




Five principles for governed autonomy with enterprise AI
How we turned opaque agent behavior into governed, provable workflows
Architectural overview of tiered storage architecture, including write and read path optimizations.









As part of Redpanda’s mission to make data streaming truly global, we needed a better way for our users to unify historical and real-time data at high speed and at low cost. The problem is that storing all that data is expensive, and not always as reliable as we’d like.
This is why we created tiered storage—a new and improved feature that lets us leverage the 99.995% guaranteed reliability of our tier-4 datacenter, resulting in less hassle for developers, simpler scaling for operators, and more efficient streaming for our end-users.
Here’s a quick overview of our tiered storage architecture, how we built it, and a peek into how it powers Redpanda’s tiered storage capabilities to give you the highest possible performance.
In short, tiered storage allows Redpanda to move large amounts of data between brokers and cloud object stores efficiently and cost-effectively—without any human intervention.
This new subsystem comes with a few advantages:
The bottom line is that tiered storage allows for infinite data retention with good performance at a low cost. For developers, it means ease of use and flexibility when designing applications. For operators, it allows cluster infrastructure to scale according to live load and provides additional tools for data recovery. Lower costs, less complexity, and more time for coffee.
Next, let’s dig into the key components of tiered storage and how we built it.
The tiered storage subsystem has four main components:
scheduler_service that uploads log segments and tiered storage metadata to the object storearchival_metadata_stm, which stores information about segments uploaded to the object store locally, in the Redpanda data directory (default /var/lib/redpanda/data)cache_service that temporarily stores data downloaded from the object storeremote_partition, which is a component responsible for downloading data from the object store and serving it to the clientsThe scheduler_service and archival_metadata_stm are the main components of the write path, which uploads data to the object store bucket. The cache_service and remote_partition are elements of the read path, which is used to download data from the object store to satisfy a client request.
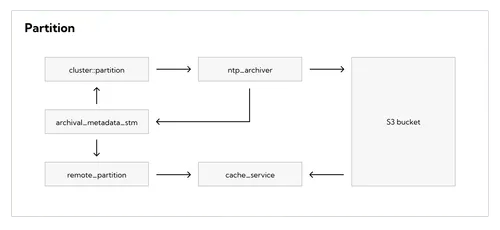
The scheduler_service component is responsible for scheduling uploads. It creates an ntp_archiver object for every partition and invokes individual archivers periodically in a fair manner to guarantee that all partitions are uploaded evenly. Note that uploads are always done by the partition leader. The archiver follows a naming scheme that defines where the log segments should go in the bucket. It is also responsible for maintaining the manifest, which is a JSON file that contains information about every uploaded log segment.
Object stores shard workloads based on an object name prefix, so if all log segments have the same prefix, they will hit the same storage server. This will lead to throttling and limit the upload throughput. To ensure good upload performance, Redpanda inserts a randomized prefix into every object. The prefix is computed using a xxHash hash function.
The archival subsystem uses a PID regulator to control the upload speed in order to prevent uploads from overwhelming the cluster. The regulator measures the size of the upload backlog (the total amount of data that needs to be uploaded to the object store) and changes the upload priority based on that. If the upload backlog is small, the priority of the upload process will be low and the occasional segment uploads won't interfere with any other activities in the cluster. However, if the backlog is large, the priority will be higher and the uploads will use more network bandwidth and CPU resources.

