




Drag, drop, done: a visual composer for Redpanda Connect
Boxes and arrows for people who move billions of events a day. No per-row invoice required.

Learn how engineers at DataCater use Redpanda to simplify real-time application development.








To deploy Redpanda in a Kubernetes environment, you can use Redpanda's custom resource and configure it with a specific YAML description. The Redpanda operator prepares a redpanda.yaml and starts a Redpanda cluster with its configuration, including an advertised_kafka_api. This setup simplifies the networking configuration, making it less complicated for developers.
To integrate Redpanda into Java Quarkus, you need to use the quarkus-smallrye-reactive-messaging-kafka extension as a dependency in your build system. This extension will automatically pull and run a single node Redpanda installation in your local docker engine. Starting Quarkus in dev mode will then allow you to work interactively with Redpanda.
Redpanda simplifies networking for development by maintaining a simple, easy, efficient, and quick setup across multiple stages, including development, staging, and production. It integrates easily with Kubernetes (K8s) and allows for easy configuration of advertised_kafka_api for access from outside the cluster, making it a suitable choice for cloud-native and Kubernetes-first thinking.
Redpanda is a perfect fit for continuous integration due to its small footprint compared to the Kafka stack and quick startup time. Redpanda's container size is 1GB less than the combination of Kafka and ZooKeeper container images, which is beneficial when you can't guarantee to cache your pulled images in cloud-provided CI pipelines. Additionally, Redpanda's startup time is roughly six seconds, significantly less than Kafka and ZooKeeper's 10 seconds.
Redpanda is beneficial for Java-based streaming application development because it simplifies the continuous integration/continuous deployment (CI/CD) pipelines. It allows for quick and efficient spinning up of clusters, keeping workstations lightweight. Redpanda also integrates well with Java Quarkus, a Kubernetes-native Java stack, making it a suitable choice for developers targeting Kubernetes as their runtime.
At DataCater we make real-time streaming a commodity for data and developer teams. DataCater provides a user interface, API, and declarative formats for creating production-grade Kafka Streams applications. Consequently, our products utilize and evolve around Apache KafkaⓇ API-compatible technologies.
Kafka is a heavy piece of machinery, with multiple components that must be managed together to create a running instance. Components such as ZooKeeperⓇ, a separate schema registry, etc. make it unfit for modern continuous integration/continuous deployment (CI/CD) pipelines, wherein we need to spin up clusters quickly and efficiently.
Therefore, to accelerate our development cycle, we make use of Redpanda and Java Quarkus to keep our workstations lightweight and simplify our CI pipeline for end-to-end testing.
We develop our applications and services in Java to utilize the wide variety of connections and protocols readily available through frameworks like Apache Kafka ConnectⓇ and Apache CamelⓇ.
In this blog, we’ll show you how to use Redpanda to speed up and ease the burden of developing a Java-based streaming application.
Java Quarkus is a Kubernetes-native Java stack. One goal of Java Quarkus is packaging libraries, such that Java developers can create single binaries from Java programs via GraalVMTM. This leads to fast start-up times and JVM-free containers making Quarkus a go-to choice for developers targeting Kubernetes as their runtime. We use multiple Java Quarkus packages, including quarkus-smallrye-reactive-messaging-kafka, which pulls Redpanda’s docker image and runs it as a process for streaming applications.
The ease of installation, zero-config process starts, and fast startup of Redpanda has led to increasing adoption of Redpanda as the default Kafka-compatible messaging technology for development. At DataCater, we chose Redpanda as our default with Java Quarkus as well.
Once you have quarkus-smallrye-reactive-messaging-kafka extension as a dependency in your build system, Quarkus will automatically pull and run a single node Redpanda installation in your local docker engine.
Starting Quarkus in dev mode will yield the following output and you can get started on working interactively with Redpanda. This example uses the Testontainers library.
$ ./gradlew quarkusDev
…
2022-04-14 11:33:16,880 INFO [🐳 .io/.11.3]] (build-27) Pulling docker image: docker.io/vectorized/redpanda:v21.11.3. Please be patient; this may take some time but only needs to be done once.
