





Full CDC semantics land in the Iceberg output for Redpanda Connect
Your lakehouse mirrors the database, instantly.

Watch Sovereign AI in action and send the model to your data








It’s easy to stand in awe of AI’s capabilities, but there’s a growing awareness of all the different platforms and corporations squirreling away our data. At Redpanda Streamfest, my live session focused on showcasing the value and importance of Sovereign AI, a safer way to build where instead of sending your data to the AI model, Redpanda sends the model to your data so everything stays within your network.
You can watch all the Streamfest sessions on-demand, but if you’d rather just scroll through the steps, here’s the rundown.
In short, my demo was of an e-commerce application that triggers an engagement follow-up email using RAG, ClickHouse, and Redpanda Connect — all running locally on my GPUs and without a single call out to a public API.

Here's an outline of what we want our pipeline to do:
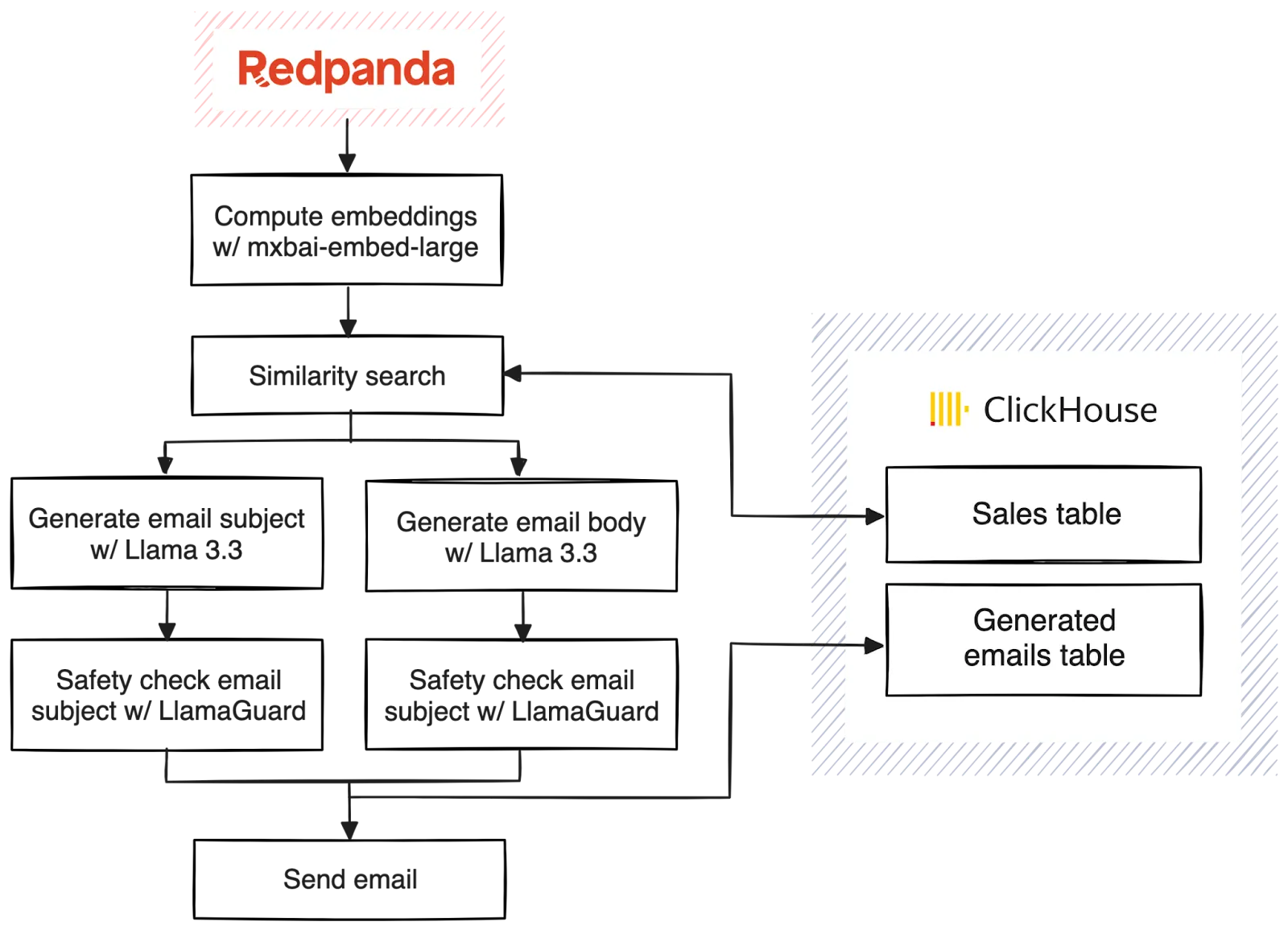
This will all be done using Redpanda Connect, a full-stream processor that can be configured using YAML, supports at-least-once transactional guarantees, automatic retries, out-of-the-box metrics, and hundreds of different plugins.
