




Stream Oracle changes to ClickHouse in real time with Redpanda Connect
A hands-on walkthrough of our new Oracle CDC connector
Sync your BigQuery data in real time to get your data instantly ready for action









First, use Redpanda Connect to connect and consume data from Pub/Sub. Then, run continuous queries in BigQuery, which requires a slot reservation with a CONTINUOUS assignment type. Next, navigate to the Pub/Sub topic page and create a topic. Design the query as an export to Pub/Sub in BigQuery. Finally, prepare your Redpanda Cluster, create a topic and a service user, set up a configuration file for Redpanda Connect, and start Redpanda Connect.
You can sign up for Redpanda Cloud and browse the following blogs to learn more: BigQuery continuous queries, Redpanda to BigQuery for analytics. If you have questions, you can ask them in the Redpanda Community on Slack.
In this integration, BigQuery continuous queries use Pub/Sub Export as the option and Redpanda’s Pub/Sub source connector can stream data in real time as it arrives in BigQuery tables. BigQuery continuous query results can be streamed in real time to Redpanda, making it easy to crunch the data instantly and integrate with downstream applications for a more comprehensive view.
BigQuery continuous queries operate non-stop, processing SQL statements, and allow companies to analyze, transform, and replicate data in real time as new events arrive in BigQuery. They use familiar SQL syntax to define the data analysis and can handle large volumes of data efficiently. Companies can synchronize their data immediately as it reaches BigQuery with Redpanda and then push that data to the downstream applications and tools they need it in.
The integration of BigQuery continuous queries with Redpanda opens up a range of real-time use cases, ensuring the latest data is always available to businesses for action. It allows customers to maximize the impact of using BigQuery for insights. The ability to query data from BigQuery in near real-time combined with Redpanda's streaming capabilities provides Reverse ETL, closing the data loop.
Many organizations struggle to move data from their data warehouses in real time to downstream platforms, which benefit from the freshest and latest data. Traditional methods involve complex batch exports or change data capture mechanisms, leading to latency and operational overhead. To solve this problem, Google Cloud Introduced BigQuery continuous queries which enable you to analyze incoming data in real time.
With continuous queries, Google introduces the ability to extract real time data from Google Cloud BigQuery. The data can be written back out to Google Pub/Sub and then to Apache Kafka®, enabling the Reverse ETL pattern and allowing users to get real-time insights into their BigQuery data. With Redpanda—a Kafka-compatible streaming data platform— you can ingest fresh data to downstream systems so your business systems can consume the latest changes in real time.
BigQuery continuous queries operate non-stop, processing SQL statements, allowing companies to analyze, transform, and replicate data in real time as new events arrive in BigQuery. They use familiar SQL syntax to define the data analysis and can handle large volumes of data efficiently.
Companies can synchronize their data immediately as it reaches BigQuery with Redpanda and then push that data to the downstream applications and tools they need it in. This streamlined process unlocks real-time use cases powered by data in BigQuery, such as immediate personalization, anomaly detection, real-time analytics, and Reverse ETL.
This integration opens up a range of real-time use cases, ensuring the latest data is always available to businesses for action. In this integration, continuous queries uses Pub/Sub Export as the option and Redpanda’s Pub/Sub source connector can stream data in real time as it arrives in BigQuery tables.
