





Deploy agents you can trust with centralized AI governance
You can't scale what you can't trust. A governance layer fixes that.

A detailed analysis of Redpanda’s official Jepsen report, including a discussion on write-write conflicts in the Apache Kafka® protocol.








The partnership with Jepsen helped Redpanda look at the Kafka transactional protocol with a fresh set of eyes and recognize the fundamental differences between Kafka and database transactional models. It also helped identify and address consistency and availability issues.
Jepsen is a company that provides auditing services in the domain of distributed systems. It helps software development teams ensure their software functions as intended. Jepsen partnerships typically last several months and include analyzing documentation, writing custom test harnesses, and running multiple tests with specialized fault injections.
Redpanda is a new streaming storage engine designed to keep your data safe despite physical realities like hardware failures. It uses formally verified protocols like Raft and two-phase commit to remain consistent and available during failures such as network partitions, slow disks, and faulty filesystems.
Having a consistent system like Redpanda allows application developers to rely on the system's guarantees instead of writing code to counter anomalies. This is because the safety property of a consistent system requires that the system doesn't violate its specification.
Redpanda's Jepsen testing confirmed that it is a safe system without known consistency problems. While the idempotency and transactional layers had issues, these have already been fixed. The only consistency findings not addressed are unusual properties of the Apache Kafka protocol itself, not of a particular implementation.
Redpanda partnered with Jepsen to ensure that it doesn't have consistency issues. The partnership involved several months of working together to analyze documentation, write custom test harnesses, and run multiple tests with specialized fault injections.
See Jepsen Findings OnDemand!
Watch the recorded webcast of Kyle Kingsbury (@jepsen_io) to see how Redpanda fared in his recent Jepsen Test.
The sad reality of physics is that you don’t have a say. Computers will crash, hard drives will fail, and your cat will unplug your network cable — facts.
Redpanda is a new streaming storage engine, designed from the ground up to keep your data safe despite the reality of physics. We use formally verified protocols like Raft and two-phase commit to remain consistent and available during failures such as network partitions, slow disks, faulty filesystems, etc.
But the fact that our chosen protocols work in theory doesn't guarantee that an implementation won’t contain optimization-induced bugs. We need independent and empirical evidence of correctness.
In this post, we’ll discuss in detail how Redpanda fared in our Jepsen Report. We’re sharing this because we believe the more transparent we are with our community, the better Redpanda will serve the developers and engineers who want an insanely fast event streaming platform that’s also simple to use. That said, let’s jump into what Jepsen testing is and what it found.
Jepsen is a company that provides auditing services in the domain of distributed systems. Software development teams partner with Jepsen to check that their software does what they say it does.
Writing correct programs is a challenge, and writing concurrent programs is even more challenging. Writing “correct” distributed programs is a next-level challenge because it requires that engineers think not only about the edge cases and implicit memory state, but also about the implicit state of the hardware and network.
Since it's not uncommon for mistakes to occur, passing the Jepsen system audit acts as a public quality indicator.
Typically, a Jepsen partnership lasts several months and includes analyzing the documentation, writing custom test harnesses, and running multiple tests with specialized fault injections. Jepsen uses an open source framework (also called Jepsen) to identify consistency issues. It's useful to think about the framework the same way we think about unit testing frameworks – JUnit, ScalaTest, and unittest. They simplify writing unit tests, but the real value comes from the tests and not the libraries.
The same holds true with Jepsen. The framework may be used by a company on its own, but the real value comes from the expertise of the people behind it and their ability to tune the framework and write new tests covering a system.
Redpanda partnered with Jepsen and worked together for several months to make sure that Redpanda doesn't have consistency issues by the end of the partnership.
How did Redpanda fare in its Jepsen testing? Redpanda is a safe system without known consistency problems. The consensus layer is solid. The idempotency and transactional layers had issues that we have already fixed. The only consistency findings we haven't addressed reflect unusual properties of the Apache Kafka ® protocol itself, rather than of a particular implementation.
