





Full CDC semantics land in the Iceberg output for Redpanda Connect
Your lakehouse mirrors the database, instantly.
This second post in our multi-part series covers pros/cons, infrastructure, Redpanda configuration, and resilience testing in High Availability environments.








Welcome back to another blog post on high availability (HA) and disaster recovery (DR) with Redpanda. This is our second blog post in this series. As a reminder, part one in this series focuses on failure scenarios, deployment patterns, and other considerations such as partition leadership/rebalancing and rack awareness (to name a few).
This post will focus on considerations when deploying a cluster in a single availability zone (AZ) where HA is important—specifically, ensuring that within an AZ, there are no single points of failure and that Redpanda is configured to spread its replicas across our failure domains. We will go over pros and cons of this deployment, discuss this deployment’s infrastructure, present deployment automation scripts, and then conclude with a summary and details on the next HA blog’s focus.
The basis for this architecture is Redpanda’s rack awareness feature, which means deploying n Redpanda brokers across three or more racks, or failure domains within a single availability zone.
Single AZ deployments (Figure 1) in the cloud do not attract cross-AZ network charges in the way that multi-AZ deployments, yet we can leverage resilient power supplies and networking infrastructure within an AZ to mitigate against all but total-AZ failure scenarios. This is in contrast to a cross-AZ deployment (Figure 2) which is designed to have fewer common-cause failures, yet at the expense of increased networking costs.