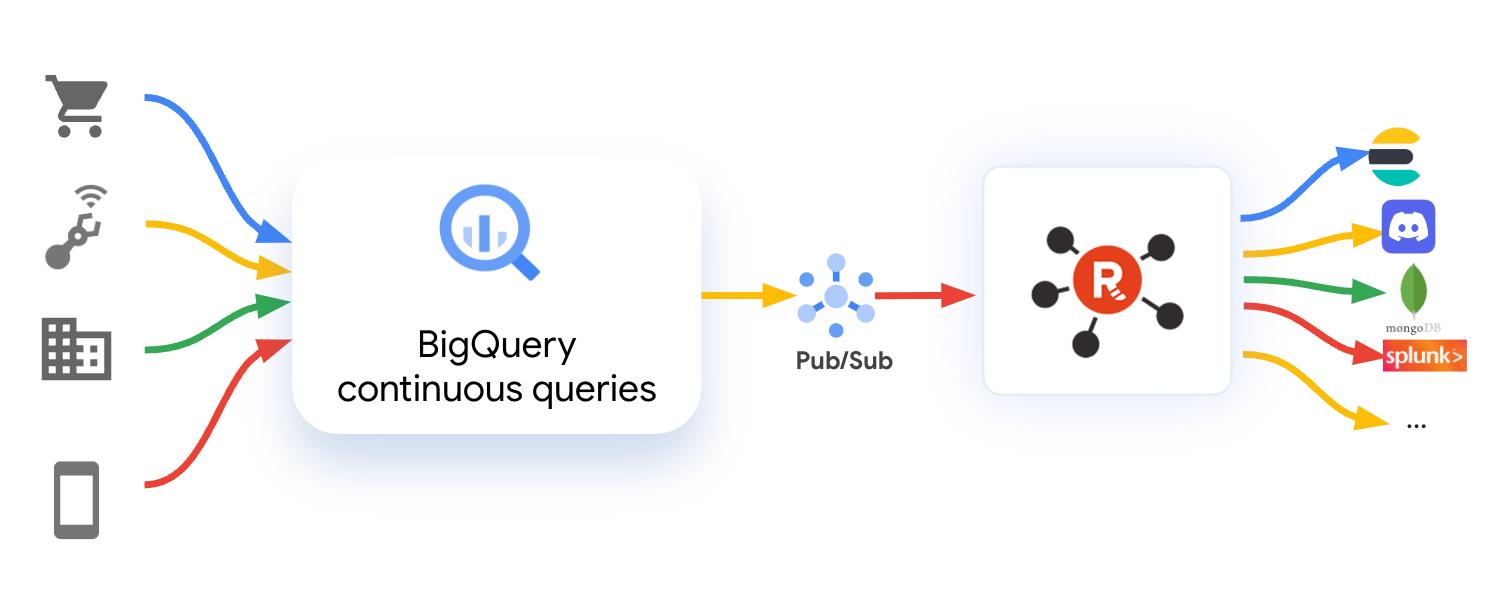
BigQuery continuous query results can be streamed in real time to Redpanda making it easy to crunch the data instantly and integrate with downstream applications for a more comprehensive view.
At the time of this blog, the Continuous queries feature is in preview and subjected to the "Pre-GA Offerings Terms." To enroll in the continuous queries preview, fill out the request form.
1) Redpanda Connect would use a service account to connect and consume data from Pub/Sub. You can configure a single service account for running continuous queries and consuming data from Pub/Sub by assigning relevant permissions to the user. To configure the service account, check this list of service account permissions. Make sure you create a JSON key to configure the connection in Redpanda in the later step.
2) To run continuous queries, BigQuery requires a slot reservation with a CONTINUOUS assignment type. You can follow the official guide on how to create a reservation if you’re unsure.
3) Navigate to the Pub/Sub topic page and click on Create Topic. Then provide a name (say ‘continuous_query_topic’) and leave the Add a default subscription as checked to create a subscription.
4) Navigate to BigQuery service page and design the query as an export to Pub/Sub.
In the More Settings option as shown below, select the query mode as Continuous query, and in the Query settings select the service account created above to run the query. You can also choose the timeout required if any.
