





Real-time Change Data Capture with Redpanda Connect and MySQL
Stream every insert, update, and delete from your database the moment it happens
What is change data capture (CDC), and what are the common methods for implementing CDC?








CDC can significantly upgrade the performance of critical data-related systems in your organization. It can help prevent inconsistencies between data in different data stores, maintain a log of changes to critical data for auditing purposes, stream data into data warehouses in real-time, and offer a more flexible and controllable change detection method for database replication.
Common methods for implementing CDC include using the timestamp of a database entry (Date Column Differences) to determine if it has changed compared to an earlier state, or running table diffs or deltas on the source system (Table Differences). The choice of method should depend on how your systems are set up and your organizational constraints.
The Date Column Differences method can be implemented in the application itself, with no external tools required. It's robust enough to handle either the source or target systems being temporarily down. However, it requires additional columns to be added to the source system, adds load due to constant querying for changed data, and doesn't capture deletions by default. Also, only the state of the data at the time of a check by the target system is captured, omitting any intermediate changes.
Traditional data capture loads data from the source database to the target database in large batches at fixed intervals, often leading to high latency and inefficiency due to repeatedly capturing the same data. CDC, on the other hand, is event-driven and continuously monitors data for any changes, allowing data capture to happen in real-time or near-real time, reducing latency. It also records every intermediate change and doesn't add a considerable load to the source system.
Businesses today rely heavily on vast volumes of constantly changing data to make critical decisions. For some systems, like self-driving vehicles, real-time feedback based on data is fundamental to their existence. Every part of the data pipeline must be streamlined for these businesses and systems to function as required.
Data is often processed or stored in a different system than the one it's collected in. That requires fast, efficient, and reliable loading or capturing of data from one system to another. In addition, data is often collected from multiple systems and combined for meaningful insights.
Change data capture, or CDC, is a software design pattern or technique that identifies and tracks data changes in a system to capture that changed data in another system. These systems are usually referred to as source and target; data flows from the source system to the target system.
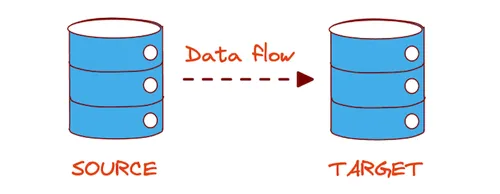
This article explains why you need CDC and introduces the most common CDC methods currently used.
Traditional data capture loads data from the source database to the target database in large batches at fixed intervals. This technique doesn't usually take changed data into account and runs the same way, irrespective of the amount or frequency of the changed data. This method suffers from high latency and significant inefficiency due to repeatedly capturing the same data. This method also fails to capture intermediate changes to the data. For example, if a value changes from 2 to 4 to 6 between captures, only the change from 2 to 6 would be captured. Additionally, as the batches of data are quite large, the processes to capture them add considerable load to the source system and slow down other business-critical processes.
Unlike the batch method, CDC responds to events that lead to changes in the data, meaning it's event-driven. The data is continuously monitored, and any changes are identified for capture. That improves the previous method by allowing data capture to happen in real-time or near-real time, meaning there is no latency. The data captured by CDC is more detailed than batch processing, and every intermediate change is recorded. Also, as CDC deals with smaller batches, it doesn't add a considerable load to the source system.
CDC can significantly upgrade the performance of critical data-related systems in your organization. In other words, CDC can help improve core business metrics and increase profits.
It's worth noting that Redpanda seamlessly integrates with CDC technologies, allowing you to improve your data capture processes. It converts identified data in a source system into a time-ordered event stream that target services and applications, such as a mobile app or data backup service, can consume. It can be easily deployed using Redpanda Cloud on fully managed clusters to give you the most stable experience.
Below are some of the main use cases for the CDC.
Microservices-based applications often use multiple data sources, such as a relational database, a message queue, or a streaming platform like Kafka. In such a setup, you may encounter inconsistencies between the data in different data stores, known as dual writes. CDC can prevent dual-writes by replicating changes on one system to the other systems and reconciling data across multiple systems. For example, instead of writing data to an application database and a backup database (risking dual-write issues), the data is only written to the application database, from which a CDC tool captures it, and the data is copied into the backup database separately.
Businesses must maintain a log of changes to critical data for auditing purposes to comply with data regulations. If an unexpected or unwanted change occurs, custom events must be written, alerts must be published, and stakeholders must be notified to take immediate action. Failure to do so can result in significant fines. CDC is useful for these logs, as it captures every change to the critical data.
