




Bridge Queries in Redpanda SQL
Have your real-time cake and eat your analytics too
Cloud data transfer can be expensive. Here’s how to work out your monthly cloud bill—and how Redpanda can help lower it









To calculate data transfer costs for a multi-AZ deployment, consider three data flows: Producer ingress, Consumer egress, and Intra-cluster replication. For every 1GB of data produced or consumed, 2/3 of the data will cross into another AZ. For every 1GB of data produced, 2GB of replication data will cross into another AZ. Multiply these values by the cloud providers' AZ data transfer cost to get the total cost.
Single-AZ deployments run all Redpanda brokers within a single Availability Zone (AZ), which avoids inter-AZ data transfer costs but risks an outage if the AZ goes down. Multi-AZ deployments spread brokers over multiple AZs, allowing Redpanda to remain fully operational during an AZ outage, but this incurs inter-AZ data transfer costs.
The most impactful factor for your data transfer costs when running distributed systems like Apache Kafka® and Redpanda in the cloud is whether your streaming data platform needs to remain available during an Availability Zone (AZ) outage. This decision influences whether you opt for a single-AZ or multi-AZ deployment, with the latter incurring inter-AZ data transfer costs.
Follower fetching is a feature in Redpanda that allows consumers to fetch records from their closest replicas, regardless of whether it’s a leader. This means you can control the flow of read traffic to the cluster and avoid it crossing Availability Zone boundaries multiple times, thus helping to reduce data transfer costs.
There are two main strategies to reduce data transfer costs. First, optimize the data flow by using a more compact serialization format like Apache Avro or Protocol Buffers instead of JSON, and enable compression in your Kafka producer settings. Second, optimize the flow of data by controlling the read and write traffic to the cluster to avoid it crossing AZ boundaries multiple times, which can be achieved with Redpanda's follower fetching feature.
There’s no denying that the cost of data transfer in the cloud is expensive, and for large workloads, it can be the most expensive line item on your monthly cloud bill.
When calculating the cost of data transfer for running highly-available distributed systems like Apache Kafka® and Redpanda in the cloud, especially in a BYOC deployment, there’s one decision that’ll have the greatest impact on your data transfer costs — does your streaming data platform need to remain available during an Availability Zone (AZ) outage?
In this post, we define a simple set of rules for calculating cloud data transfer costs for your Redpanda workloads and discuss the Redpanda features that help you minimize these costs (so you can sleep better at night).
If your answer to the previous question is yes, then you’re in luck, because Redpanda supports both single-AZ and multi-AZ deployment modes. The tradeoff between the two is availability versus cost. Running all Redpanda brokers within a single AZ avoids the expensive inter-AZ data transfer costs, but an AZ outage will also cause a Redpanda outage.
On the other hand, spreading your brokers over multiple AZs and leveraging Redpanda’s rack awareness feature allows Redpanda to remain fully operational in the event of an AZ outage. Although you’ll still have to pay for the inter-AZ data transfer.
So what does it cost to transfer data between two AZs within the same region? As of early 2024, the three main cloud providers charge the following on inter-AZ networking:
* AWS charges $0.01 per GB “in” to and “out” from availability zones.
