





Full CDC semantics land in the Iceberg output for Redpanda Connect
Your lakehouse mirrors the database, instantly.
How to use dead letter topics and asynchronous retries for reliable message processing with Redpanda.








When consuming records off a Redpanda topic, the consumer can specify Deserializers for converting keys and values. However, malformed payloads can cause errors. Spring allows you to use an ErrorHandlingDeserializer to catch deserialization errors and handle them properly. You can configure a ErrorHandlingDeserializer in combination with a DeadLetterPublishingRecoverer and DefaultErrorHandler to publish the malformed message to a dead letter topic.
Non-transient errors are deterministic and always fail when consumed, no matter how many times they are reprocessed. Messages causing these types of errors are often called poison pills. Errors in message deserialization, payload validation, and errors in the consumer code are primary causes of poison pills. They should be detected as early as possible and routed to the DLT. Spring Kafka provides mechanisms to handle such errors and route the malformed messages to the DLT.
Transient errors occur once or at unpredictable intervals, including momentary loss of network connectivity to downstream services, temporary unavailability of a service, or timeouts that arise when a service is busy. These errors are non-deterministic and have the potential for self-healing after a certain period. The recommended way to handle a transient error is to retry multiple times, with fixed or increasing intervals.
In enterprise messaging, a dead-letter queue (DLQ) holds the messages which couldn’t be processed by the consumer or routed to their destination. Redpanda, being a streaming data platform, doesn’t offer a built-in DLQ mechanism. Instead, it allows you to use an existing Redpanda topic as the dead-letter queue, referred to as the dead-letter topic (DLT). The best practice is to put the failed message into the DLT for reprocessing later.
Redpanda is a streaming data platform that allows high throughput, low latency message exchange for Kafka-compatible applications. It is designed to store and deliver messages to your consumer application reliably. Developers building event-driven applications with Redpanda work with fast-moving, unbounded streams of events. However, the consumer application is responsible for message processing and efficiently handling failures.
"Anything that can go wrong will go wrong, and at the worst possible time." - Murphy’s law.
Failures are inevitable in distributed systems. We often come across unreliable networks, botched up downstream systems, and rogue message payloads, forcing our applications to detect and handle failures as gracefully as possible.
Redpanda is a streaming data platform allowing high throughput, low latency message exchange for Kafka-compatible applications. Developers building event-driven applications with Redpanda are expected to work with fast-moving, unbounded streams of events. While Redpanda takes care of storing and delivering messages to your consumer application in a reliable manner, the consumer must undertake the responsibility in message processing and efficiently handling failures.
In this post, we discuss several error handling patterns you can implement in event consumer applications, including the dead letter channel and different variations of retry patterns. We will explore some code snippets taken from a sample Spring Kafka consumer application, which of course seamlessly works with Redpanda like any other Kafka!
In enterprise messaging, a dead-letter queue (DLQ) holds the messages which couldn’t be processed by the consumer or routed to their destination. The DLQ follows the Dead Letter Channel design pattern described in the famous Enterprise Integration Patterns book.