Let's review the Jepsen report. The discovered issues can be classified into two categories – consistency and availability – based on which of the fundamental properties of the distributed systems they affect: safety or liveness.
The safety property requires that something bad will never happen, particularly that a system doesn't violate its specification. For example:
Safety is like trust in that even a single incident compromises it.
The practical implication of having a consistent system is to ensure an application developer to rely on the guarantees instead of writing code to counter the anomalies.
The Jepsen testing confirmed the consistency bugs that we had already found (3039, 3003, 3036) using in-house chaos tests, revealed new safety problems and verified that we fixed all of them. Overall, the report mentions the following consistency issues:
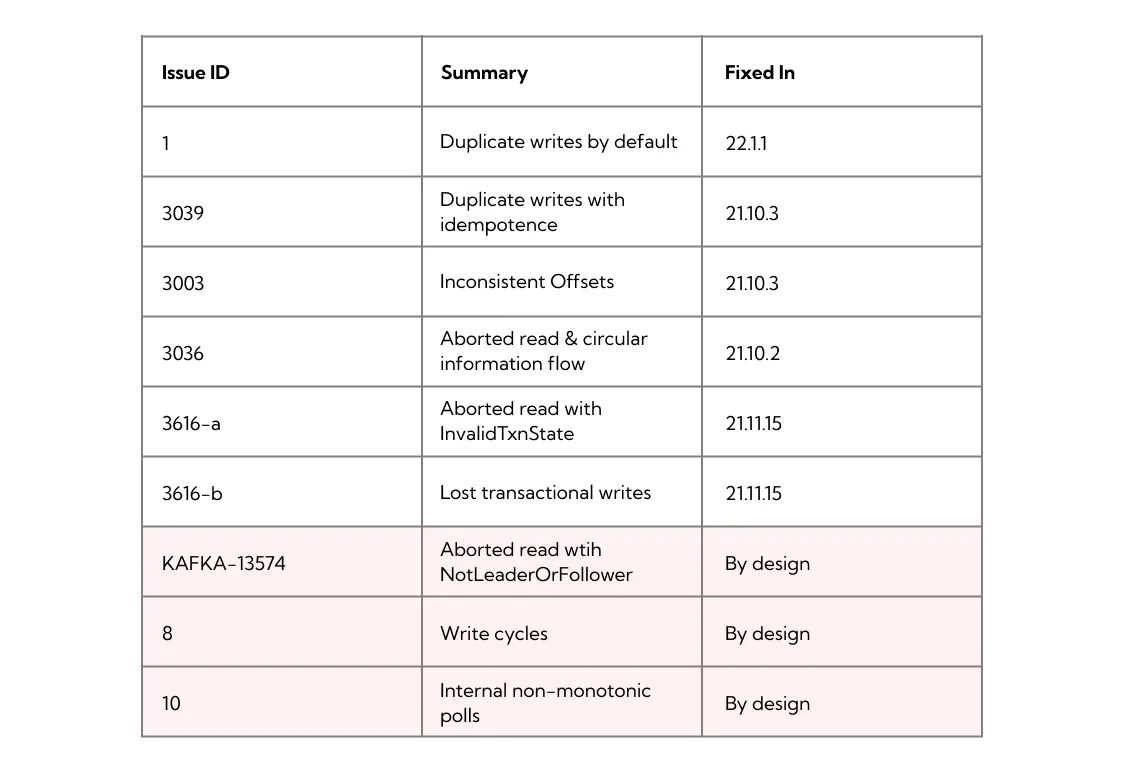
The aforementioned “by design” issues (highlighted in pink) are fundamental parts of the Kafka protocol. Viewed from the lens of a database transactional model, they might look like safety violations, but they are not. Instead, they are the result of a design decision that affects all Kafka protocol implementations, including Kafka, Redpanda and Pulsar, and that behavior is familiar to Kafka practitioners.
