




Bridge Queries in Redpanda SQL
Have your real-time cake and eat your analytics too
Capabilities that further simplify day-2 operations in production environments – including Remote Read Replicas, Continuous Data Balancing, and a brand new Redpanda Console.









One of the foundational goals for Redpanda has always been to eliminate complexity that has become categorical with streaming data infrastructure. Redpanda was built to be a simpler experience in all its facets — simpler to install, simpler for developers to use, and simpler for SRE and sysadmins to manage. Redpanda 22.2 extends those principles to day-2 operations with a host of new industry-first capabilities that help engineering teams deliver robust, reliable and secure data pipelines for real-time applications. We’re also thrilled to share with you the new Redpanda Console, simply the best, most developer-friendly user interface (in our community’s opinion) for managing and debugging large scale applications built around real-time data streams.
Highlights include (click on each to jump to details):
Since this is our biggest release, it’s also our longest release blog post. :) Read on for more details!
Building upon our tiered storage capability, our new Remote Read Replicas allow SREs and sysadmins to cherry pick topics from their operational clusters and serve them from their analytics clusters without duplicating data – and without deploying any additional software. Think of these Read Replicas as helping you deploy a “CDN” for your streaming data, one that distributes data close to the workloads and frees your engineers from having to settle upon the right data architecture from the get go – new topics can be propagated on-demand in minutes! (Learn more about how we built Remote Read Replicas in this blog post!)
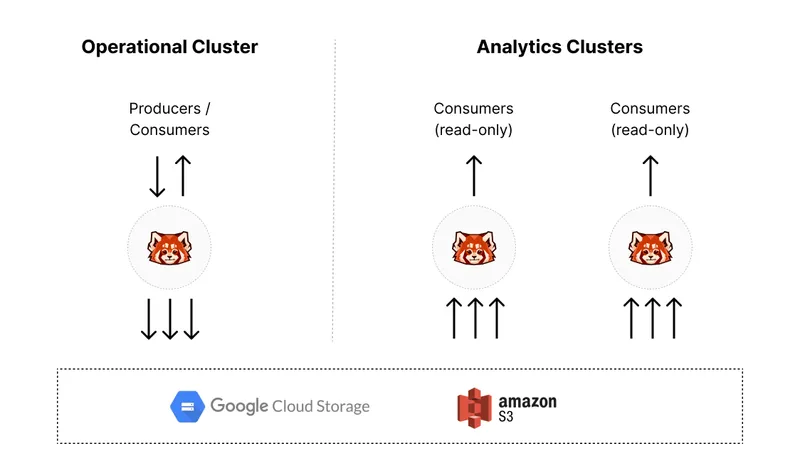
SREs and sysadmins are routinely responsible for building and managing infrastructure to shield operational clusters from analytics workloads. Typically this involves replicating your primary data to multiple clusters, in regions local to your analytics workloads – clusters that your analytics and machine learning teams can use without risking disruption to your primary workloads. Done routinely, this is a large time and cost sink for your devops organization. It involves duplicating data, keeping it in sync, and sizing the analytics clusters similarly to the operational cluster.
Available as part of Redpanda Enterprise, Remote Read Replicas take only minutes to create, making quick work of delivering data to your analytics clusters. (Learn more in our Remote Read Replica documentation.) Simply tell Redpanda which topics should be propagated, and you’re good to go – there’s no additional software to deploy or manage! Remote Read Replicas rely on Redpanda’s tiered storage capabilities using cloud object storage – systems with much lower cost than local volumes and eleven 9’s of durability! There is no limit to the number of topics you can propagate, and because they are created per topic, you can be extremely fine-grained about which data is available to different teams in your organization.
Since the data actually resides in your cloud storage, Remote Read Replicas can be served on ephemeral hardware with minimal local storage, enabling a more cost-effective hardware footprint. They also afford more freedom and flexibility to your analytics teams in how they build their workloads, knowing that they’re not going to impact the operational cluster in any way.
The continuous cluster balancing features in Redpanda liberate your SREs and sysadmins from having to manually administer storage in your clusters. Continuous cluster balancing relies on multiple anti-entropy mechanisms to keep your cluster in its optimal condition.
However, one of the most complex tasks in streaming data management is protecting clusters against data seasonality – where 10% of your nodes handle 90% of the traffic. It is inevitable that one of your customers will generate 80% of your traffic and fill up your disks, dominate the network, and saturate resources, resulting in performance degradation. This is the "noisy" data neighbor we all fear.