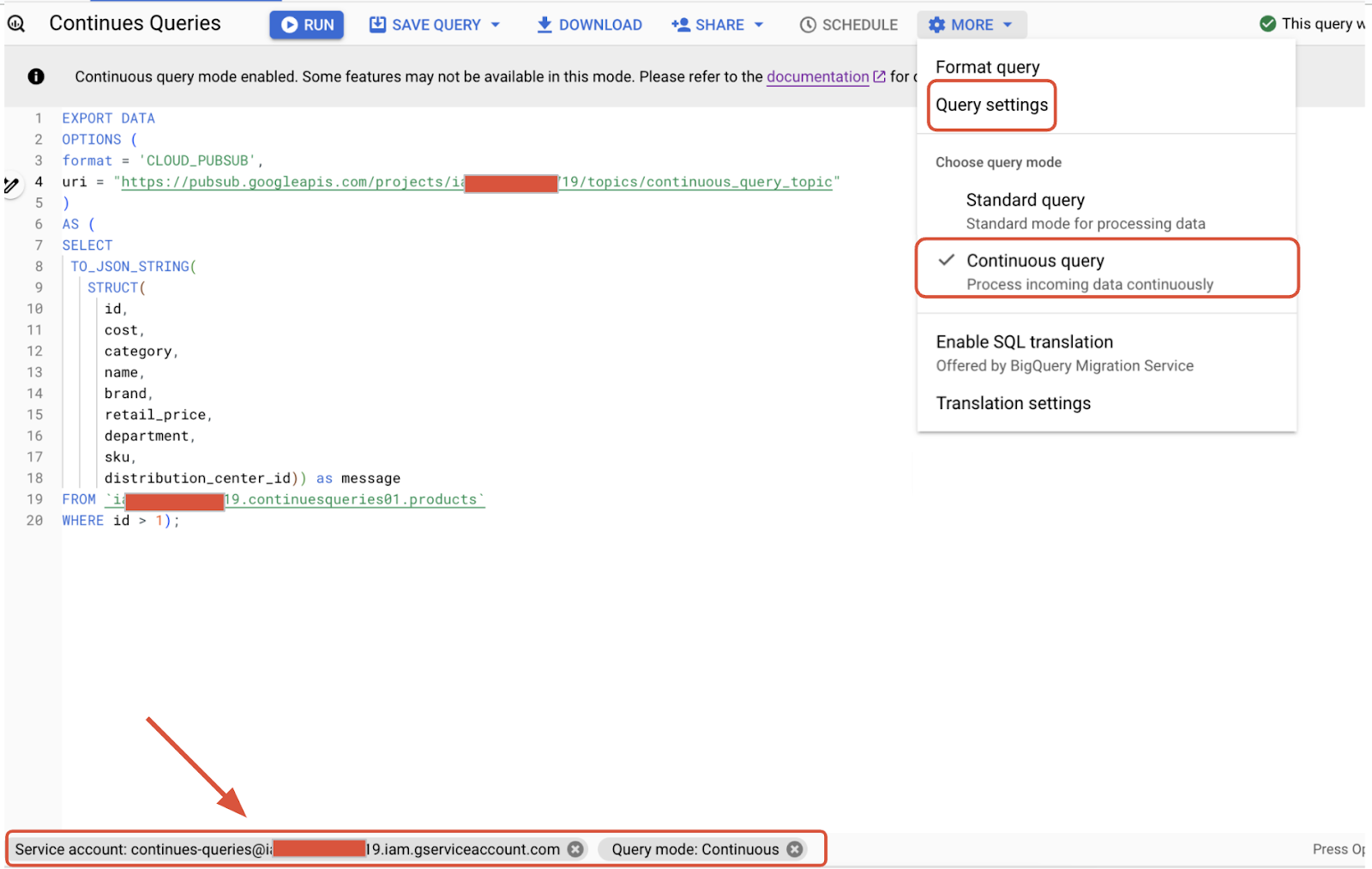
Before we execute the query, make sure the below steps are done to ensure data continuously generated can be captured by the Redpanda Pub/Sub connector.
5) It’s time to prepare your Redpanda Cluster. Use your Redpanda Cloud cluster or, if you don’t have one yet, sign up for Redpanda Cloud Serverless to get started for free. Now create a topic and a service user that can write to that topic.
6) Set up a configuration file for Redpanda Connect. Create an empty file named config.yaml and use the following configuration. The config links the Pub/Sub subscription with Redpanda. Replace the config fields with the Pub/Sub and Redpanda Cloud setup from previous steps:
Go ahead and start Redpanda Connect. Use the JSON key from step 1.
7) Once the Pub/Sub connector starts up, you can run the continuous query as above and start seeing the messages arriving in the topic bq_data.
8) Once the data arrives in the topic, you can connect output connectors and push the events into downstream applications as your use case demands.
The ability to query data from BigQuery in near real-time combined with Redpanda's streaming capabilities allows customers to maximize the impact of using BigQuery for insights. If you’re already using Redpanda and BigQuery in an ETL workflow, the additional capabilities provide Reverse ETL, closing the data loop.
To try it for yourself, sign up for Redpanda Cloud and browse the following blogs to learn more: BigQuery continuous queries, Redpanda to BigQuery for analytics. If you have questions, drop them into the Redpanda Community on Slack.
Subscribe to our VIP (very important panda) mailing list to pounce on the latest blogs, surprise announcements, and community events!
Opt out anytime.