Now that we know the price of sending a gigabyte of data between one AZ and another, let’s define a set of rules to calculate how much the monthly data transfer costs would be for a multi-AZ deployment of Redpanda. Assuming that:
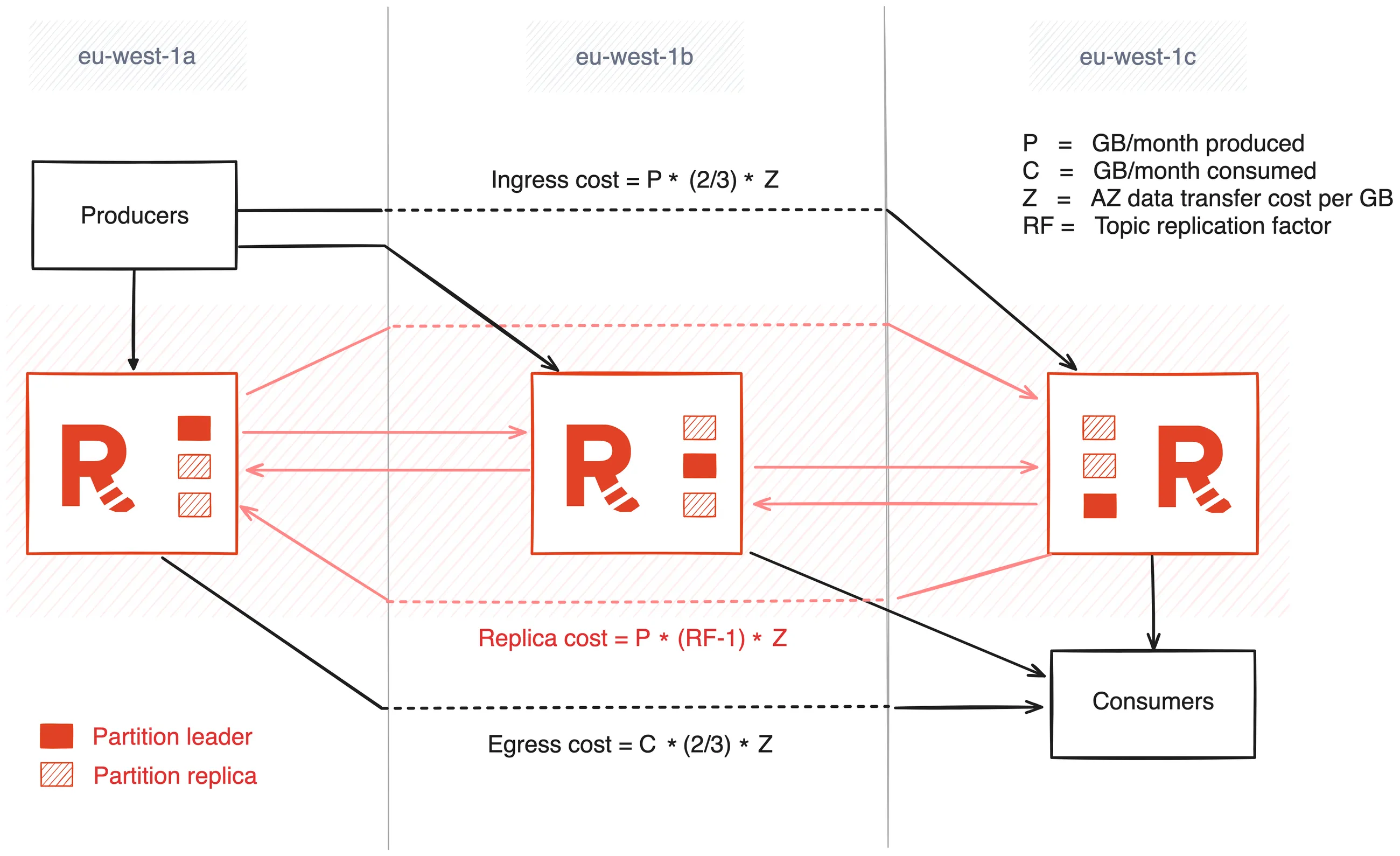
As we break down the costs, remember that there are three data flows to calculate:
Let’s dig into these data flows and how to calculate the cost of each.
For every 1GB of data produced, 2/3 of the data will cross into another AZ:
Ingress cost = P * (2/3) * Z
Where P is the GB of data produced per month, and Z is the cloud providers' AZ data transfer cost. The ingress cost can be mitigated by pinning partition leaders to the brokers that reside in the same AZ as your producers, but more on that later.
For every 1GB of data consumed, 2/3 of the data will come from another AZ:
Egress cost = C * (2/3) * Z
Where C is the GB of data consumed per month, and Z is the cloud providers' AZ data transfer cost. The egress cost can be mitigated by enabling Redpanda’s follower fetching feature, but again, more on this later.
For every 1GB of data produced, 2GB of replication data will cross into another AZ:
Replica cost = P * (RF-1) * Z
Where P is the GB of data produced per month, RF is the topic replication factor (typically 3 or 5), and Z is the cloud providers' cross-AZ data transfer cost.
The illustration below depicts a Redpanda cluster with three brokers deployed over three AZs in the AWS Ireland region.