The pipeline will process transactions as they happen in real time. Computing vector embeddings based on the product description to look up similar purchases by other customers in Clickhouse. Once we have those similar products, we'll use an LLM to personalize and generate a one-of-a-kind email to send to our customer. The email will be checked by LlamaGuard, and then we will write the email back to Clickhouse along with the original transaction (to be used for future vector searches).
That's a lot to grok all at once, so let's break it down and build it up, brick by brick.
Like all good AI applications, the magic ingredient to making them good is data. Before we get started, we need a dataset of purchases so that our model, Llama 3.2, can provide awesome follow-up recommendations via email to our customers. I don't actually have an e-commerce side hustle that I can mine for data, so we'll have to settle with a dataset from Kaggle.
We have data, but before we start running vector searches against it in our pipeline, we're going to need to quickly ingest that and some embeddings into ClickHouse before we can get started. We'll use one of the leading embeddings models by MixedBread.ai - mxbai-embed-large. Redpanda Connect makes that a breeze with its sql_insert output and ollama_embeddings processor. Here's the full configuration file:
input:
file:
paths: ["./amazon.csv"]
scanner:
csv: {}
pipeline:
processors:
- branch:
processors:
- ollama_embeddings:
model: mxbai-embed-large
text: |
User ${!this.user_name} bought a product called ${!this.product_name},
which has the category ${!this.category} for ${!this.discounted_price}.
The product description is ${!this.about_product}
They gave a review: ${!this.review_content}
result_map: |
root.text_embedding = this
output:
sql_insert:
driver: "clickhouse"
dsn: clickhouse://localhost:9000
init_statement: |
CREATE TABLE IF NOT EXISTS sales (
txn_id TEXT,
product_id TEXT,
product_name TEXT,
category TEXT,
discounted_price TEXT,
actual_price TEXT,
dicount_percentage TEXT,
rating TEXT,
rating_count TEXT,
about_product TEXT,
user_id TEXT,
user_name TEXT,
review_title TEXT,
review_content TEXT,
img_link TEXT,
product_link TEXT,
text_embedding Array(Float32)
) ENGINE = MergeTree()
ORDER BY txn_id
PRIMARY KEY txn_id
table: sales
columns:
- txn_id
- product_id
- product_name
- category
- discounted_price
- actual_price
- dicount_percentage
- rating
- rating_count
- about_product
- user_id
- user_name
- review_title
- review_content
- img_link
- product_link
- text_embedding
args_mapping: |
root = [
this.review_id,
this.product_id,
this.product_name,
this.category,
this.discounted_price,
this.actual_price,
this.dicount_percentage,
this.rating,
this.rating_count,
this.about_product,
this.user_id,
this.user_name,
this.review_title,
this.review_content,
this.img_link,
this.product_link,
this.text_embedding,
]
To run it, you're going to need to have rpk installed locally, a Redpanda license key and also have ClickHouse running locally in the background.
rpk connect upgrade # make sure you're running the latest hotness
rpk connect run ./ingest.yamlNow that we have a fully loaded ClickHouse with sales data, we can start reading data and searching for similar records. To make local testing easy, we're going to our Redpanda Connect's generate input to create a fake record to test our pipeline. Like our ingestion pipeline, we'll pump those records through mxbai-embed-large before asking ClickHouse for similar purchases.
input:
generate:
count: 1
mapping: |
root = {}
root.txn_id = uuid_v4()
root.product_id = "B07GVGTSLN"
root.product_name = "Samsung Galaxy S10E"
root.category = "Computers&Accessories"
root.discounted_price = "₹1,299"
root.actual_price = "₹1,299"
root.about_product = fake("paragraph")
root.user_id = "AEXK37TSBFHSP2TYE63YPKETWQ7Q"
root.user_name = "Avninder Singh"
pipeline:
processors:
- branch:
processors:
- ollama_embeddings:
model: mxbai-embed-large
text: |
Represent this sentence for searching relevant passages:
User ${!this.user_name} bought a product called ${!this.product_name},
which has the category ${!this.category} for ${!this.discounted_price}.
The product description is ${!this.about_product}
result_map: |
root.query_embedding = this
- branch:
processors:
- sql_raw:
driver: "clickhouse"
dsn: clickhouse://localhost:9000
query: |
SELECT * FROM sales
WHERE product_id != $1 AND user_id != $2
ORDER BY cosineDistance($3, text_embedding)
LIMIT 3
args_mapping: root = [ this.product_id, this.user_id, this.query_embedding ]
result_map: |
root.similar_products = thisNote that processors like sql_raw and ollama_embeddings replace the current message flowing through the pipeline, so to not lose the original payload, we'll use the branch processor to fold it back in.