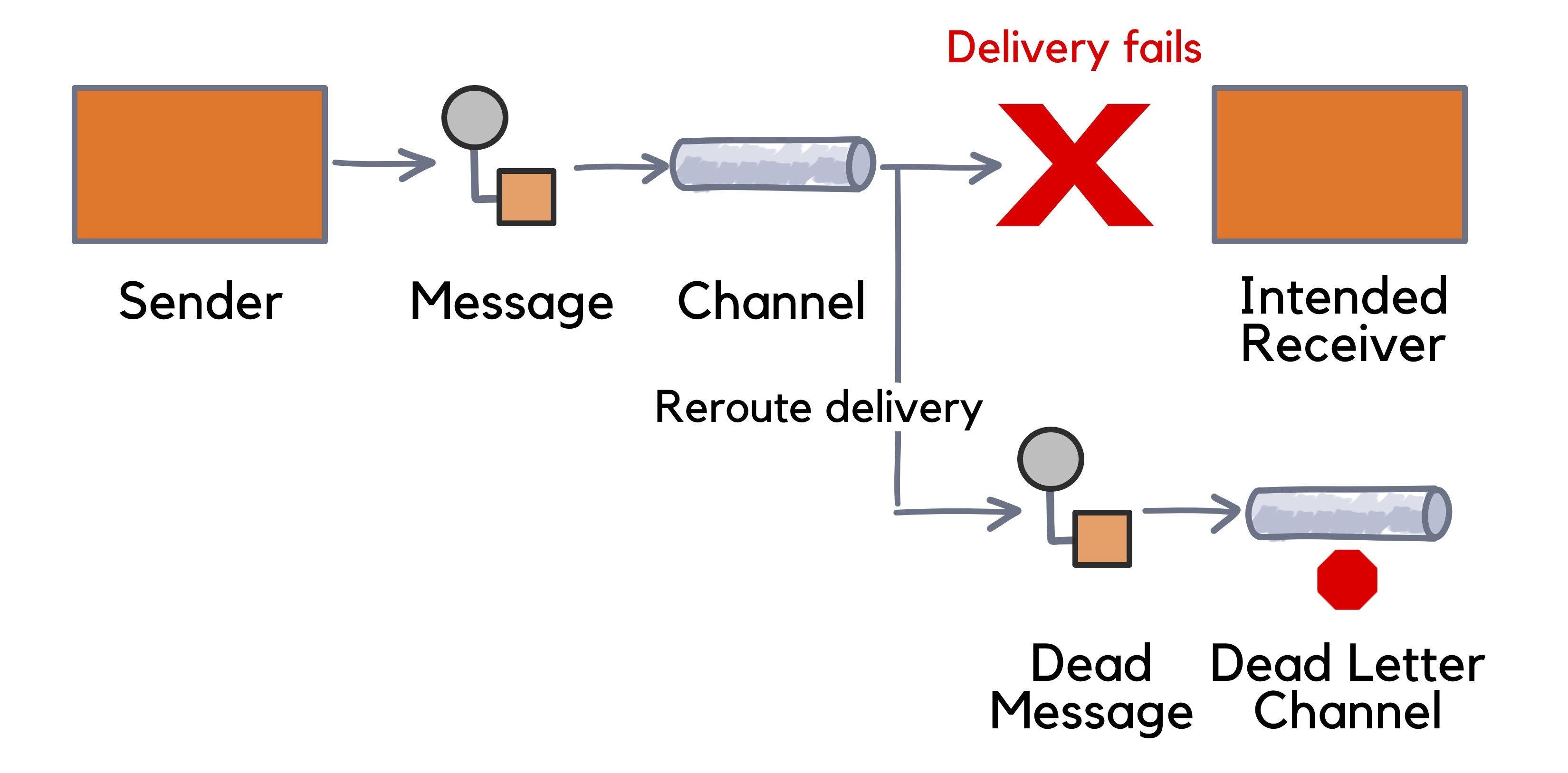
The dead-letter queue is a built-in feature in message brokers. But Redpanda being a streaming data platform, doesn’t offer a built-in DLQ mechanism; Instead, it gives you complete control over leveraging an existing Redpanda topic to be used as the dead-letter queue.
Let’s refer to it as the dead-letter topic (DLT) from now on.
A consumer may fail to process messages due to several reasons, such as corrupted or incomplete payloads, application errors in the consumer, unavailability of downstream dependencies, etc. The best practice is to put the failed message into the DLT so that we can reprocess it later.
Once Redpanda accepts a message, it ensures that the message is stored in a fault-tolerant manner until consumers read it back. But Redpanda and Apache Kafka® can’t do things like type checking of messages, schema validation, or retrying message deliveries. You, as the developer, are responsible for those types of things while developing applications and you can use the error handling patterns we discuss here as a helpful starting point.
Now that we understand the purpose of dead-letter topics. Let’s walk through a couple of use cases that utilize dead-letter topics to reliably handle message processing failures.
We will use a Java consumer application written on top of the Spring Boot framework. It leverages the Spring for Apache Kafka integration for reliable and efficient event consumption from Kafka. This integration simplifies the Kafka consumer application development by providing built-in message serialization/deserialization support, automatic recovery of failed messages and routing them to the DLT, and providing message retrying mechanisms.