Let’s start by looking at what’s already in Redpanda. Automatic leadership rebalancing is available for free in Redpanda Community Edition. It actively works with the raft quorum to ensure an even distribution of leaders are placed across all partition-replicas. This means that over time your cluster will see balanced network consumption, and for most it means more predictable application latency. Default partition balancing on node add, also available for free in Redpanda Community Edition, triggers partition rebalancing when new nodes are added to the system, so that your new node is fully utilized, without administrative intervention.
Redpanda 22.2 adds new mechanisms to protect your cluster from data imbalance-related performance hotspots without manual cluster administration. This new capability is called Continuous Data Balancing and is available in Redpanda Enterprise. (Learn more in the documentation here.)
The first mechanism, data balancing on disk usage, ensures that partitions are redistributed across the cluster when disk usage reaches a specified percentage of disk capacity. This capability proactively prevents cluster interruptions that would result from full disks (as long as there are additional nodes with available disk capacity in your cluster).
The second, data balancing on node failures, automatically recovers partitions from unavailable nodes. When a node is disrupted for any reason (say, due to underlying hardware failure), Redpanda moves partitions hosted by that node to others in the cluster, ensuring that the cluster maintains optimal performance.
Together with automatic leadership balancing, these capabilities remediate unexpected issues, and reduce administrative effort, while providing a safety margin that keeps your cluster healthy, leaving your operations team free to make the strategic adjustments necessary to handle the long-term growth of your data.
Building upon our acquisition of CloudHut Kowl, the new Redpanda Console gives developers and operators the easiest, most complete web UI for visibility into their data streams with powerful features for debugging and cluster administration. SREs and sysadmins are routinely impeded by lack of visibility into their message flows, consumers and sprawling configuration, leaving them at the mercy of a patchwork of command line tools and log files to build their own troubleshooting and administration workflows. (Learn more in the Redpanda Console documentation.)
With Redpanda Console, you have a single facility to:
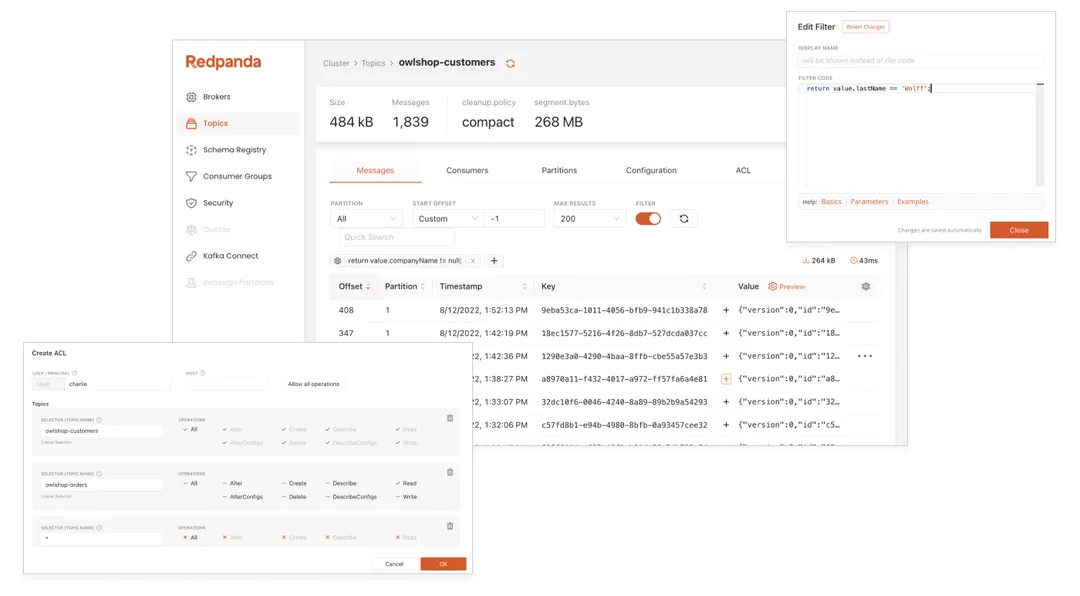
Redpanda Console features many industry-first capabilities, such as Programmable Push Filters, which allow you to quickly narrow down the range of messages you are looking for. Push filters are custom pieces of logic written in JavaScript or TypeScript that allow developers or admins to express the types of messages that are of interest and surface them in the console. Push Filters execute on-demand, searching for matching data and can process millions of records to find a match. For instance, you could be looking for all messages containing a specific product SKU flowing through an “order” topic to debug faulty orders your application sent to Redpanda. The console also allows you to delete messages or publish new messages, so you can develop, test, debug, and fix data issues within your system.