Redpanda maintains some metadata in the cloud so the data can be used without the cluster. For every topic, we maintain a manifest file that contains information about said topic (for instance, the retention duration, number of partitions, segment size etc). For every topic partition, we also maintain a separate partition manifest that has a list of all log segments uploaded to the cloud storage. This metadata and individual object names make the bucket content self-sufficient and portable. It can be used to discover and recreate the topics. The content of the bucket can also be accessed from different AWS regions.
When the archiver uploads a segment to the object store, it adds segment metadata (e.g. segment name, base and last offsets, timestamps, etc) to the partition manifest. It also adds this information to the archival_metadata_stm — the state machine that manages the archival metadata snapshot.
The partition leader handles the write path and manages archival state. For consistency, durability, and fault tolerance, this state needs to be replicated to the followers as well. Redpanda does this by sending state changes via configuration batches in the same raft log as the user data. This allows the followers to update their local snapshot. In case of a leadership transfer, this ensures that any replica that takes over as a leader has the latest state and can start uploading new data immediately.
The snapshot is stored within every replica of the partition. Every time the leader of the partition uploads the segment and the manifest, it adds a configuration batch with information about the uploaded segment to the raft log. This configuration batch gets replicated to the followers and then it gets added to the snapshot. Because of that, every replica of the partition "knows" the whereabouts of every log segment that was uploaded to the object store bucket. In other words, we're tracking the data stored inside the object store bucket using a Raft group. This is the same Raft group that is used to store and replicate the user data. This solution has some nice benefits. For example, when the replica is not a leader, it still has the up-to-date archival snapshot. When the leadership transfer happens, the new leader can start uploading new data based on a snapshot state without downloading the manifest from the object store.
Another benefit that snapshot enables is smarter data retention. Because the archival metadata is available locally, the partition can use it to figure out what part of the log is already uploaded and can be deleted locally. This constitutes a safety mechanism in Redpanda, which prevents retention policy from deleting log segments that were not uploaded to the object store yet.
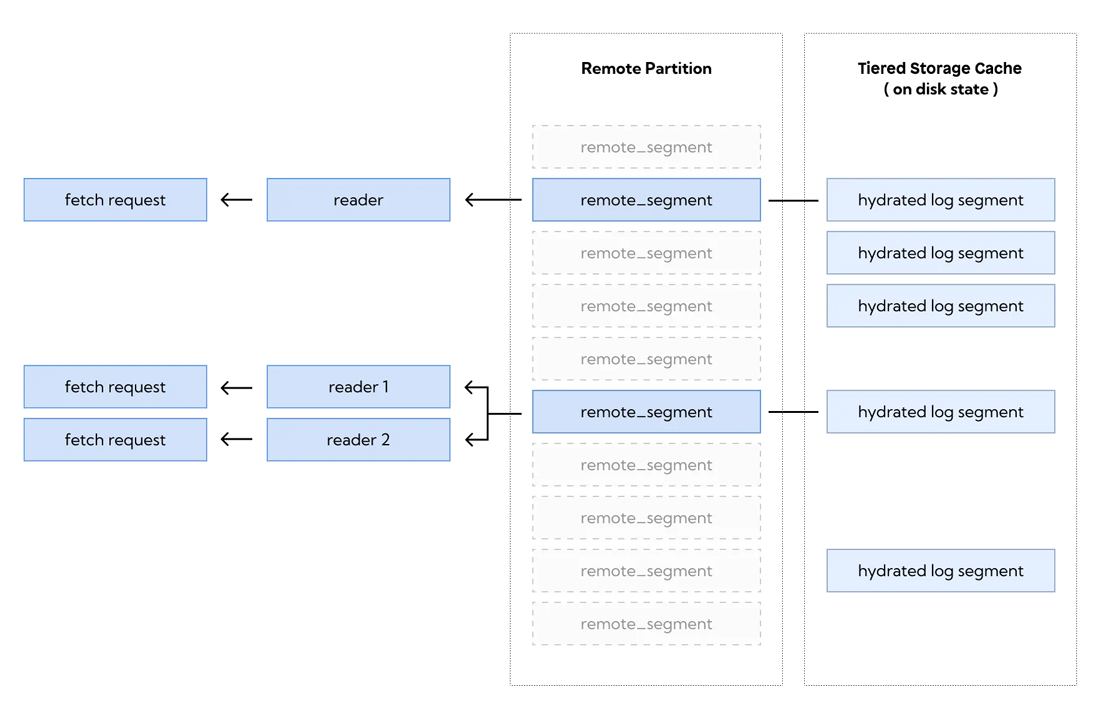
The remote_partition component is responsible for handling the reads from cloud storage. The component uses data from the archival metadata snapshot to locate every log segment in the object store bucket. It also knows the offset range that it can handle based on the snapshot data.
When an Apache Kafka® client sends a fetch request, Redpanda decides how the request should be served. It will be served using local data stored in the Raft log, if it is possible. However, if the data is not available locally, the data will be served using the remote_partition component. This means that even if the partition on the Redpanda node stores only recent data, the client will see that the offsets are available starting from offset zero.
When Redpanda is processing a fetch request, it checks if the offsets are available locally and, if this is the case, serves the local data back to the client. Alternatively, if the data is only available in cloud storage, it uses the remote_partition to retrieve the data. The remote_partition checks the archival snapshot to find a log segment that hosts the required offsets and copies that segment into the cache. Then, the log segment is scanned to get the record batches to the client. However, the remote_partition can't serve the fetch request using data in the cloud storage directly. First, it has to download the log segments to the local cache. The cache is configured to store only a certain number of log segments simultaneously and evicts unused segments if there is not enough space left.
Internally, the remote_partition object stores a collection of lightweight objects that represent uploaded segments. When the segment is accessed, this lightweight representation is used to create a remote_segment. The remote_segment deals with a single log segment in the cloud. It can download the segment to the local storage, and can be used to create reader objects, which are used to serve fetch requests. Readers can fetch data from the log segment and materialize record batches. Think of them as something loosely similar to database cursors that can scan data in one direction. The remote_segment also maintains a compressed in-memory index, which is used to translate Redpanda offsets to offsets in the file.
The remote_partition also hosts the reader cache. This cache stores unused readers that can be reused by fetch requests if the offset range requested by the fetch request matches one of the readers. Also, the remote_partition can evict unused remote_segment instances by transitioning them to the offloaded state, in which they're not consuming system resources.