You can use the same application code with Redpanda as it is compatible with Kafka APIs.
There are two error categories to consider when handling message processing failures.
The patterns we discuss in the post are available as different Spring Boot applications. You can checkout the source code from this Git repository and examine them.
Non-transient errors are deterministic and always fail when consumed, no matter how many times it is reprocessed. It will produce the same result after reprocessing, causing an infinite loop that wastes precious computational resources.
Messages that cause these types of errors are often called poison pills.
Errors in message deserialization, payload validation, and the errors in the consumer code are the primary causes of poison pills. So, they must be detected as early as possible and should be routed to the DLT.
Event-driven applications consume events over multiple formats, such as XML, JSON, Avro, Protobuf, etc. As far as Redpanda is concerned, it only sees events as an opaque sequence of bytes called a “bytearray”, allowing the producer and consumer to serialize and deserialize events as they see fit. It’s natural for a consumer to expect errors when deserializing the payload and for that reason there are “serdes” libraries that serialize and deserialize as appropriate.
When consuming records off a Redpanda topic, the consumer can specify Deserializers for converting keys and values. For example, the following Spring auto-configuration instructs the Spring framework to deserialize messages as JSON objects of type Order.
And then, you can consume them as domain objects inside the MessageListener.
However, malformed payloads never reach the listener method as they are detected by Spring framework early in the processing. Such deserialization errors are automatically logged and the execution continues. Rather than logging and dropping them, we should route the malformed messages directly to the DLT. Perhaps at a later stage, an admin can consume those from the DLT, manually fix them, and resend to the original topic.
Spring allows you to use an ErrorHandlingDeserializer to catch deserialization errors as well as handle them properly. Since Spring Kafka 2.3, you can configure a ErrorHandlingDeserializer in combination with a DeadLetterPublishingRecoverer and DefaultErrorHandler to publish the malformed message to a dead letter topic.
The following is an example configuration.
Spring Kafka will send the dead letter record to a topic named <originalTopicName>-dlt (the name of the original topic suffixed with -dlt) and to the same partition as the original record.
In this case, you will receive the message without any deserialization errors. But may not meet the validation criteria according to the business logic.
For example:
These messages reach the listener method, allowing the consumer to run a validation and raise a RuntimeException, if the validation fails. Then, the failed message will be picked up by the ErrorHandler and moved out to the DLT.
The following code shows an example.
Similar to the first scenario, this gives you the flexibility of manually reprocessing the message at a later stage.
Transient errors occur once or at unpredictable intervals, including the momentary loss of network connectivity to downstream services, the temporary unavailability of a service, or timeouts that arise when a service is busy.
These errors are non-deterministic and have the potential for self-healing after a certain period. For example, a consumer trying to save the received message to a database might get blocked due to database unavailability. Instead of dropping the message, the consumer should retry a few times, hoping that the write operation is likely to succeed when the database comes back online.
Simply put, transient errors are recoverable at the consumer’s end.
The recommended way to handle a transient error is to retry multiple times, with fixed or incremental intervals in between (back off timestamps). If all retry attempts fail, you can redirect the message into the DLT and move on.
Retrying can be implemented synchronously or asynchronously at the consumer side.
A simple blocking retry involves suspending the consumer thread and reprocessing the failed message without doing calls to Consumer.poll() during the retries.
