




Full CDC semantics land in the Iceberg output for Redpanda Connect
Your lakehouse mirrors the database, instantly.
Correctly size your Redpanda clusters by understanding how to manage the key variables that will maximize cluster performance.









For data retention, this blog recommends using Redpanda’s Tiered Storage, a multi-tiered remote storage solution that archives log segments to S3-compatible object storage in near real-time. This can be combined with local storage to provide infinite data retention and disaster recovery on a per-topic basis.
To maximize I/O performance, this blog recommends a 2:1 core-to-disk ratio for production-level workloads. At minimum, four cores should be used for any production-level workload. This is because Redpanda is a distributed transaction log that appends data to the end of log files, and sequentially reads data from log files, managing its own memory and disk input/output (I/O).
This blog mentions four key considerations: I/O performance, memory-per-core, network bandwidth, and storage solution. These factors determine how efficiently Redpanda can use available hardware, scale up to get the most out of your infrastructure, and meet the throughput or resiliency requirements of your workload.
This blog suggests allocating a minimum of 2GB of memory per core for Redpanda. However, more memory is generally preferred. This is based on Redpanda's ability to handle approximately 1 GB/sec of writes per core, depending on the workload.
Measuring network bandwidth is crucial for providing the most predictable and reliable performance for your cluster. This is especially important for cloud deployments, where network bandwidth is not always guaranteed. Total network bandwidth needs to account for writes, replication, and reads.
If you’re new to Redpanda and are just taking it for a test drive (hey, thanks for checking us out!) our out-of-the-box configuration settings will handle your data streaming experiments just fine. If, however, you plan to use Redpanda for production-level applications and microservices, fine-tuning your cluster configurations will allow you to get the best performance possible from your production workloads.
This is important because an undersized Redpanda cluster will hit bottlenecks at some point along the data path. The clients might saturate the available network bandwidth, a disk might run out of IOPS and not be able to keep up with writes, or you may simply run out of disk space. On the other hand, an oversized Redpanda cluster will be underutilized, causing you to pay for excess infrastructure. Understanding proper cluster sizing will help you find the sweet spot in between these scenarios and achieve cost-effective cluster performance.
This post covers the basics of what you need to know about sizing your Redpanda clusters for production. If you want even more information about cluster sizing, download our free guide on Redpanda’s architecture and sizing guidelines.
Redpanda is designed to exploit the advances in modern hardware, from the network down to the disks. To do this, Redpanda uses an advanced thread-per-core model to pin its application threads to the cores on a modern CPU. It combines this with structured message passing (SMP) to asynchronously communicate between the pinned threads. This allows Redpanda to avoid the overhead of context switching and expensive locking operations to significantly improve processing performance and efficiency. Essentially, Redpanda behaves like a distributed system across cores to maximize processing performance.
From a sizing perspective, Redpanda’s ability to efficiently use all available hardware allows it to scale up to get the most out of your infrastructure, before you are forced to scale out to meet the throughput or resiliency requirements of your workload. Thus we’re able to deliver better performance with a smaller footprint, resulting in reduced operational costs and burden.
With this in mind, let’s consider four of the most important variables that need to be considered when sizing Redpanda clusters for your mission-critical, production environments.
At its core, Redpanda is a distributed transaction log with well-understood access patterns. It appends data to the end of log files, and sequentially reads data from log files. For this reason Redpanda bypasses the Linux page cache and manages its own memory and disk input/output (I/O). This gives Redpanda complete control over the underlying hardware to optimize I/O performance, deliver predictable tail latencies, and control its memory footprint.
In order to maximize I/O performance, a 2:1 core-to-disk ratio is recommended for production-level workloads and, at minimum, four cores should be used for any production-level workload.
Takeaway: Use a 2:1 core-to-local-disk ratio for maximum I/O performance (at current time of this writing, local NVMe SSD is the best option).
Redpanda’s thread-per-core programming model is implemented through the Seastar library, which is an advanced framework for high-performance server applications on modern hardware. This allows Redpanda to pin each of its application threads to a CPU core to avoid context switching and blocking, significantly improving processing performance and efficiency.
A good general rule of thumb to follow is that Redpanda can handle approximately 1 GB/sec of writes per core, depending on the workload. NVMe disks can have a sustained write speed of over 1 GB/sec, thus, it takes two cores to saturate a single NVMe disk. The baseline recommendation for memory allocation in production clusters of Redpanda, is 2GB of memory per core, but more is preferred.
Takeaway: Allocate a minimum of 2GB of memory per core, but generally speaking more memory is always preferred.
If you’re trying to provide the most predictable and reliable performance for your cluster, it’s important to measure the network bandwidth between nodes, and between clients and nodes in your Redpanda clusters. This is especially important for cloud deployments, where network bandwidth is not always guaranteed.
Note: “Nodes” refer to what you may know as “brokers” in Kafka.
For example, AWS i3en instances only guarantee network bandwidth above a certain instance size (i3en.6xlarge). Below that size network bandwidth is advertised as “up to 25 Gbps”. For this reason, it’s a good idea to “soak test” the network to understand how it behaves over longer periods of time.
Takeaway: Total network bandwidth needs to account for writes, replication, and reads.