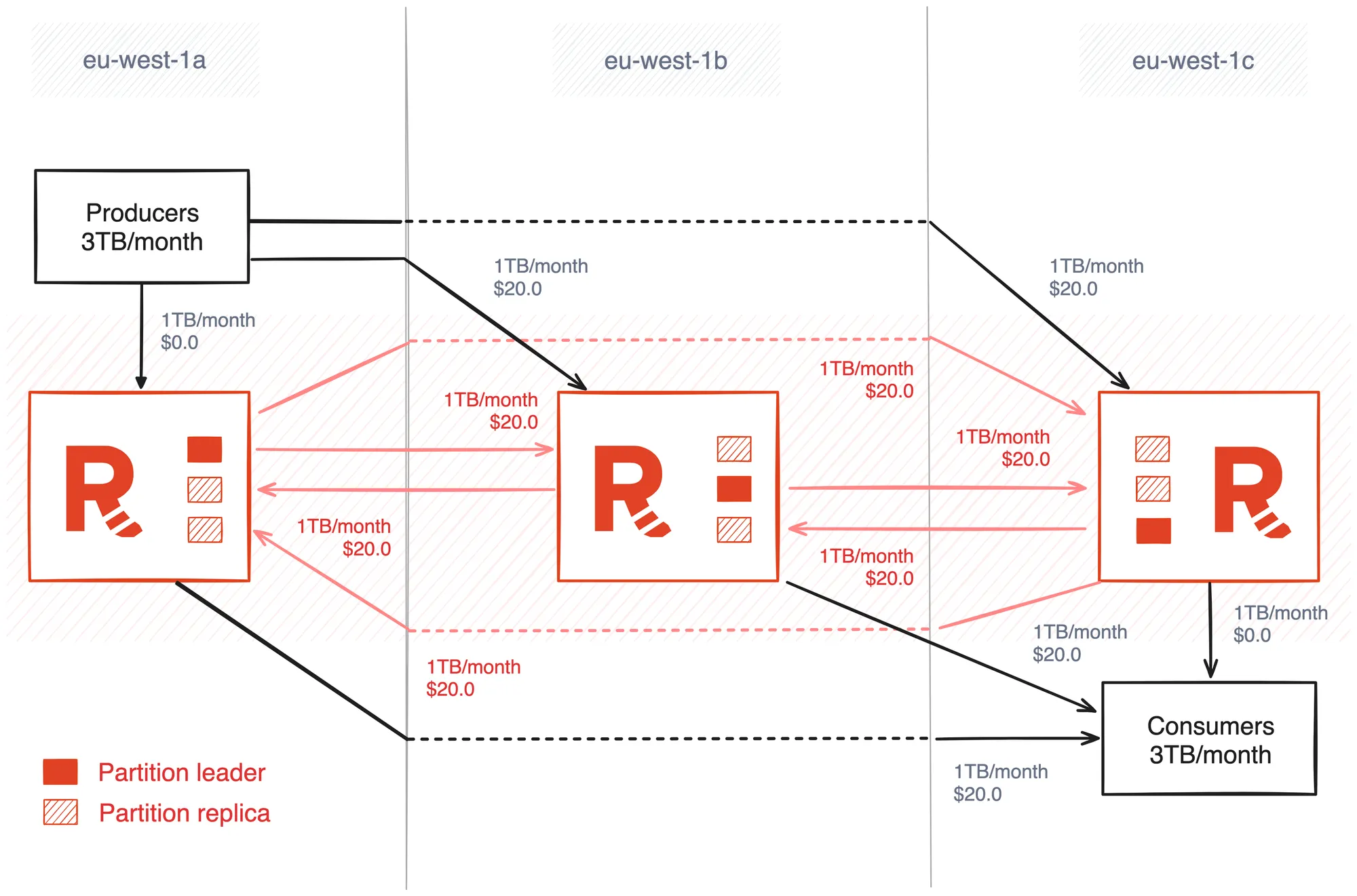
The workload has an average write throughput of approximately 1.2MB per second, which equates to 3TB per month, and the data is being produced on a topic with three partitions and a replication factor of three.
Given this information, we can apply the rules defined above to calculate the monthly data transfer cost of $200.0.