We discuss write cycles below while KAFKA-13574 is described in the linked issue and the internal non-monotonic polls are caused by the degenerate group rebalancing (see the report).
Safety doesn't cover non-functional requirements. A system may reject every request and still be deemed 100% safe — the system doesn't make progress so it can't be caught lying.
But when a system is down, it is far from being useful. The liveness property covers this gap and states a system should make progress. Unfortunately, total availability is impossible to achieve with consistent systems. Even when the system is perfect and doesn't have bugs, a faulty network may completely stall the progress. See "Impossibility of Distributed Consensus with One Faulty Process" (the FLP result) for details.
This impossibility result shifts discussion into the probability domain and is the reason why we talk about the number of nines in the context of high availability, while never reaching the limit of 100% availability. Jepsen revealed the following availability issues in Redpanda:
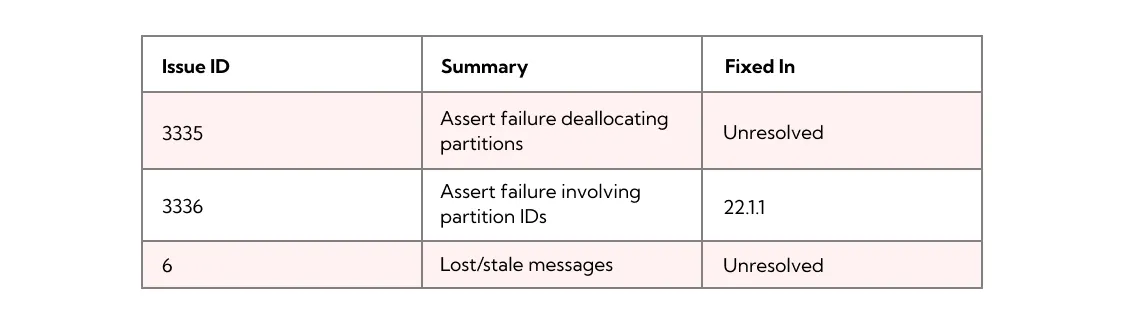
We're still investigating the highlighted issues. Fortunately, in terms of impact and frequency, those availability issues have more leeway around when we address them — especially compared to consistency bugs. They don't cause data loss and don't reorder the events.
Kyle Kingsbury, creator of the Jepsen testing framework, helped us to look at the Kafka transactional protocol with a fresh set of eyes and to recognize the fundamental differences between Kafka and database transactional models.
The database world has isolation levels to describe the variations between different transaction models: read committed, snapshot isolation, serializability, strict serializability, etc. One level is stronger than another when it prevents more anomalies. For example, read committed is the weakest isolation level because it prevents the least number of anomalies.
Initially, the isolation levels were informally defined. Later, the definitions grew more precise:
Databases support general purpose computations and don't know about the application semantics. As a result, databases may solve control concurrency in only a very general way, which leads to coarse granularity of the isolation levels.
More specifically, under serializability a database spec enforces the property that any allowed concurrent execution of the transactions should be equivalent to the sequential execution of the same transactions. This requirement isn't so strict for read-only transactions and varies based on the isolation level, but for the write transactions it's true no matter the isolation level. And when the sequential execution is violated, it's known as a G0 anomaly (write-write conflict).
For example, consider two concurrent transactions: {a=0; b=0;} and {a=1; b=1;}. When G0 is prohibited, we may only have two outcomes: {a:0,b:0} and {a:1,b:1}. With G0 the transactions may also get interweaved results: {a:0,b:1} and {a:1,b:0}.
The fact that the weakest isolation model outlaws G0 doesn't make G0 useless in other transactional models. Let's refer to the parallel domain – consensus to understand why G0 may be useful.
Note that when consensus folks talk about linearizability, they are really referring to the order of the updates. When database folks talk about serializability, they are really referring to the order of the transactions, independent of time. Those concepts are very similar so we may draw parallels between the domains.
Imagine that we need to build a replicated data structure store (something like Redis). When the list of the data structures isn't finalized the only general approach for replication we can use is to take Paxos or Raft and execute all updates in order.