Push filters are designed to handle a large volume of messages, quickly and efficiently. Because they operate on the server-side, push filters limit the volume of data being transferred to the console UI, reducing network bandwidth and keeping your experience snappy.
Also unique to the Redpanda Console is a comprehensive capability to manage Kafka ACLs, an ability limited heretofore to configuration files and command lines. Redpanda Console’s visual interface enables admins to more easily understand security policies, and helps admins avoid configuration mistakes that could result in security breaches.
Redpanda 22.2 enables you to deploy the console in production environments by giving you SSO and role-based access control (RBAC) capabilities that secure the console from unauthorized access. You can now use your enterprise identity provider (IdP) to authenticate users and roles for providing different levels of access. Supported identity providers include Okta, Google, Github and any provider supporting OIDC (OpenID). You also gain the ability to leverage predefined roles that can limit access to various capabilities in the console. Because identity, credentials and group membership all come from your enterprise IdP, not only is there no need to login, there’s also no need to clean up or change role assignments when a user leaves the organization or when teams are reorganized. The new SSO and RBAC capabilities are part of Redpanda Enterprise.
22.2 remains true to our obsession with simplicity. This new release introduces a host of new features to simplify your SRE and sysadmin’s experience with Kafka workloads. And we include the bulk of these features in our free, Redpanda Community Edition! The complete release notes are available here, but have a look at some of the highlights below.
This new release provides additional protection from disruptions associated with full disks. Redpanda 22.2 blocks writes to the local node from Kafka producers when the disk space on a node is almost full, allowing admins to take action without crashing the node. This feature mitigates disruptions stemming from unexpected increases in data written by the application. Additionally, the system also adds new disk usage ‘alert’ metrics to help devops proactively monitor the Redpanda cluster when disks are full to a configurable threshold. Together with Continuous Data Balancing, these alerts help admins to avoid hitting the redline and respond to add capacity before the highest threshold is hit and write pipelines may be stalled. Previously, a full disk would result in a node being completely removed from service. (View the full-disk handling documentation here.)
You can now leverage IAM roles native to AWS and GCP with Redpanda’s Tiered Storage and Remote Read Replica features, instead of using access keys and secret keys. This allows for a simpler, more secure, and more manageable access mechanism to your cloud resources, without the need for manually rotating the keys periodically. This also makes it easier to use IAM policies that authorize Redpanda to use different pools of cloud storage (with read-write or read-only privileges) without accessing each environment directly, and reduces the surface area of risks for data theft. This capability is limited to Redpanda Enterprise. (Read the IAM documentation here.)
Redpanda now offers mTLS principal mapping to support those of you using mTLS authentication with unique certificates for each user. The identity is extracted from the certificate’s Distinguished Name (‘DN’) using a configurable mapping rule, and Kafka ACLs are applied to this identity, thus identifying the user based on their certificate and not a username, and authenticating the user based on the certificate’s private key and not a password. Cluster admins can also configure mixed-mode authentication with multiple listeners (e.g., some listeners can use SASL, some can use mTLS, to help support a variety of Kafka clients and their security conventions). You also benefit from improved cluster security posture with certificate-based identity for Kafka API users and per-listener auth configuration. (Learn more in the mTLS documentation here.)
Kafka consumer groups attempt to balance consumer load by dynamically monitoring consumer health and evenly assigning partitions to consumers. However, rebalancing load can lead to performance degradation in state-heavy apps. To eliminate rebalancing, Kafka 2.3 introduced static group membership, which allows the consumer group to persist member identities by consumers configuring a group.instance.id. That way, if the consumer drops out or restarts (within a specified timeout period), the consumer group coordinator can assign the consumer the same partitions without triggering a full rebalancing. Redpanda 22.2 fully supports static group membership with Kafka clients, bringing Redpanda in compliance withKafka KIP 345.
22.2 introduces a new Prometheus endpoint designed to help devops teams better monitor Redpanda clusters. Built for consumption at scale, the new (primary) endpoint features a reduced cardinality of metrics that are easier to consume, and simpler to integrate with your Grafana dashboards. The complete list of metrics can be found in our documentation.
Redpanda 22.2 is our biggest release to date, enabling you to run large-scale workloads on a globally distributed data substrate with extreme reliability and minimal administrative effort. You can grab the Community Edition here. If you’re interested in a free trial of Redpanda Enterprise, we can set you up with limited-use license keys. Request your free trial today by contacting our sales team here!
Subscribe to our VIP (very important panda) mailing list to pounce on the latest blogs, surprise announcements, and community events!
Opt out anytime.