Producer Ingress costs:
P * (2/3) * Z
3000 * (2/3) * $0.02
= $40.0
Consumer Egress costs:
C * (2/3) * Z
3000 * (2/3) * $0.02
= $40.0
Intra-broker Replication costs:
P * (RF-1) * Z
3000 * 2 * $0.02
= $120.0
The golden question. To put it simply, the only way to avoid data transfer costs is to minimize the amount of data transferred between AZs. You essentially have two options to reduce the amount of data that has to be transferred from one AZ to another:
Kafka records consist of headers, a key, and a value. The value is simply a byte array, but what you pack into those bytes can have a significant impact on the size of your records, overall throughput, and cost. Optimizing the data flow essentially comes down to using a more compact serialization format to pack the same amount of information into as few bytes as possible.
JSON is a popular data format, but it’s not exactly compact. Apache Avro and Protocol Buffers are two popular alternatives that provide a much more efficient binary serialization, resulting in fewer bytes being transmitted over the network and lower data transfer costs.
It’s difficult to quantify the space savings as the encoding is specific to your data, but suffice to say, the difference between the binary representation of Avro or Protobuf when compared to JSON is significant enough to make a difference to your cloud bill.
In addition to using a more compact serialization format, consider enabling compression in your Kafka producer settings. By default, producers do not send records to Redpanda one at a time, they batch the records up per partition and send them together to amortize the network connection.
When enabled, compression is applied to each batch of records before the batch is sent to Redpanda, so the compression ratio (how effective the algorithm is at reducing the data size) is affected by the batch size (see batch.size and linger.ms) and the entropy of the data. What’s more, a compressed batch stays compressed until it reaches the consumers, so the space savings benefit both the network and storage costs.
To enable compression in Redpanda, set the topic property compression.type to producer, and the producer property compression.type to one of the following compression algorithms: gzip, snappy, lz4, or zstd. Enabling compression can be an easy win for improving message efficiency if you're unable to change serialization formats.
Note that Facebook’s ZStandard (zstd) is the newest codec supported by Kafka clients (added in Kafka v2.1.0). Based on the details captured in KIP-110, it outperforms the other compression codecs supported by Kafka and Redpanda in terms of ratio and speed.
Data replication is inherent in distributed systems, so that part at least is unavoidable, but what if you could control the flow of the read and write traffic to the cluster and avoid it crossing AZ boundaries multiple times? In Redpanda, you can.
On the consumer side, Redpanda supports follower fetching, which essentially means that consumers can fetch records from their closest replicas, regardless of whether it’s a leader or a follower. In a cluster deployed over multiple AZs, follower fetching allows consumers to prioritize fetching data from the brokers located within the same AZ, avoiding the expensive data transfer costs and higher latencies.

Controlling the flow of data on the producer side is a little trickier. Producers can only write to partition leaders, and for optimal performance it’s preferable to evenly balance partitions and partition leaders across the failure zones and brokers in a Redpanda cluster. This is why Redpanda has a continuous data balancing feature.
However, it’s possible to “pin” leaders to brokers to influence the flow of producer traffic by manually moving partitions and transferring leadership. We would only recommend doing this if you have a good grasp of your write patterns, and you’re comfortable with turning off continuous data balancing and leadership balancing so it doesn’t try to helpfully unwind your manual placement.
You should also note that leadership pinning will need to be periodically checked and probably reapplied since partition leaders can move due to natural broker behavior in Raft elections.
