




Drag, drop, done: a visual composer for Redpanda Connect
Boxes and arrows for people who move billions of events a day. No per-row invoice required.

The latest release brings in-broker data transforms (beta), plus enhancements to enterprise security, compliance, reliability, and efficiencies that lower TCO.








A new year, a new Redpanda! Right before the New Year’s ball dropped, we rolled out the latest major version of Redpanda, 23.3. This release includes Redpanda Data Transforms in beta, significant boosts to enterprise security and compliance (OIDC/SSO support, audit logging), reliability (whole cluster restore, recovery mode, fast commission/decommission), and lower TCO (improved compaction).
Read on!
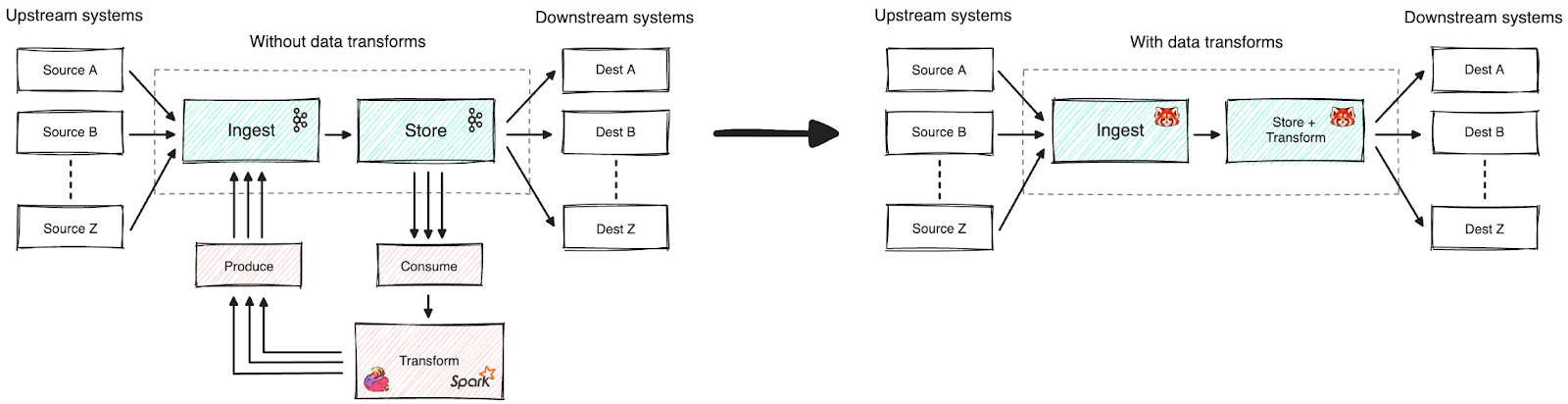
At Redpanda, we’re relentlessly simplifying the developer workflows that surround streaming data, with integrated features like Tiered Storage and Schema Registry, and flexible deployment options like BYOC. To keep things simple, we invented Wasm-powered data transformations that run within Redpanda brokers.
Today, we’re happy to announce that Redpanda Data Transforms is now available in public beta for self-hosted deployments!
Imagine less data “ping pong,” more cost-efficient architectures, improved data quality for downstream consumers, and more reliable pipelines. That’s the “why” behind Redpanda Data Transforms. With Data Transforms, you can run custom code on the core local to the data, enabling one-shot-style computation on the record batches already flowing into your topics, including inline transformations such as filtering, scrubbing, transcoding, or enriching.
Whether it’s redacting PII, converting JSON data into the Apache Avro™ format, or running arbitrary code — even streaming ML/AI inference on individual events! — transformations are now as simple as a few lines of Golang and an rpk command to deploy them. Despite simplified packaging, however, Data Transforms are powerful enough to use existing libraries like goroutines (and soon other languages, like Rust) to do more complex tasks.
And the best news? All of this works while running reliably across tens of thousands of partitions in parallel and maintaining GB/s throughput levels.
Redpanda Data Transforms can now be used for non-production self-hosted Redpanda deployments, and will be available in Redpanda Cloud soon. For more information about the public beta of Data Transforms, check out our documentation.