The magic happens when the list of the supported data structure is known ahead of time so we can choose a specialized replication protocol. For example, when the data structure operations commute (like add operation with the sets) we may use CRDT replication. With CRDT the replication of different operations happens in parallel and it's impossible to deduce the global order.
Paxos & CRDT chose different approaches in the universality/performance tradeoff. From the database perspective the CRDT approach looks exactly like G0, but the lack of order doesn't limit CRDT practicality — we just used it to design a functional data structure store.
The difference between Kafka and database transactions is about the same universality / performance tradeoff. Databases are universal. They support plenty of operations and can be used to model various processes including Kafka. On the other hand, Kafka (if we oversimplify) is just a collection of named append-only lists. A database is an engine while Kafka is a pipe. This specialization pays off with the concurrency control: Kafka/Redpanda knows ahead of time that all the operations are compatible and may execute them in parallel, which from the DB perspective looks like G0.
Kafka has its own model and the attempts to fit it into database formalism may give one the impression that it's broken beyond repair:
“Redpanda engineers make an even stronger claim: If two different transactional IDs ever interact with the same topic, guarantees within a single transactional ID, and even within a single transaction, go out the window.”
“Kafka and Redpanda offer less of a transaction system in the sense that database users are accustomed to, and more of a choose-your-own-adventure book in which half the pages are missing, critical plot points are scrawled in the margins by other readers, and most paths lead to silent invariant violations.”
Unfortunately, the Kafka protocol is in its early days compared to relational databases and we don't have a formal model describing it at the time of this writing. But that doesn't mean we lack the model. It's implicit and scattered through the documentation, KIPs and the implementation. But this situation isn't unique; people have been using databases since the 70s and knew about their behavior long before the model became formalized in academia.
The Redpanda/Kafka model includes the following properties:
The implications of this design are that it's possible to make transactions incredibly fast. For example Redpanda does up to 5K distributed (cross-shard) replicated transactions per second on moderate hardware. It would be mind blowing for a database to achieve the same result.
Another thing Kyle helped us to realize is that we don't advertise our API well enough. The report mentions a hidden API:
“Membership changes involved undocumented HTTP APIs (and new ones had to be built in order to perform membership changes safely) but Jepsen is confident that this process can be streamlined”
“As of this writing, Redpanda documentation still did not mention how to remove nodes from the cluster ... operators who wish to perform node changes more safely (or rapidly!) can use a new API”
“Even in production mode, Redpanda did not provide fault tolerance by default for its transaction coordinator, ID allocator, and internal metadata. This allowed Redpanda to run on a single-node installation out of the box, but could lead to safety issues if a single node fails.”
Let us use this blog post as an opportunity to give a sneak peak into the hidden parts that haven't gotten yet to our docs and clarify the mentioned fault tolerance thing.
We start with something known and use docker to run a single instance of Redpanda:
docker network create -d bridge redpandanet && \
docker volume create redpanda1 && \
docker volume create redpanda2 && \
docker volume create redpanda3
docker run -d --pull=always --name=redpanda-1 --hostname=redpanda-1 --net=redpandanet -p 8082:8082 -p 9092:9092 -p 9644:9644 -v "redpanda1:/var/lib/redpanda/data" docker.vectorized.io/vectorized/redpanda:v21.11.15 redpanda start --smp 1 --memory 1G --reserve-memory 0M --overprovisioned --node-id 0 --check=false --pandaproxy-addr 0.0.0.0:8082 --advertise-pandaproxy-addr 127.0.0.1:8082 --kafka-addr 0.0.0.0:9092 --advertise-kafka-addr 127.0.0.1:9092 --rpc-addr 0.0.0.0:33145 --advertise-rpc-addr redpanda-1:33145 --set redpanda.enable_idempotence=trueIt clearly isn't fault tolerant because it's just a single node. But if we have only a cluster's endpoint and don't know its size, how can we find it? There is a command for it:
curl http://127.0.0.1:9644/v1/cluster_view
> {"version": 0, "brokers": [{"node_id": 0, "num_cores": 1, "membership_status": "active", "is_alive": true, "disk_space": [{"path": "/var/lib/redpanda/data", "free": 321733550080, "total": 696893898752}], "version": "v21.11.15 - 7325762b6f9e1586efc60ab97b8596f08510b31a-dirty"}]}The response includes a list of brokers and the version of the view. Why is it important? Imagine you have a large cluster, one node got isolated then you added a new node, decommissioned it and want to check that the decommissioning is over. How do you do it? You ask a random node for the list of brokers and wait until the decommissioned node isn't there. Without the version you may reach the isolated node and since it never knew the decommissioned node you could get a premature signal that it is removed. A monotonically increasing version gives you an opportunity to validate that the view without the node comes after the view with the node and to avoid the false signal.