Partition leadership can be transferred using the Admin API, for example:
curl -X POST "http://localhost:9644/v1/partitions/kafka/<topic>/1/transfer_leadership?target=0"
curl -X POST "http://localhost:9644/v1/partitions/kafka/<topic>/2/transfer_leadership?target=0"
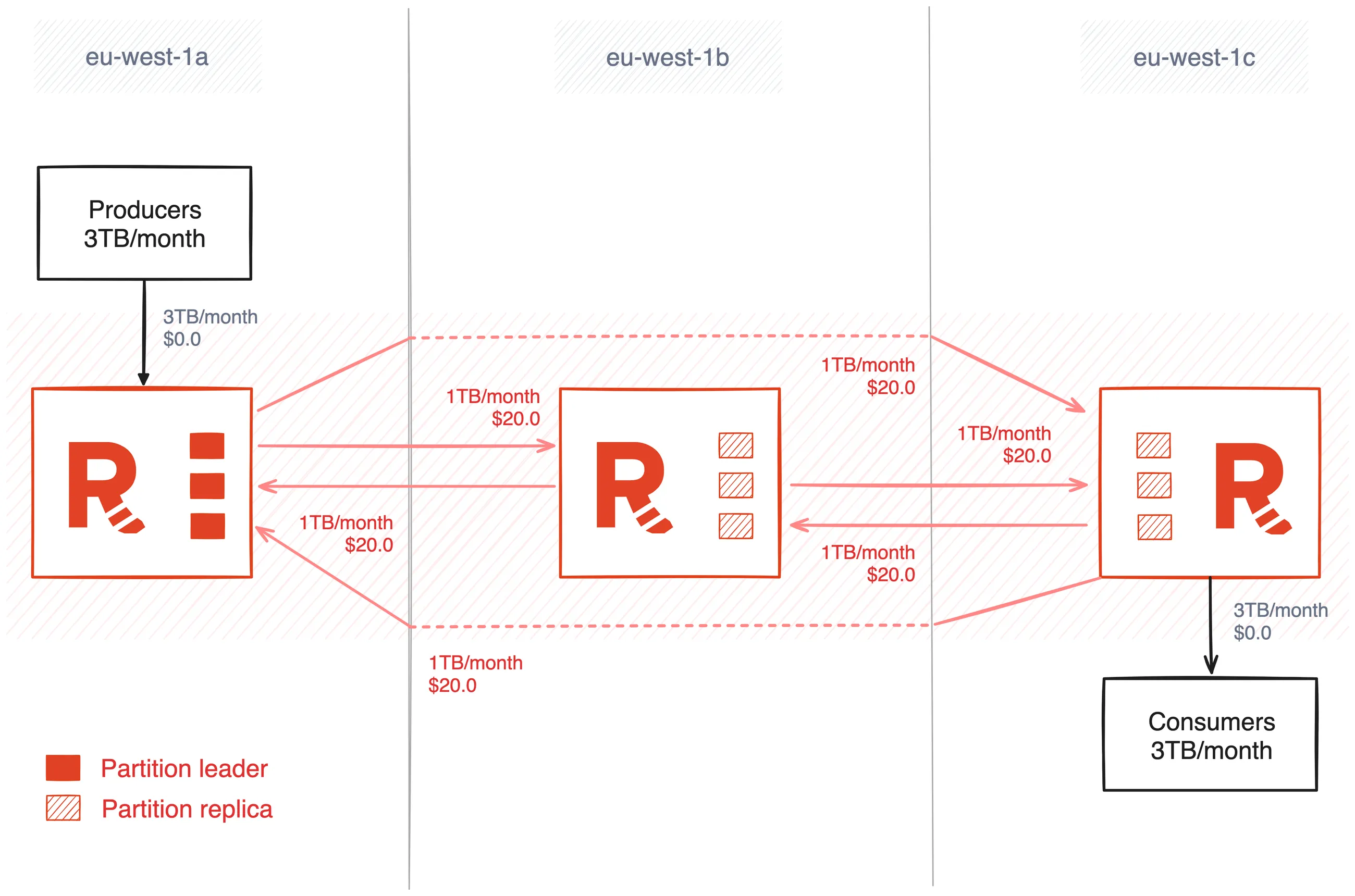
In this example, when follower fetching and leadership pinning are applied together, they lower the data transfer charges from $200.0 to $120.0, saving $80.0 per month!
In this post, we discussed how multi-AZ deployments of Redpanda can affect your monthly cloud bill. We also provided a simple set of rules for calculating the data transfer costs for your Redpanda workloads, and presented two options for reducing these costs — or even avoiding them altogether.
If you haven’t already, check out how Redpanda helped India’s largest social media company reduce its cloud spend by 70%. You can also learn more about Redpanda’s cost-saving features in our documentation and the Redpanda blog. If you have questions or want to chat with our team, join the Redpanda Community on Slack!
Subscribe to our VIP (very important panda) mailing list to pounce on the latest blogs, surprise announcements, and community events!
Opt out anytime.