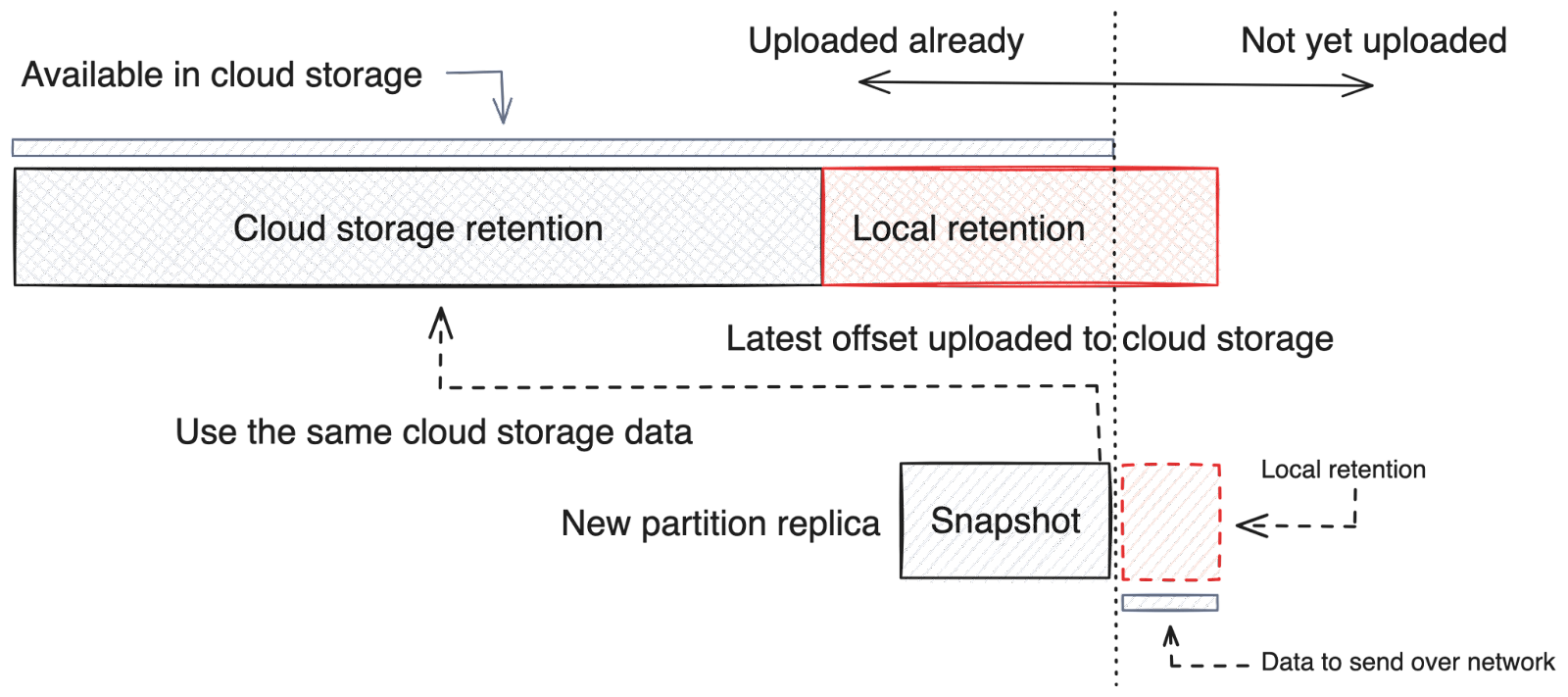
We’re also working under the hood to simplify how data is moved within Redpanda clusters as efficiently as possible. For clusters using Tiered Storage, Redpanda now offers much faster commissioning and decommissioning of brokers. Aside from faster scaling up and down, this approach also reduces cross-AZ data transfer costs by limiting the amount of data replication between brokers during these operations.
We do this by short-circuiting the Raft replication that occurs when brokers enter or leave a cluster, such as during an upscale, downscale, or repair after an instance failure. This optimization is made possible by safely and automatically relying on Tiered Storage for reads of offsets older than a configurable threshold, as Redpanda moves partition replicas to and from these nodes. This allows clusters to be repaired to their full capacity much more quickly, as well as scale more seamlessly to support variable workloads more cost effectively, all while maintaining the same data availability and data safety guarantees.
Learn more about fast commission/decommission in our documentation.
In Redpanda 23.3, topic compaction follows a new algorithm that, in some cases, results in orders of magnitude greater efficiency. Compaction now uses a sliding window approach, and boundaries are no longer created between segments or Raft leader election terms.
Compacted data is also re-uploaded to Tiered Storage as further rounds of compaction occur, continually increasing the fidelity of compaction for as long as possible. This improves the efficiency of compaction in both storage tiers.