We haven't created any topic yet and the cluster is empty. But even in its initial state it includes an internal topic that plays a role similar to ZooKeeperⓇ in Kafka. Let's check its replication factor.
curl http://127.0.0.1:9644/v1/partitions/redpanda/controller/0
> {"ns": "redpanda", "topic": "controller", "partition_id": 0, "status": "done", "leader_id": 0, "raft_group_id": 0, "replicas": [{"node_id": 0, "core": 0}]}The cluster has only one node so the replication factor is one. By the way, we also use another system topic to store the producer IDs but we create it on demand so we need to produce at least one record to create it. Let's do it:
docker exec -it redpanda-1 rpk topic create topic1
docker exec -it redpanda-1 bash -c "echo foo | rpk topic produce topic1"And then check that the internal topic is created
curl -v http://127.0.0.1:9644/v1/partitions/kafka_internal/id_allocator/0
> {"ns": "kafka_internal", "topic": "id_allocator", "partition_id": 0, "status": "done", "leader_id": 0, "raft_group_id": 2, "replicas": [{"node_id": 0, "core": 0}]}It's time to add new nodes to the cluster:
docker run -d --pull=always --name=redpanda-2 --hostname=redpanda-2 --net=redpandanet -p 9093:9093 -v "redpanda2:/var/lib/redpanda/data" docker.vectorized.io/vectorized/redpanda:v21.11.15 redpanda start --smp 1 --memory 1G --reserve-memory 0M --overprovisioned --node-id 1 --seeds "redpanda-1:33145" --check=false --pandaproxy-addr 0.0.0.0:8083 --advertise-pandaproxy-addr 127.0.0.1:8083 --kafka-addr 0.0.0.0:9093 --advertise-kafka-addr 127.0.0.1:9093 --rpc-addr 0.0.0.0:33146 --advertise-rpc-addr redpanda-2:33146 --set redpanda.enable_idempotence=true
docker run -d --pull=always --name=redpanda-3 --hostname=redpanda-3 --net=redpandanet -p 9094:9094 -v "redpanda3:/var/lib/redpanda/data" docker.vectorized.io/vectorized/redpanda:v21.11.15 redpanda start --smp 1 --memory 1G --reserve-memory 0M --overprovisioned --node-id 2 --seeds "redpanda-1:33145" --check=false --pandaproxy-addr 0.0.0.0:8084 --advertise-pandaproxy-addr 127.0.0.1:8084 --kafka-addr 0.0.0.0:9094 --advertise-kafka-addr 127.0.0.1:9094 --rpc-addr 0.0.0.0:33147 --advertise-rpc-addr redpanda-3:33147 --set redpanda.enable_idempotence=trueAnd check its size using the cluster_view API
curl -v http://127.0.0.1:9644/v1/cluster_view
> {"version": 12, "brokers": [{"node_id": 0, "num_cores": 1, "membership_status": "active", "is_alive": true, "disk_space": [{"path": "/var/lib/redpanda/data", "free": 321592573952, "total": 696893898752}], "version": "v21.11.15 - 7325762b6f9e1586efc60ab97b8596f08510b31a-dirty"},{"node_id": 1, "num_cores": 1, "membership_status": "active", "is_alive": true, "disk_space": [{"path": "/var/lib/redpanda/data", "free": 321592573952, "total": 696893898752}], "version": "v21.11.15 - 7325762b6f9e1586efc60ab97b8596f08510b31a-dirty"},{"node_id": 2, "num_cores": 1, "membership_status": "active", "is_alive": true}]}If you query id_allocator fast enough you'll see that its replication factor is still one (RF=1):
curl -v http://127.0.0.1:9644/v1/partitions/kafka_internal/id_allocator/0
> {"ns": "kafka_internal", "topic": "id_allocator", "partition_id": 0, "status": "done", "leader_id": 0, "raft_group_id": 2, "replicas": [{"node_id": 0, "core": 0}]}This is what Kyle means when he writes "Redpanda did not provide fault tolerance by default," but if you wait about a minute and check again you'll notice that the replication factor is increased:
curl -v http://127.0.0.1:9644/v1/partitions/kafka_internal/id_allocator/0
> {"ns": "kafka_internal", "topic": "id_allocator", "partition_id": 0, "status": "done", "leader_id": 1, "raft_group_id": 2, "replicas": [{"node_id": 1, "core": 0},{"node_id": 2, "core": 0},{"node_id": 0, "core": 0}]}This is a safety mechanism that mitigates an operator error if they forget to tune id_allocator_replication. But we still recommend to set id_allocator_replication explicitly and think about the automatic up-replication the same way we think about an airbag in a car. It's there to increase safety but let's not just rely on it during our daily driving.
It looks like thing are good now, but topic1 still has RF=1:
curl -v http://127.0.0.1:9644/v1/partitions/kafka/topic1/0
> {"ns": "kafka", "topic": "topic1", "partition_id": 0, "status": "done", "leader_id": 0, "raft_group_id": 1, "replicas": [{"node_id": 0, "core": 0}]}Let's up-replicate it:
curl --header "Content-Type: application/json" --request POST --data '[{ "node_id": 0, "core": 0 }, { "node_id": 1, "core": 0 }, { "node_id": 2, "core": 0 }]' http://127.0.0.1:9644/v1/partitions/kafka/topic1/0/replicasNow topic1 also has RF=3:
curl -v http://127.0.0.1:9644/v1/partitions/kafka/topic1/0
> {"ns": "kafka", "topic": "topic1", "partition_id": 0, "status": "done", "leader_id": 0, "raft_group_id": 1, "replicas": [{"node_id": 0, "core": 0},{"node_id": 1, "core": 0},{"node_id": 2, "core": 0}]}We're working on updating the docs to include those goodies.
Redpanda is a complex distributed system. Even at its core, it consists of several components: consensus, idempotency, and transactions.
Each component provides an important function and stays at the hot path of almost every request. Consensus is responsible for replication and durability, idempotency provides session guarantees and deduplication, while transactions are responsible for atomicity.
Our partnership with Jepsen helped us to check that the consensus layer is rock solid, to identify and fix problems with transactions and idempotency, to find the gaps in documentation, to gain confidence in the in-house chaos testing, and to look at the transactional model from a new perspective, inspiring us for upcoming blog posts.
It may seem that working with Jepsen would feel like working with an internal affairs investigator, but it was quite the opposite. During the months of partnership it felt like we got a new experienced colleague and, in the end, we made Redpanda safer together.
We encourage you to read the full Jepsen report here.
If you want to discuss our Jepsen results with us or other members of our community, join us on Slack. Go to our GitHub to check out our source-available code, or view our documentation for more information.
You can't scale what you can't trust. A governance layer fixes that.

What is it, why enterprises need it, and how to evaluate one

Enterprise agents need governance infrastructure, not just better models
Subscribe to our VIP (very important panda) mailing list to pounce on the latest blogs, surprise announcements, and community events!
Opt out anytime.