CDC allows you to stream data into data warehouses in real-time, reducing or eliminating the need for batch windows and bulk load updates. So, you can use the most current data to populate business intelligence dashboards and provide all stakeholders with up-to-date insights for making more informed decisions.
Database replication is essential for running scalable, available, reliable, and accurate databases. It relies on detecting changes in the main database and copying them to replicas for downstream consumption. Most transactional databases use native replication backed by redo logs to implement replication. However, CDC offers a more flexible and controllable change detection method for database replication.
The most common methods for implementing CDC are highlighted in the following table:
While most large organizations that use popular tools like SQL and PostgreSQL prefer log-based CDC because of its resilience and scalability, some methods work better in particular situations than others. The exact method you choose should depend on how your systems are set up and your organizational constraints. For example, if you have a highly specialized workflow and require a log of all data changes, using the trigger-based method might be best for your use case.
In the next section, you'll learn more about the different CDC methods and their advantages and drawbacks.
You can use the timestamp of a database entry to determine if it has changed compared to an earlier state that was stored in the target system. For this, you need a column in the database table to record the timestamp of the last change to any entry (a new last_modified column can be added to the table if something like it doesn't already exist). This method requires the target system to check for and pull changed data from the source system at regular intervals.
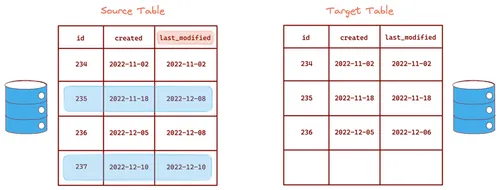
The main advantage of the date column differences method is that it can be implemented in the application itself, with no external tools required. Since it's a pull-based method, it's robust enough to handle either the source or target systems being temporarily down. The target will keep trying to pull data from the source until it succeeds.
However, there are some significant disadvantages. Additional columns (which the application might not require) have to be added to the source system. The source system will also have to deal with additional load due to constant querying for changed data. Further, deletions are not captured by default. Custom logic must be added to capture deletions, adding to the complexity. Moreover, only the state of the data at the time of a check by the target system is captured. Intermediate changes, meaning any changes made to the data in between checks, are omitted.
This method is similar to the date column differences method because it's also pull-based (the target system checks the source system for changes regularly and then pulls that data in). However, instead of querying for changed data in a particular table column, the target system identifies changes by running table diffs or deltas on the source system.
Tablediff utilities (like tablediff for SQL Server) can be used to create snapshots of the source system data at various points in time and compare them to identify data changes. Additional scripts can then be applied to transfer the changes to the target system.
The tablediff utility's internal workings depend mainly on the type of database used. A common method involves comparing a combination of the primary key and the checksum of a row's values in one snapshot with that in the previous snapshot.
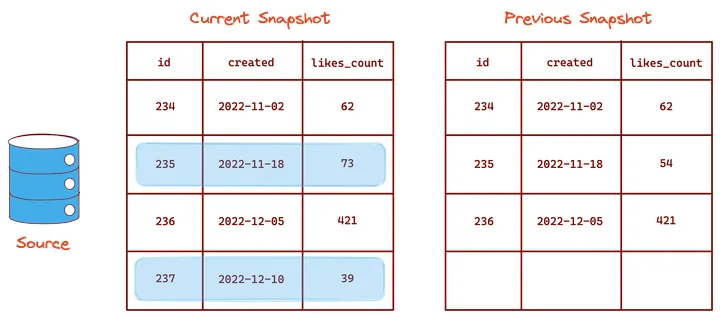
Compared to the date column differences method, one advantage of this method is that the database schema does not have to be modified. Many platforms support some kind of tablediff utility, and data changes can be identified using natively supported scripts. Another big benefit is that tablediff utilities can natively track all data changes (including deletions).
On the flip side, the source system will have to bear more load due to the repeated execution of tablediff utilities. Additional storage is also required to store snapshots. As with the date column differences method, intermediate changes are also missed.
Database triggers are another way to implement CDC. Triggers can be created manually for every INSERT, UPDATE, and DELETE statement in the source system. A trigger is then fired upon every database transaction, and the corresponding Data Manipulation Language (DML) statement is captured in a time-ordered manner in another table (usually called a shadow table) to create a changelog. Data from this changelog is then loaded into the target system at regular intervals.