The result: lower local disk and cloud storage costs, and dramatically more efficient replay of heavily compacted topics. Read more in our documentation.
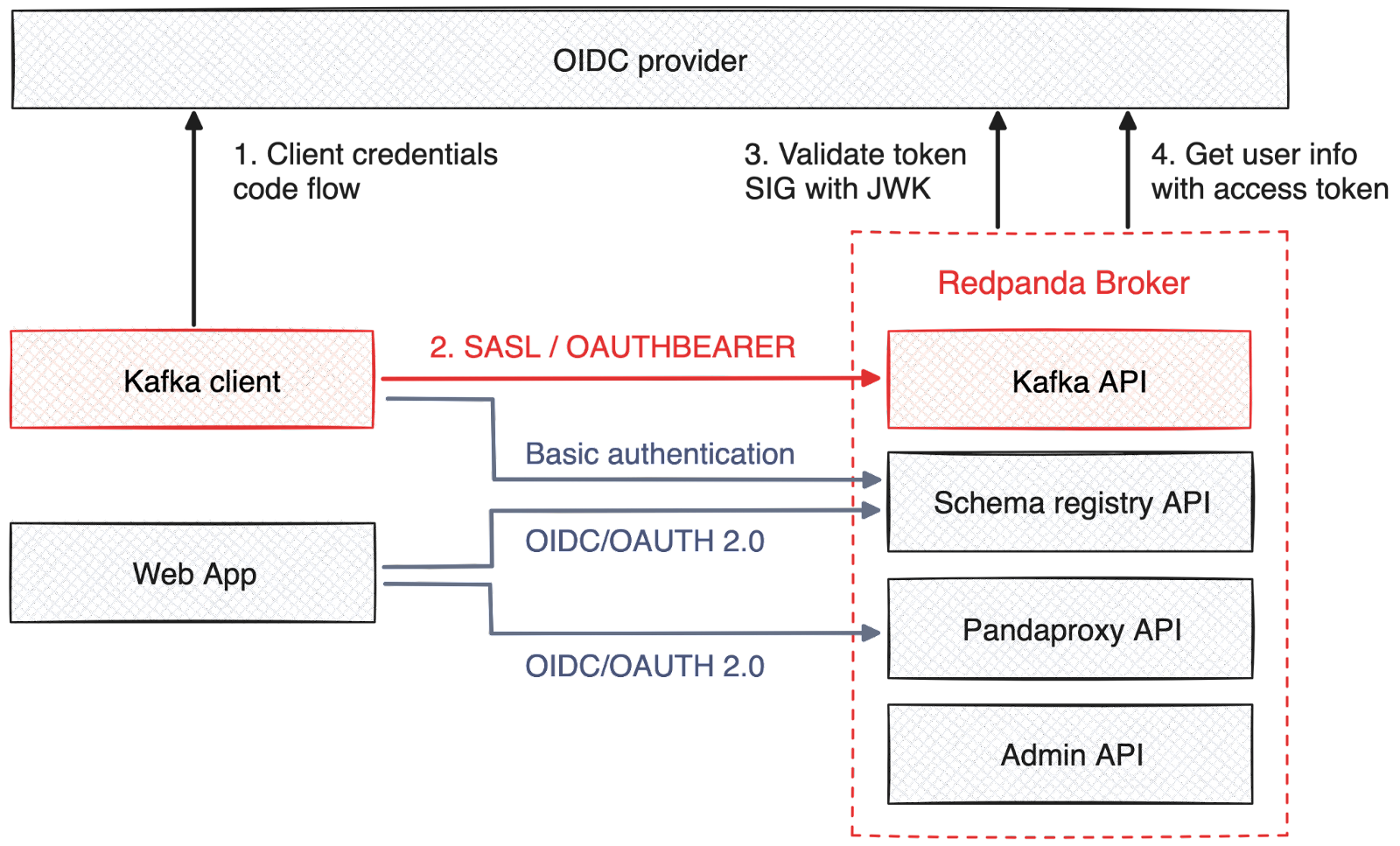
Authentication is a critical aspect of any data platform, especially when dealing with sensitive or confidential information. OpenID Connect (OIDC) is a popular authentication protocol with more than one billion OpenID-enabled accounts in the world today and support from all major identity provider (IdP) vendors, such as Okta, Microsoft Azure AD and AD FS, Google Identity, and Keycloak.