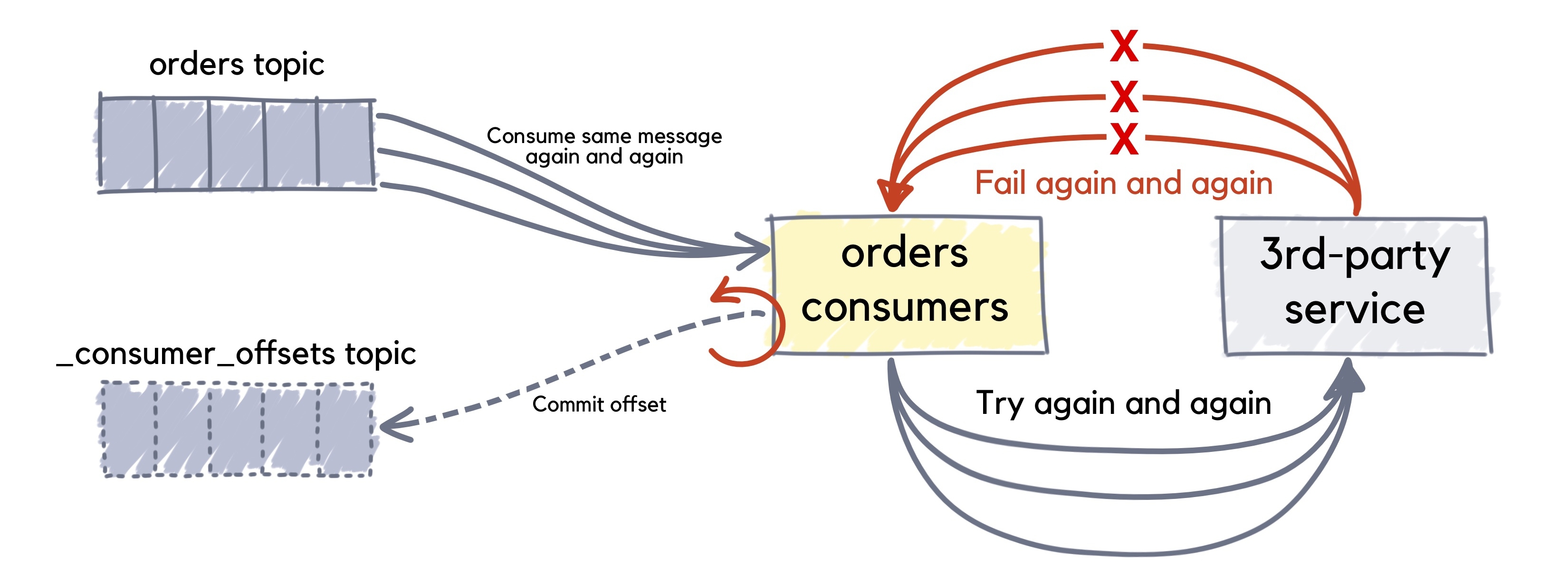
However, this has several drawbacks. When there’s a large number of messages to be processed in real time, repeatedly failed messages can block the main consumer thread. Messages consistently exceeding the retry limit take the longest time to process and use the most resources. Without a successful response, the Redpanda consumer will not commit a new offset and the batches with these bad messages would be blocked, as they are re-consumed again and again.
We should use non-blocking retries whenever possible because we must not disrupt real-time traffic as well as should not amplify the number of calls, essentially spamming bad requests.
Achieving non-blocking retry and DLT functionality with Redpanda usually requires setting up extra topics and creating and configuring the corresponding listeners. In non-blocking retry, failed deliveries are forwarded to a dedicated retry topic(s) first. A separate consumer thread reprocesses and retries the failed messages from there, freeing the main thread from being clogged.
Let’s look at two possible patterns in non-blocking retrying.