Now we get to the fun part of generating our email, then using LlamaGuard to ensure our LLM responses are high quality and safe. Let's cut straight to the processing steps:
- branch:
processors:
- ollama_chat:
model: llama3.2
max_tokens: 150
prompt: |
Your task is to generate a single email subject (nothing else)
for a customer who just bought a product called ${!this.product_name}
and is receiving a followup to entice them to come back to the store.
save_prompt_metadata: true
- ollama_moderation:
model: llama-guard3
prompt: "${!@prompt}"
response: "${!content()}"
result_map: |
root.email.subject = content().string()
root.email.subject_is_safe = @safe
- branch:
processors:
- ollama_chat:
model: llama3.2
prompt: |
A customer named ${!this.user_name} just bought a product called ${!this.product_name}.
Here are some similar products that other customers have recently bought:
${!this.similar_products.map_each(
product -> [product.product_name, product.about_product].join(" ")
).join("\n")}
Your task is to write a followup marketing email (the body only, no subject) to ${!this.user_name}
from Acme Corp (use the company name for the signature) that will thank them for their purchase
and give recommendations for them to come back based on the above similar products.
save_prompt_metadata: true
- log:
level: INFO
message: "PROMPT: ${!@prompt}"
- ollama_moderation:
model: llama-guard3
prompt: "${!@prompt}"
response: "${!content()}"
result_map: |
root.email.body = content().string()
root.email.body_is_safe = @safeWe use two branches to generate some text using our ollama_chat processor, one of which we'll also inject the search results from earlier in the pipeline. Once the text is generated, we'll use the save_prompt_metadata option to save our LLM input as metadata, then ask llama-guard3 if the response was safe.
Now that we have all the information we need, we can send our email - but not in a YOLO way. If LlamaGuard3 determined the email was unsafe, we wouldn't send anything but just write it to ClickHouse for further fine-tuning/evaluation/analysis. Here's the config using our broker output to fan out messages parallel:
output:
broker:
outputs:
- http_client:
url: "https://api.mailslurp.com/emails"
headers:
Content-Type: application/json
x-api-key: "${API_KEY}"
processors:
- mapping: |
root.to = ["Test <test@mailslurp.com>"]
root.from = "Redpanda Connect <rpcn@mailslurp.net>"
root.subject = this.email.subject.unquote().catch(this.email.subject)
root.body = this.email.body
root = if this.email.body_is_safe == "no" || this.email.subject_is_safe == "no" {
deleted()
}
- sql_insert:
driver: "clickhouse"
dsn: clickhouse://localhost:9000
table: llm_emails
init_statement: |
CREATE TABLE IF NOT EXISTS llm_emails (
txn_id TEXT,
subject TEXT,
subject_safe TEXT,
body TEXT,
body_safe TEXT
) ENGINE = MergeTree()
ORDER BY txn_id;
columns:
- txn_id
- subject
- subject_safe
- body
- body_safe
args_mapping: |
root = [
this.txn_id,
this.email.subject,
this.email.subject_is_safe,
this.email.body,
this.email.body_is_safe,
]Before sending the email, we'll have one more processing step that checks the safety responses and if they are unsafe, deletes the message from the pipeline before it's sent to our email service. However, writing back to ClickHouse is unconditional.
We'll wrap up our pipeline by sending the original transaction info that we generated back into ClickHouse and the table we use for vector search, so this transaction can be found by future transactions looking for similar products.
- processors:
- branch:
processors:
- ollama_embeddings:
model: mxbai-embed-large
text: |
User ${!this.user_name} bought a product called ${!this.product_name},
which has the category ${!this.category} for ${!this.discounted_price}.
The product description is ${!this.about_product}
They gave a review: ${!this.review_content}
result_map: |
root.text_embedding = this
sql_insert:
driver: "clickhouse"
dsn: clickhouse://localhost:9000
table: sales
columns:
- txn_id
- product_id
- product_name
- category
- discounted_price
- actual_price
- dicount_percentage
- rating
- rating_count
- about_product
- user_id
- user_name
- review_title
- review_content
- img_link
- product_link
- text_embedding
args_mapping: |
root = [
this.txn_id,
this.product_id,
this.product_name,
this.category,
this.discounted_price,
this.actual_price,
this.dicount_percentage,
this.rating,
this.rating_count,
this.about_product,
this.user_id,
this.user_name,
this.review_title,
this.review_content,
this.img_link,
this.product_link,
this.text_embedding,
]Now the full pipeline is assembled, and we can run our example message through end to end with a single command:
API_KEY=xxx rpk connect run ./connect.yamlNow you've created a full streaming pipeline that uses the latest and greatest open-source models to generate recommendation emails to your customers. At the same time, all the processing happens locally and you have full control and sovereignty over your business' data.
Hope you enjoyed walking through the power and flexibility of Redpanda Connect. To watch the entire talk, check out all the Streamfest sessions on demand. All the code and the test data is available on GitHub. Stay connected with the latest in Redpanda Connect's GenAI capabilities and show us what you build in Redpanda Community on Slack!
Subscribe to our VIP (very important panda) mailing list to pounce on the latest blogs, surprise announcements, and community events!
Opt out anytime.

