithm, a solution to make sending TCP packets in batches as efficient as possible.
compression.typeThis parameter controls how the producer should compress a batch of messages before sending it to the broker. The default is none, which means the batch of messages will not be compressed at all. Compression happens on full batches, so you can improve your batching throughput by setting this parameter to use one of the available compression algorithms (along wth increasing batch size). The available options are: zstd, lz4, gzip, and snappy.
zstd is the generally recommended option, while it's highly discouraged to use gzip as it's very computationally expensive, which can slow down the whole system, but choosing the right compression algorithm depends on multiple factors, like the data itself and the serialization/deserialization protocol used.
Serializers are responsible for converting a message to a byte array. You can influence the speed/memory efficiency of your streaming setup by choosing one of the built-in serializers or even writing a custom one. The performance consequences of this option generally are not very significant, and choosing the serializer is mostly based on other factors, but it's worth mentioning here.
For example, if you opt for the JSON serializer, you will have more data to transport with each message as every record will contain its schema as well in a very verbose format, which will influence your compression speeds and network throughput. Alternatively, going with AVRO or Protobuf allows you to only define the schema in one place, while also enabling features like schema evolution.
In general, you can optimize for speed (throughput and latency) or safety (durability and availability) by tweaking parameters. Finding the optimal configuration will ultimately depend on your use case and will likely require a little trial and error. The following strategies are meant to be used as guidelines and not as hard rules.
There are two potential optimization targets when speed is the focus. Let's say all you care about is getting as much data as fast as possible into Redpanda. To maximize throughput, you can set other components’ parameters as well, like tweaking the topic partition size. For now though, let's focus on the producer side of things.
The first thing is to consider the acks parameter. Keep in mind that the quicker a producer receives a reply from the broker that the message has been committed, the sooner it can send the next message, which generally results in higher throughput. So, if you were to set acks=1, then the leader broker would not have to wait for replication to occur, and it can reply as soon as it is finished committing the message. As we detailed earlier when we talked about this parameter in depth, this will mean less durability overall.
The second thing to do when optimizing for throughput is to take a look at how the producer batches messages. Increasing the batch.size parameter and increasing the linger.ms can help with throughput by making the producer add more messages into one batch before sending it to the broker and waiting until the batches can properly fill up. This will incur a small hit to latency, though, so keep that in mind. By contrast, if you were to minimize linger.ms (potentially to 0) and batch.size to 1, you would be able to achieve lower latency but would have to sacrifice some throughput.
The other optimization target is to configure everything with durability or availability in mind. For applications where it is required to guarantee that there are no lost messages, duplicates, or even service downtime, these are critical configurations to tweak.
As with the previous optimization strategy, the first thing to do is to take a look at the acks parameter. If you set it to acks=all, then the producer will wait for all replicas to acknowledge the message before it can send the next message. This will result in lower latency, as there's more communication required between brokers, but guarantees higher durability because the message will be replicated to all brokers.
Increasing durability is also possible by increasing the amount of retries the broker is allowed to do in case messages were not delivered successfully. This has the trade-off of allowing duplicates to enter the system and potentially alter the ordering of messages.
As you can see, the available configuration options for the Redpanda producer are quite extensive. This flexibility can be a very powerful tool if you invest a little time to research into how the parameters interoperate. Don't be discouraged by the sheer amount of possible configuration permutations — this is a good thing, as it allows you to tune your Redpanda system to meet the exact needs of your application. These configuration parameters work best when combined with other configuration parameters available for brokers and consumers, so make sure to take a look at the documentation for those here and here, respectively.
The most important thing is to start by collecting requirements from your application and deciding what you want to optimize for. After you know this, you can start playing around with the configuration parameters and seeing which exact combination works best for you. If you're not sure where to start, you can always start with the default values — which have safety in mind — and then tweak them one by one until you find your optimal configuration.
Take Redpanda for a test drive here. Check out our documentation to understand the nuts and bolts of how the platform works, or read our blogs to see the plethora of ways to integrate with Redpanda. To ask our Solution Architects and Core Engineers questions and interact with other Redpanda users, join the Redpanda Community on Slack.
Subscribe to our VIP (very important panda) mailing list to pounce on the latest blogs, surprise announcements, and community events!
Opt out anytime.