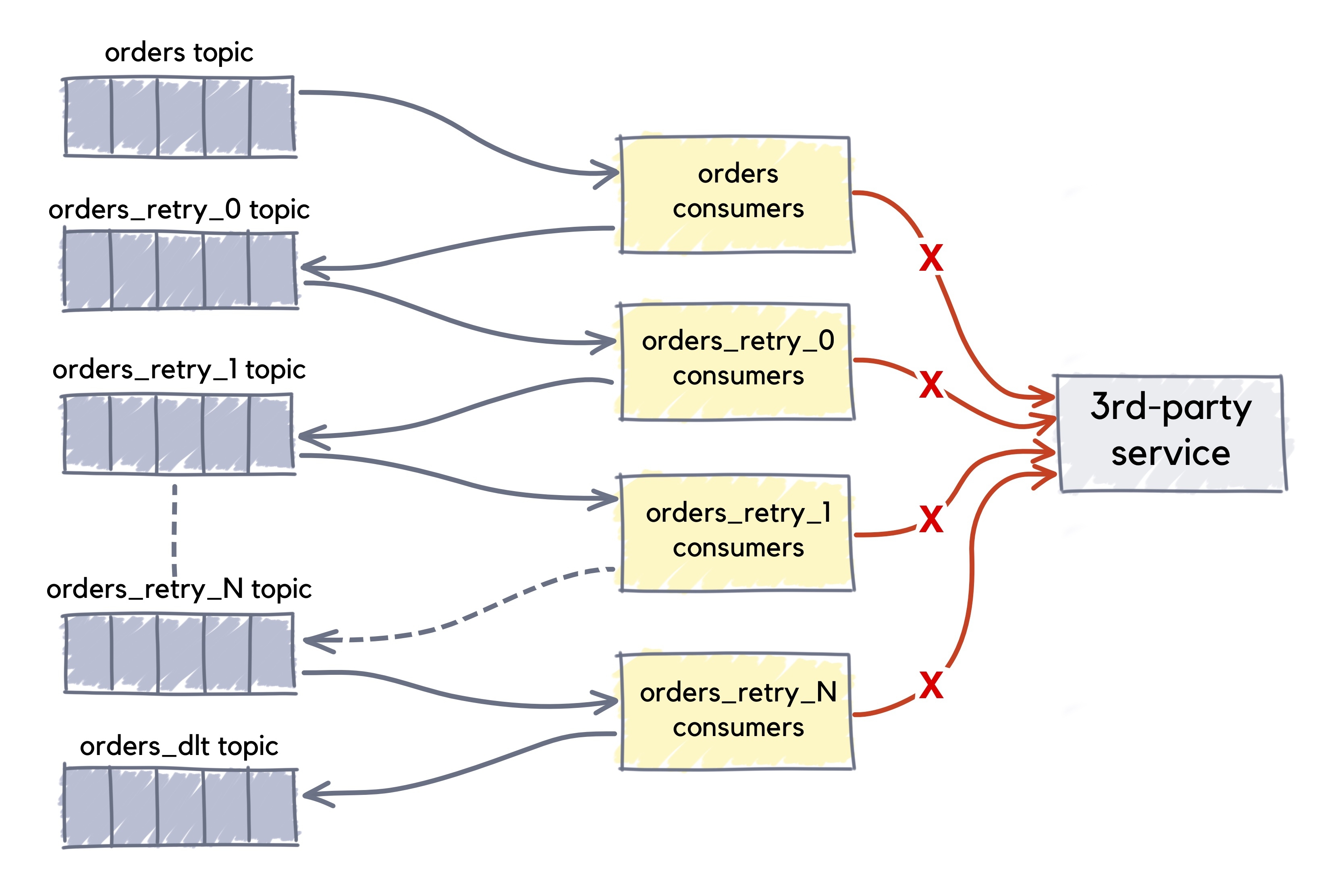
Since Spring Kafka 2.7.0, failed deliveries can be forwarded to a series of topics for delayed redelivery.
The following example contains four retry attempts for failed deliveries with an exponentially increasing backoff (retry delay).
With this @RetryableTopic configuration, the first delivery attempt fails and the record is sent to a topic order-retry-0 configured for a 1-second delay. When that delivery fails, the record is sent to a topic order-retry-1 with a 2-second delay. When that delivery fails, it goes to a topic order-retry-2 with a 4-second delay, and, finally, to a dead letter topic orders-dlt handled by @DltHandler method.
The first attempt counts against the maxAttempts, so if you provide a maxAttempts value of 4 there'll be the original attempt plus 3 retries.
