




Full CDC semantics land in the Iceberg output for Redpanda Connect
Your lakehouse mirrors the database, instantly.
How we built a simple yet efficient crypto data hub with Redpanda, Rust, and Samsa









Redpanda Transforms and Samsa provide efficiency in large-scale, distributed applications. The ingestion code using Samsa is powerful and repeatable for many different financial exchanges, while Redpanda Transforms cuts out network hops and greatly simplifies the application. All the types and conversion code is in one place, reducing complexity.
Redpanda Transforms is designed to reduce network overhead in event-driven systems. It allows logic to be performed directly on the brokers, cutting out the network exchange that can be wasteful, especially with operations like schema mapping or transforming messages.
The Rust Redpanda Transforms SDK is used to inject custom logic into the data transformation process. It requires you to call on_record_written on a transform function. In the transform function, the value is broken out of the message and tried to cast it to each type. When a type-casting succeeds, it continues on to create the new record and write it to the output topic.
Redpanda serves as a unified streaming data platform in event-driven systems. It is where the messages pass through. However, in a Redpanda cluster, messages could hop between consumers multiple times, potentially causing unnecessary delays.
The crypto data hub was built using Rust and a homegrown client called Samsa. Rust was chosen for its strong type system, which allows for easy casting between types, and the Redpanda Transforms SDK, which enables hooking into the transform features. Samsa was used to produce messages to the cluster in a lightweight and asynchronous manner.
As the industry focuses on challenges surrounding streaming data and real-time data sources, simplicity should be at the top of mind. Event-driven systems have their benefits, but with large-scale distributed applications, the network becomes a bottleneck.
Redpanda is central to event-driven systems as a unified streaming data platform where the messages pass through. However, messages in a Redpanda cluster could hop between consumers more than a few times, causing an unnecessary delay. With certain operations, such as schema mapping or transforming messages, the network exchange is downright wasteful.
This is where Redpanda Transforms waltzes in to cut out the network overhead and perform our logic directly on the brokers.
In this post, we demonstrate how we used Redpanda Transforms to build an efficient crypto data hub that receives prices from different exchanges and stores them in a consistent format.
For this solution, we choose our tools carefully. We’ll program in Rust for two reasons:
To communicate with Redpanda in Rust, we use a homegrown client called Samsa. This allows us to produce messages to the cluster in a lightweight and asynchronous manner.
The nature of the solution decides the other tools we use. We need a Redpanda cluster running—Docker will suffice for those who need to spin one up quickly. To compile and deploy our transform, we will use the rpk tool.
Our GitHub repository stores all the code and will help get everything set up.
Here’s a diagram to illustrate what this solution looks like.
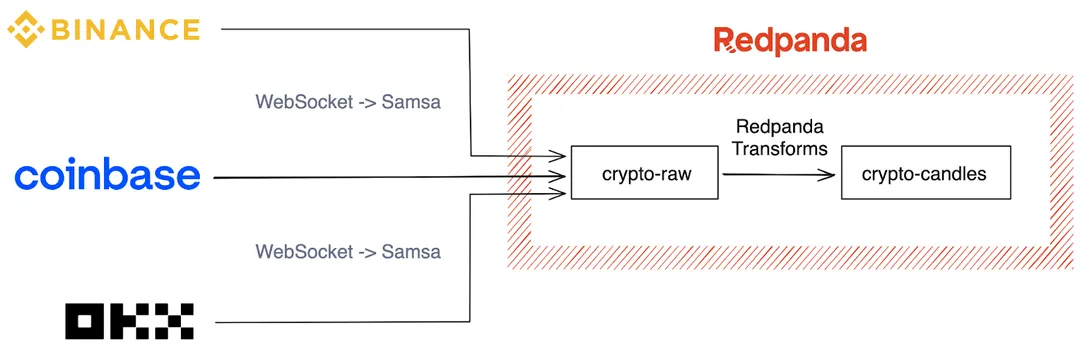
The good part. We’ll divide this into two parts: the data sources and the transformations.
On the data sources, we picked Binance, Okx, and Coinbase as our three Crypto exchanges. They each provide a WebSocket API that reports live price updates for assets. As they’re free and don’t require any sort of authentication, we recommend taking the prices with a grain of salt and putting off the “high-frequency trading dream” for another day.
Here’s the connection for Okx; each of the connectors follows this same pattern.