When it comes to selecting the best storage solution for your workload, both performance and data retention must be considered. If high throughput and low latency is paramount then look no further than locally attached NVMe SSD disks. Yet, the downside of having only local storage is that data retention is limited to the provisioned capacity, and you are forced to decide between using what is available and having a limit on the amount of data you can retain in the system, or continuing to scale out (add more nodes) to increase capacity.
This is why we created Redpanda’s Tiered Storage, which is a multi-tiered remote storage solution that provides the ability to archive log segments to S3-compatible object storage in near real-time. Tiered Storage can be combined with local storage to provide infinite data retention and disaster recovery on a per-topic basis.
Takeaway: Use Tiered Storage to unify historical and real-time data.
With the four guidelines above in mind, let's take some requirements and see how to translate them into a production-ready cluster specification:
Producing an average of 500 MB/sec and consuming an average of 1,000 MB/sec will equate to 2,500 MB/sec (20 Gbps) of network bandwidth when factoring in the replication traffic. The cloud providers have fast networks so this amount of bandwidth will be attainable in the cloud, if you pay for it, but these speeds are not as prevalent throughout a typical data center.
Given a sensible partition count (e.g. at least one partition per core) the 500 MB/sec of data coming from the producers will be evenly distributed between the nodes. For example, with 3 nodes each node will receive approximately 167 MB/sec.
Note the additional 500 MB/sec added to the consumer throughput. This is to account for the use of Tiered Storage and the additional bandwidth required to archive log segments to object storage. When Tiered Storage is enabled on a topic it essentially adds another consumer's worth of bandwidth on the network. Producing an average of 500 MB every second equates to over 40 TB of data per day and, given a retention period of one year, the cluster is going to need over 14 PB of storage. This is more than can be squeezed into three nodes so, in this scenario, you would be forced to overprovision just to handle the data retention requirements. This is not as much of an issue in the cloud with an abundance of high-performance persistent storage options but, at this scale, it would be very expensive. Thus, Tiered Storage will be helpful here.
A topic with Tiered Storage enabled has the ability to write to faster local storage that is managed by local retention settings and, at the same time, write the data to object storage that is managed by different retention settings, or left to grow indefinitely. Consumers that generally keep up with producers will stream from local storage but, at this velocity, that window of opportunity is narrower. The object store is always there as backup if a consumer needs to read from an older offset.
The below table is an example of recommended instance types used in a production cluster:
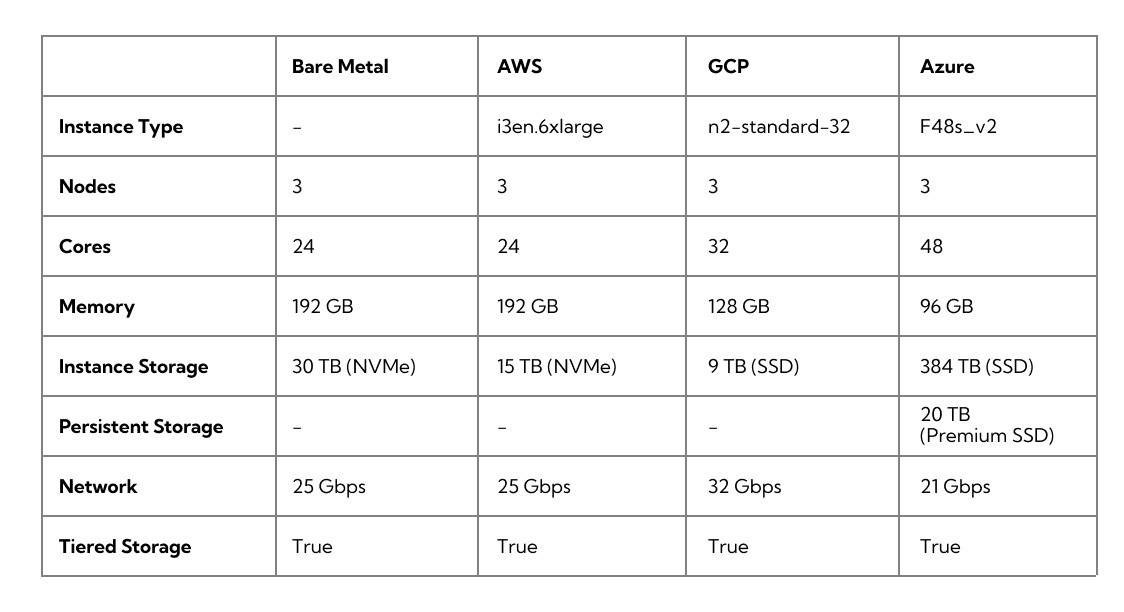
Now that you understand some of the dependent variables that affect cluster sizing, you can make sure your clusters are sized correctly to get the best results from your production workloads. This will help you avoid creating a cluster that is either too small or too large for your workloads’ needs.
For more information about sizing Redpanda clusters for production, you can consult our deployment documentation here, or download our free guide on cluster sizing, which contains additional example scenarios, details about Redpanda’s architecture, and hardware recommendations for running Redpanda in your own data center or in the cloud.
Subscribe to our VIP (very important panda) mailing list to pounce on the latest blogs, surprise announcements, and community events!
Opt out anytime.