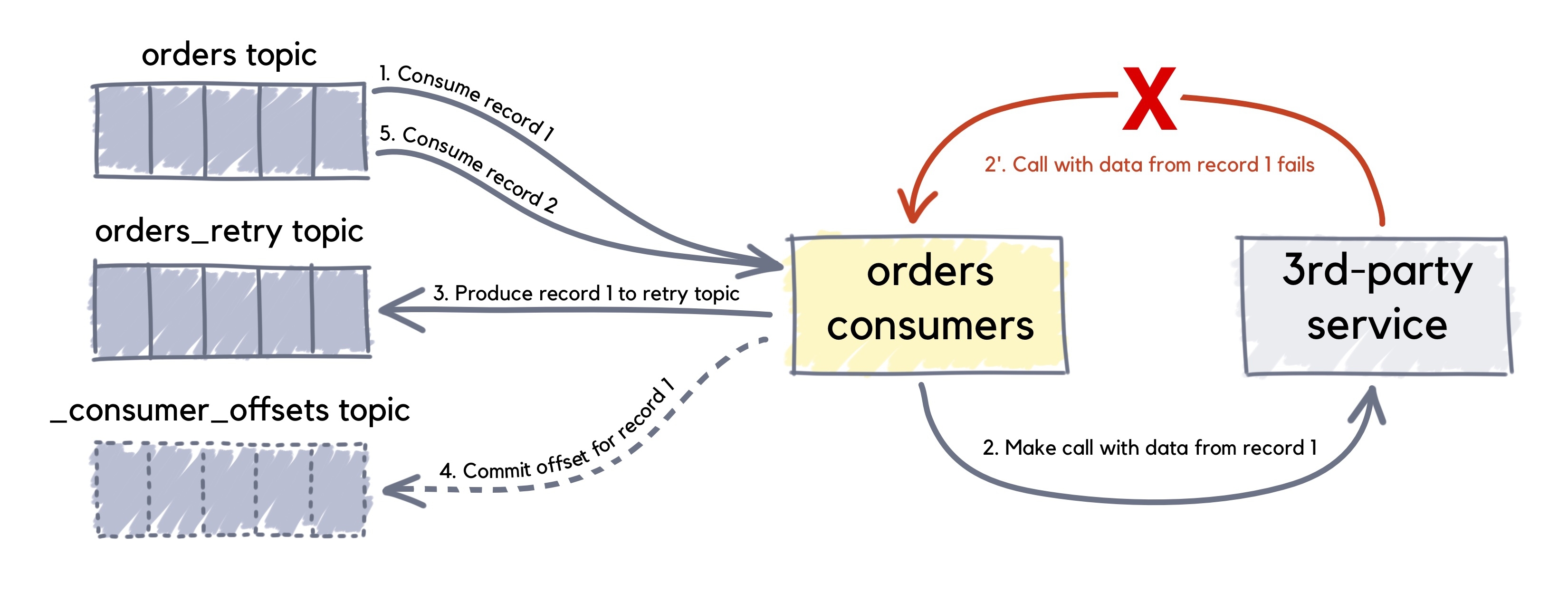
The following configuration is quite similar to the above, except it only features a single retry topic (orders-retry). Four retry attempts will be made with a fixed 1-seconds delay in between. If all attempts are exhausted, the message will be put to the dead letter topic orders-dlt.
Redpanda, as a streaming data platform, always ensures that the messages are reliably delivered to your consumer application under any circumstance; Then, it is your application’s responsibility to handle failures while processing those messages. This post discussed several patterns that you can use as guiding principles for gracefully handling failures in your consumer applications.
When a failure occurs, you should not simply drop the message and continue execution. Instead, failed messages should be forwarded to the DLT for reprocessing at a later time. That ensures reliability, traceability, and accountability across the end to end message flow.
Non-transient errors (poison pills) must be detected as early as possible in the processing pipeline and should be put in the DLT. Transient errors should be retried in a non-blocking, asynchronous manner. While doing so, you can mix and match different message reprocessing strategies like Single-Topic-Multiple-BackOff and Multiple-Topic-Exponential-BackOff.
Take Redpanda for a test drive here. Check out our documentation to understand the nuts and bolts of how the platform works, or read more of our blogs to see the plethora of ways to integrate with Redpanda. To ask our Solution Architects and Core Engineers questions and interact with other Redpanda users, join the Redpanda Community on Slack.
Subscribe to our VIP (very important panda) mailing list to pounce on the latest blogs, surprise announcements, and community events!
Opt out anytime.