The latency profile might be different between the tiered storage reads and normal reads: tiered storage needs to start retrieving data from the object store to the cache in order to be able to serve fetch requests. Also, tiered storage doesn't use record batch cache. Because of that, it's more suitable for batch workloads.
To develop the tiered storage subsystem, we started with the write path—which came with a few challenges of its own.
For this, we developed our own S3 client using Seastar. Although Seastar didn't let us use the existing object store client efficiently, and the framework didn't have an HTTP client to access the object store API. So, we used Seastar to develop our own HTTP client.
scheduler_serviceThe scheduler_service, well, schedules individual uploads from different partitions. To make this work, we had to address two problems:
Firstly, the scheduler needs to provide a fairness guarantee in case one of the partitions doesn't receive enough upload bandwidth and lags behind. This could cause a disk space leak by preventing the retention policy from doing its job.
Secondly, every replica of the partition might have different segment alignment, and the segments could begin and end on different offsets—despite holding the same data. Because of this, it’s possible that only part of the segment needs to be uploaded after the leadership transfer. The newly-elected leader must be able to see what offset range is already uploaded for the partition and compute a starting point for the next upload inside one of the segments.
In a nutshell, topic recovery allows Redpanda to restore a topic using data from the object store.
The problem is that you can’t simply download the data. Instead, for Redpanda to use that data we needed to create a proper log and bootstrap a Raft group. There’s a lot of bookkeeping used to manage Raft state outside the log. For example:
After battling all the above, we rolled up our sleeves again and moved onto the next set of challenges: developing the components in the read path.
cache_serviceThe cache_service is tricky since it’s global (per node), and Seastar likes everything to be shared per CPU. But, if we shard the cache then one hot partition could theoretically cause many downloads from the object store, with other shards underused.
This wouldn’t be a problem with just one global cache_service, but it does mean considering other issues, like cache eviction, which has to be done globally and requires coordination between the shards.
archival_metadata_stmThe archival_metadata_stm is the state machine that manages the archival metadata snapshot. The partition leader handles the write path and manages archival state. For consistency, durability, and fault tolerance, this state needs to be replicated to the followers as well.
Redpanda achieves this by sending state changes via configuration batches in the same Raft log as the user data. This allows the followers to update their local snapshot. In case of a leadership transfer, any replica that takes over as a leader has the latest state and can start uploading new data immediately. The snapshot is stored within every replica of the partition. Every time the leader of the partition uploads the segment and the manifest (a JSON file that contains information about every uploaded log segment), it adds a configuration batch with information about the uploaded segment to the Raft log. This configuration batch gets replicated to the followers and is then added to the snapshot.
A great benefit of snapshot is smarter data retention. Since the archival metadata is available locally, the partition can use it to figure out what part of the log is already uploaded and can be deleted locally. This is a safety mechanism in Redpanda that prevents the retention policy from deleting log segments that haven’t been uploaded to the object store yet.
remote_partitionThe remote_partition has to track all uploaded segments at once. To serve fetch requests, it should be able to locate individual segments, download them to the cache directory, and create readers.
The problem is that the bucket may contain more data than the Redpanda node can handle. So, the remote_partition can't just create a remote_segment object for every log segment that it tracks. Instead, it creates the remote_segment instances on demand and destroys them when they're idle long enough. As a result, the remote_segment has to be a complex state machine that has a bit of internal state for every uploaded segment.
In the end, we can safely say that creating tiered storage certainly proved tricky, but the whole system came together nicely—if we may say so ourselves.
This tiered storage feature already packs a punch with infinite data retention, better performance, and fewer headaches for developers designing applications. But this is just the beginning.
Here’s a peek at the enhancements we have planned for tiered storage in Redpanda:
Excited yet? To learn more about tiered storage and how to use it, check our documentation, or join our Slack community if you have specific questions, feedback, or ideas for enhancements.
How we turned opaque agent behavior into governed, provable workflows

How we revamped our Redleader agent to enable governed, multi-agent AI for the enterprise

How a governed data control plane ensures trust and accountability
Subscribe to our VIP (very important panda) mailing list to pounce on the latest blogs, surprise announcements, and community events!
Opt out anytime.