Unlike legacy CLI-based approaches to SSO like Kerberos, OIDC offers a more modern HTTP API-based approach suitable for both human and machine users, making it an ideal choice for contemporary cloud-native applications. For industries with strict compliance requirements, OIDC allows for detailed audit trails, simplifying regulatory compliance.
Now, Redpanda self-hosted deployments support OIDC for single sign-on (SSO) authentication, allowing users to interact with all platform features using a single set of credentials via their IdP of choice. This includes all Redpanda APIs such as the Apache Kafka® API, Schema Registry, and HTTP Proxy (pandaproxy). Combined with existing OIDC support in Redpanda Console, this means that for the first time, all Redpanda users can be maintained entirely within your organization’s corporate IdP, and access can be granted and revoked using your existing account onboarding/offboarding process via that IdP.
The result: more secure, streamlined, and flexible user management that integrates easily with your organization’s broader identity and access management infrastructure. (Running in Redpanda Cloud? Expect OIDC support in Dedicated and BYOC environments very soon). Learn more in our documentation.
Auditing of streaming data for forensic analysis and to help meet compliance requirements, using open standards — check!
Regulated industries such as finance, healthcare, and the public sector often have stringent requirements for audit logging as part of their compliance programs. Good news for regulated industries: Redpanda deployments now support auditing of Kafka API, Schema Registry, and Redpanda Admin API operations. This means you can persistently store auditing events in a Redpanda topic in an append-only fashion and guarantee audit retention for the requested time period, even against the actions of Redpanda administrators.
At Redpanda, we have a bias for open and commonly-adopted industry standards because they help reduce maintenance overhead, improve interoperability, and help enable stronger partnerships. That’s why Redpanda audit messages follow the Open Cybersecurity Schema standard, to promote compatibility with existing industry-leading tools and vendors such as Splunk, Sumo Logic, and AWS. Learn more in our documentation.

In case of complete disaster, you can now create a new cluster of nodes, point at your Tiered Storage bucket for business continuity, and off you go!

Disaster recovery solutions that leverage an active-active, continuous replication architecture (such as Kafka’s MirrorMaker 2) are effective, but can also become costly due to the 2x infrastructure investment and operating costs they require.
From the beginning, we envisioned a better way: leveraging Redpanda Tiered Storage to provide a more cost-efficient DR solution that simplifies the recovery of entire clusters within reasonable RPO/RTO parameters. This approach offers a simpler solution that makes a good cost tradeoff against existing active-active solutions by using data already resident in a regionally (or globally) resilient storage system such as AWS S3.
Now, on clusters with Tiered Storage enabled, because we automatically backup cluster metadata to cloud storage behind the scenes, you can perform a whole cluster restore to recover all cluster data and metadata from a failed cluster to a new cluster with a single command, helping return your applications to the latest functional state as quickly as possible.
Redpanda even aligns consumer offsets with the last recovered offset after failure to make recovery more seamless for Consumers. And because it relies on reading data from Tiered Storage, it all happens with no data hydration delays, helping to achieve lower RTO requirements. Learn more in our documentation.
Accidental misconfiguration by cluster admins or faulty application logic can put a significant load on brokers and in some cases cause them to be overwhelmed, leading to resource exhaustion or other fatal conditions that prevent smooth operation.
That’s why we have added recovery mode, which empowers admins to safely make cluster config changes and perform other administrative actions (e.g., deactivating or deleting problematic partitions & topics, managing users/ACLs, deleting consumer groups, deleting stuck transactions, deleting data transforms, etc.) to repair a nonfunctional cluster, while temporarily disabling data access to clients while repairs are performed.
Now you can repair and recover your clusters in peace! Learn more in our documentation.
All of these winter updates are available today for self-hosted deployments, so request a POC of Redpanda Enterprise, or grab the free Community Edition from our Redpanda GitHub repo. And, stay tuned for our upcoming Redpanda Cloud release next month!
To learn all about what’s new in Redpanda 23.3 (and how to use it), join our live launch stream for a data transforms demo, customer fireside chat, AMA session, and tech workshop.
By the way, did you know that Redpanda is proven to reduce your streaming data costs by up to 6x? To find out how much we can help you save on your cloud bill, join the Redpanda Community on Slack, or get in touch with our team.
Boxes and arrows for people who move billions of events a day. No per-row invoice required.

Solving a Kafka problem to balance batching efficiency against latency and cost
Subscribe to our VIP (very important panda) mailing list to pounce on the latest blogs, surprise announcements, and community events!
Opt out anytime.