…
2022-04-14 11:33:41,037 INFO [🐳 .io/.11.3]] (build-27) Container docker.io/vectorized/redpanda:v21.11.3 is starting: c41e717b516ad9810ca93828a72cf5203068c607996962951aa4979e08a6f15e
2022-04-14 11:33:42,539 INFO [🐳 .io/.11.3]] (build-27) Container docker.io/vectorized/redpanda:v21.11.3 started in PT25.70221SAs you can see, the command ./gradlew quarkusDev gets you started with Redpanda, whereas a Kafka cluster would require you to set up ZooKeeper alongside. Configuring ZooKeeper, Kafka, and networking on a development machine is brittle and makes setting up development environments complex.
This setup, instead, enables you to tear down and restart without having to think or be time-constrained by setting up anything new on your developer machine.
Redpanda’s small footprint compared to the Kafka stack and startup time make it a perfect fit for integration testing in our CI pipeline. First, let’s take a look at the image size:
$ docker images | grep 'debezium\|redpanda'
debezium/kafka 1.8 5da8d5410fe6 2 days ago 764MB
debezium/zookeeper 1.8 c76319be13f3 2 days ago 547MB
vectorized/redpanda v21.11.12 31f4853dadff 6 days ago 302MBThe above example takes containers for Kafka and ZooKeeper distributed by the Debezium project as examples. By the nature of Kafka and ZooKeeper, a Java runtime has to be packaged into the container. This leads to Redpanda’s size being 1GB less than the combination of Kafka and ZooKeeper container images. A huge difference, especially, if you can not guarantee to cache your pulled images when using cloud-provided CI pipelines.
Further, startup of containers for Kafka and ZooKeeper takes around 10 seconds until the broker endpoint is ready, while with Redpanda this takes roughly six seconds. Over a lot of commits and continuous testing this difference easily accumulates to minutes and hours over the period of a week or month.
Engineering teams are employing Kubernetes (K8s) and, in the process, are trying to make development environments as close to production as possible. As a software engineer, I want my tools to be as simple to set up and run with similar configurations across multiple stages. Redpanda's setup remains just as simple, easy, efficient and quick for production as it is for development or staging.
At DataCater we target K8s as our runtime environment. A common approach for exposing K8s resources outside of a given cluster is to use an Ingress, which we also use for developing a local application against services in a minikube cluster.
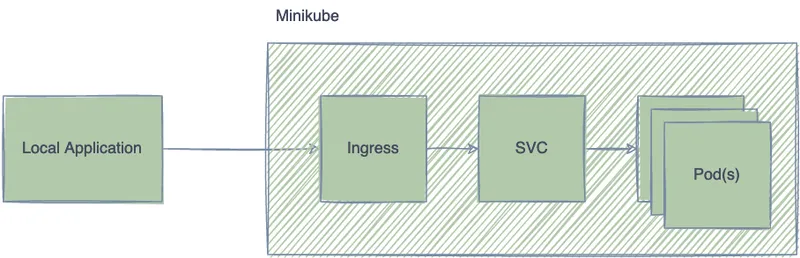
To achieve this with Redpanda, you simply deploy Redpanda via its custom resource and configure it with the following YAML description:
configuration:
kafkaApi:
- port: 9092
pandaproxyApi:
- port: 8082
adminApi:
- port: 9644 The Redpanda operator prepares a redpanda.yaml and starts a Redpanda cluster with its configuration including an advertised_kafka_api.
The strimzi-kafka-operator deploys a Kafka cluster with all its dependencies and networking configuration.
Kafka’s networking makes this much more complicated for developers using strimzi-kafka-operator. The equivalent to advertised_kafka_api is only known upon initial deployment. Hence, developers need to adjust their K8s manifest and re-deploy Kafka via strimzi-kafka-operator after any change to a Kafka cluster.
An example from their blog:
listeners:
external:
type: ingress
configuration:
bootstrap:
host: kafka-bootstrap.localhost
brokers:
- broker: 0
host: kafka-broker-0.localhost
- broker: 1
host: kafka-broker-1.localhost
- broker: 2
host: kafka-broker-2.localhostNow that you’ve seen how we use Redpanda to speed up and simplify the burden of developing a data-streaming application, you can improve your own development projects!
At DataCater, we use Redpanda to speed up the development of our core product. Redpanda easily integrates in our development stack with Java Quarkus, reducing time and size of our CI pipeline, and Redpanda’s ease of configuration helps us to test Kafka workloads easily on a new Kubernetes cluster. Setting up advertised_kafka_api for access from outside the cluster makes working with Redpanda a charm, and really reaps the benefit of thinking cloud-native and Kubernetes-first.
So, a big thank you to the engineering team at Redpanda for creating a great developer experience! Check out the Redpanda GitHub repo, or go to their documentation to learn more. Join the Redpanda Community on Slack to interact with me and Redpanda’s engineers directly.
Subscribe to our VIP (very important panda) mailing list to pounce on the latest blogs, surprise announcements, and community events!
Opt out anytime.