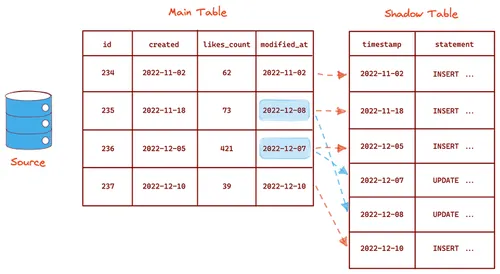
This method has some advantages over the previous two methods. Triggers are supported natively in most databases, and their implementation is relatively simple. Further, the shadow tables create a clear log of all database transactions, which is easy to parse and replicate.
However, its disadvantages are also significant. Manually creating and managing triggers can be extremely effort-consuming for large systems. Custom triggers have to be created for every kind of transaction. They must also be maintained regularly and updated if any backend code is modified. More importantly, relying on triggers can be quite error-prone. If there is any issue with a trigger, there is a risk that the entire transaction will be rolled back. That can lead to the loss of critical data.
This method is also relatively inefficient. Every time data is added, updated, or deleted; it has to be written to multiple tables, reducing performance. Additionally, the shadow table needs to be queried to capture data regularly, adding to the load on the source system.
Log-based CDC is an approach that's been gaining traction over the last few years. Almost all database systems generate transaction logs by default to restore the system in the event of a crash. Log-based CDC works by parsing the native transaction logs of the source system and identifying data that has been changed.
These database systems have a built-in mechanism for parsing logs and replicating the data changes in another system. However, this is mainly limited to replicating data. To perform any other action, like processing the data, third-party CDC tools like Debezium are required.
Such tools parse the logs of the source system and convert the changed data into events that can be reliably transported to other systems using event-streaming services like Redpanda. This event stream is then pushed to the target system to load the changed data.
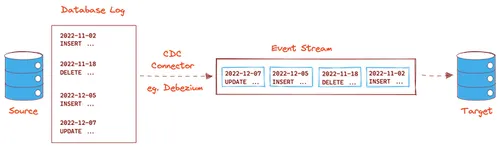
Most businesses prefer log-based CDC for their data pipelines. While other methods are used in particular circumstances, log-based CDC tools offer better reliability, scalability (due to their decoupled nature and interoperability with various systems), and community support.
Log-based CDC offers significant advantages over other CDC methods. Since data changes are parsed from logs, no additional load is put on the source system to query data. No schemas or structures need to be modified in the source system. Deletions can also be tracked without any extra configuration. Further, this method generates a detailed log of all changes, so no data changes are missed.
Log-based CDC tools can connect the source and target systems so that they become decoupled; the source system does not need to care about the data format used by the target system and vice versa. They accept or output data in a standardized format and can thus be connected to various database systems through compatible data connectors. That makes these systems highly scalable and robust.
While the advantages of log-based CDC are significant, there are also a few disadvantages. Database logs are complex and vary greatly depending on the type of database used. Log formats are also not well-documented, so creating and maintaining log parsers for multiple database types can be cumbersome. However, this can be overcome by choosing third-party log parsers maintained and supported by a trusted organization or an active community. A high log level might also have to be set for the log parser to get the correct information. That can add some load to the source system and increase the requirement for storage for the larger log files.
Overall, the advantages of log-based CDC far outweigh the disadvantages for most larger-scale (enterprise or large startup) use cases. Log-based CDC is the best choice unless your use case is highly specialized.
In this article, you learned about the CDC technique to identify and track data changes and the most common methods to implement them. In most cases, log-based CDC is the best strategy, as it does not share the other methods' disadvantages. Using log-based CDC, you can set up efficient, robust, and accurate data pipelines to convert data into actionable insights that inform critical decisions in your organization.
To explore log-based CDC further, you can take Redpanda's free Community edition for a test drive. Check out our documentation to understand the nuts and bolts of how the platform works, or read our blogs to see the plethora of ways to integrate with Redpanda. To ask our Solution Architects and Core Engineers questions and interact with other Redpanda users, join the Redpanda Community on Slack.
Stream every insert, update, and delete from your database the moment it happens

Your lakehouse mirrors the database, instantly.

What is it, why enterprises need it, and how to evaluate one
Subscribe to our VIP (very important panda) mailing list to pounce on the latest blogs, surprise announcements, and community events!
Opt out anytime.