use futures::{stream::StreamExt, SinkExt};
use samsa::prelude::*;
use tokio_tungstenite::connect_async;
#[tokio::main]
async fn main() {
//
// 1. Set up variables
//
let bootstrap_addrs = vec![BrokerAddress {
host: String::from("localhost"),
port: 9092,
}];
let topic = "crypto-raw";
let url = "wss://ws.okx.com:8443/ws/v5/business";
let instrument_id = "BTC-USD-SWAP";
let subscription_payload = format!(
r#"{{
"op": "subscribe",
"args": [
{{
"channel": "mark-price-candle1m",
"instId": "{}"
}}
]
}}"#,
instrument_id
);
//
// 2. Connect to OKX & build source stream
//
let (mut socket, _) = connect_async(url::Url::parse(&url).unwrap()).await.unwrap();
socket.send(subscription_payload.into()).await.unwrap();
let stream = socket.enumerate().filter_map(|(i, message)| async {
if let Ok(message) = message {
let binary_data = message.into_data();
Some(ProduceMessage {
key: None,
topic: topic.to_owned(),
value: Some(bytes::Bytes::from(binary_data)),
headers: vec![],
partition_id: 0,
})
} else {
None
}
}).chunks(3);
//
// 3. Set up samsa producer
//
let output_stream =
ProducerBuilder::<TcpConnection>::new(bootstrap_addrs.clone(), vec![topic.to_string()])
.await
.unwrap()
.build_from_stream(stream)
.await;
tokio::pin!(output_stream);
while (output_stream.next().await).is_some() {
tracing::info!("Batch sent");
}
}
First, we set up our variables. The cluster URLs and our destination topic are required. We also define our Okx URL and the payload to start our subscription. Next, we create the WebSocket subscription using Tungstenite to give us a stream from the socket. Lastly, we build our Samsa Producer using the Tungstenite stream.
On the Redpanda Transforms side, we define our target data structure to be a typical Candle.
#[derive(Debug, Serialize)]
pub struct CryptoCandle {
pub open: f64,
pub high: f64,
pub low: f64,
pub close: f64,
pub volume: f64,
pub timestamp: f64,
pub source: String,
pub symbol: String
}The next step is to define types for the individual crypto messages as well as how to cast them into our target type above.
//
// Define our Price type that our network message is parsed into
//
#[derive(Deserialize)]
pub struct OkxMessage {
data: Vec<Vec<String>>,
}
//
// Define our conversion trait to the common type
//
impl TryFrom<OkxMessage> for CryptoCandle {
type Error = &'static str;
fn try_from(m: OkxMessage) -> Result<Self, Self::Error> {
if m.data.len() == 0 || m.data[0].len() == 0 {
return Err("missing data");
}
let timestamp = now() as f64;
let open = m.data[0][1].parse().unwrap_or_default();
let high = m.data[0][2].parse().unwrap_or_default();
let low = m.data[0][3].parse().unwrap_or_default();
let close = m.data[0][4].parse().unwrap_or_default();
let volume = 0_f64;
Ok(CryptoCandle {
timestamp,
open,
high,
low,
close,
volume,
symbol: "BTC-USD-SWAP".to_owned(),
source: "Okx".to_owned(),
})
}
}
//
// Define enum variant for each potential message type
//
#[derive(Deserialize)]
#[serde(untagged)]
pub enum CryptoMessage {
Binance(binance::BinanceMessage),
Coinbase(coinbase::CoinbaseMessage),
Okx(okx::OkxMessage),
}This is where Rust comes in handy. We can use serde to simply parse the message into something usable. This is done with #[derive(Deserialize)] on our OkxMessage type. The TryFrom trait in the standard library also allows you to define a mapping from one type to another that could potentially fail. And lastly we create a single enum to abstract all potential message types.
Using Rust Redpanda Transforms SDK is simple, just follow the example and inject your own logic.
use redpanda_transform_sdk::*;
use std::error::Error;
use crypto_transform_hub::{CryptoCandle, CryptoMessage};
fn main() {
// Register your transform function.
// This is a good place to perform other setup too.
on_record_written(my_transform);
}
// my_transform is where you read the record that was written, and then you can
// return new records that will be written to the output topic
fn my_transform(event: WriteEvent, writer: &mut RecordWriter) -> Result<(), Box<dyn Error>> {
let value = event.record.value().unwrap();
//
// Try to parse each type of message
//
let out: Result<CryptoCandle, &str> = match serde_json::from_slice(&value) {
Ok(CryptoMessage::Binance(b)) => b.try_into(),
Ok(CryptoMessage::Coinbase(c)) => c.try_into(),
Ok(CryptoMessage::Okx(o)) => o.try_into(),
Err(_) => {
return Ok(())
}
};
//
// Handle errors as you wish
//
let out = match out {
Ok(o) => o,
Err(_) => {
// TODO: send to dead-letter queue, through a new topic
return Ok(())
}
};
//
// Define and write a new record
//
let record = Record::new(
Some(out.symbol.clone().into_bytes()),
Some(serde_json::to_string(&out)?.into_bytes()),
);
writer.write(&record)?;
Ok(())
}The SDK requires you to simply call on_record_written on a transform function. In our transform function, we break the value out of the message and try to cast it to each type. When a type-casting succeeds, it will continue on to create the new record and write it to the output topic. If at any point an error arises, the code will just quietly pause and wait for the next message.
Efficiency at every step is important in large-scale, distributed applications. The ingestion code using Samsa is powerful and repeatable for many different financial exchanges, while Redpanda Transforms cuts out network hops and greatly simplifies our application.
Furthermore, all the types and conversion code is in one place, which cuts down on complexity. The Rust code to deserialize and cast our messages into one type is clean and concise. Remember, you can find all the code we used in the CallistoLabsNYC repo on GitHub. If you have questions or want to learn more about Redpanda, join the Redpanda Community on Slack.
Subscribe to our VIP (very important panda) mailing list to pounce on the latest blogs, surprise announcements, and community events!
Opt out anytime.