Whenever you move from a simple software deployment towards a fully geo-resilient and redundant architecture, there is an increase in cost, complexity, latency, and performance overhead. All of these need to be balanced against the benefits of increased availability and fault tolerance. That said, Redpanda’s use of the Raft consensus algorithm is designed to ensure that much of the cost and complexity of the system isn't put back onto the user or operations engineer and a single slow node or link doesn’t impact that performance.
Let’s evaluate how a simple high-availability solution for Redpanda affects the running of the system:
When deploying Redpanda for high availability within a data center, we want to ensure that nodes are spread across at least three failure domains. This would normally mean separate racks, under separate switches, ideally powered by separate electrical feeds or circuits. It’s also important to ensure there's sufficient network bandwidth between nodes, particularly considering shared uplinks, which may now be subject to high throughput intra-cluster replication traffic.
In an on-premises network, this HA configuration refers to separate racks or data halls within a DC (Figure 1).
There are many HA configurations available from various cloud providers (Figure 3). We’ll explore some of these options in the following sections.
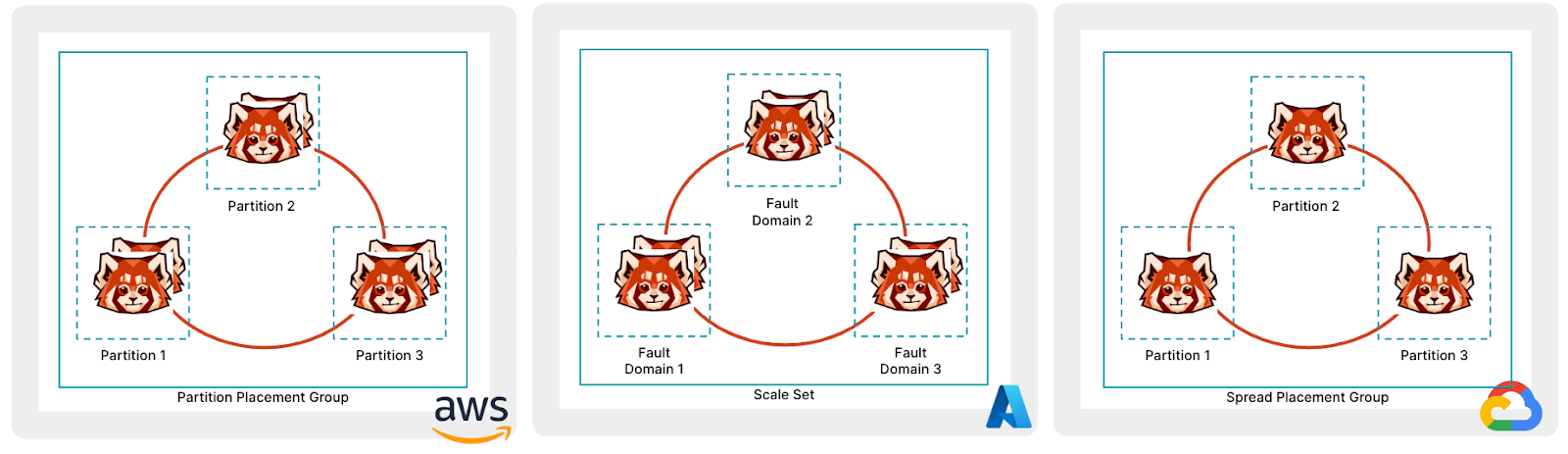
All of the concepts below can be automated using Terraform or a similar infrastructure-as-code (IaC) tool. We recently updated our Terraform scripts to take advantage of these availability deployment configurations within AWS, Azure, and Google Cloud.
AWS provides Partition placement groups, which allow spreading hosts across multiple partitions (or failure domains) within an AZ. The default number of partitions is three (with a max of seven). This can be combined with Redpanda’s replication factor setting so that each topic partition replica is guaranteed to be isolated from the impact of hardware failure.
Microsoft Azure provides Flexible scale sets, which allow you to assign VMs to specific fault domains. Each scale set can have up to five fault domains (depending on your region). Keep in mind that not all VM types support Flexible orchestration. For example, the Lsv2-series only supports Uniform scale sets.
Google Cloud has Instance Placement Policies. When using the Spread Instance Placement Policy you can specify how many availability domains you can have (up to a maximum of eight).
Note: Google Cloud doesn’t give you transparency as to which availability domain an instance has been placed into, which means that we need to have an availability domain per Redpanda broker. Essentially, this isn't running with rack awareness enabled, but is the only option available for clusters larger than three nodes.
To make Redpanda aware of the topology it's running on, we’ll need to configure the cluster to enable rack awareness and then configure each node with the identifier of the rack.
Firstly the cluster-property enable_rack_awareness, which can either be set in the /etc/redpanda/.bootstrap.yaml or can be set using the following command:
rpk cluster config set enable_rack_awareness true
Secondly, on a per-node basis, the rack id needs to be set in the /etc/redpanda/redpanda.yaml file, or via:
rpk redpanda config set redpanda.rack <rackid>
As with the Terraform scripts, we have modified our Ansible playbooks to take a per-instance rack variable from the Terraform output and use that to set the relevant cluster and node configuration. Our deployment automation can now provision public cloud infrastructure with discrete failure domains (-var=ha=true) and use the resulting inventory to provision rack-aware clusters using Ansible.
Once Redpanda has rack awareness enabled, it will ensure that no more than a minority of replicas appear on a single rack. Even when performing rebalancing operations, Redpanda will ensure that the leader assignment and replica assignment sticks to this rule.
In this example, we will deploy a high availability cluster into AWS, Azure, or GCP using the provided Terraform and Ansible capabilities.
1. Initialize a private key if you haven’t done so already:
$ ssh-keygen -f ~/.ssh/id_rsa
2. Clone the deployment-automation repository:
$ git clone https://github.com/redpanda-data/deployment-automation
3. Initialize terraform for your chosen cloud provider:
$ cd deployment-automation/aws (or cd deployment-automation/azure, or cd deployment-automation/gcp)
$ terraform init
4. Deploy the infrastructure (note: we assume you have cloud credentials available):
$ terraform apply -var=ha=true
5. Verify that the racks have been correctly specified in the host.ini file:
$ cd ..
$ cat hosts.ini
// Sample output:
[redpanda]
35.166.210.85 ansible_user=ubuntu ansible_become=True private_ip=172.31.7.173 id=0 rack=1
18.237.173.220 ansible_user=ubuntu ansible_become=True private_ip=172.31.2.138 id=1 rack=2
54.218.103.91 ansible_user=ubuntu ansible_become=True private_ip=172.31.2.93 id=2 rack=3
…
6. Provision the cluster with Ansible:
$ ansible-playbook --private-key <your_private_key> ansible/playbooks/provision-node.yml -i hosts.ini
7. Verify that Rack awareness is enabled
a. Get Redpanda hostnames:
$ grep -A1 '\[redpanda]' hosts.ini
Example output:
20.80.113.122 ansible_user=adminpanda ansible_become=True private_ip=10.0.1.7 rack=0
b. SSH into a cluster node substituting the username and hostname from the values above
$ ssh -i ~/.ssh/id_rsa <username>@<hostname of redpanda node>
c. Check rack awareness is enabled
$ rpk cluster config get enable_rack_awareness
true
d. Check the rack assigned to this specific node
$ rpk cluster status
CLUSTER
=======
redpanda.807d59af-e033-466a-98c3-bb0be15c255d
BROKERS
=======
ID HOST PORT RACK
0* 10.0.1.7 9092 0
1 10.0.1.4 9092 1
2 10.0.1.8 9092 2
In this blog post, we discussed the pros and cons of deploying Redpanda in a high-availability topology within a single data center or availability zone. We explored how this looks across AWS, Microsoft Azure, and GCP and looked at how this can be configured with Terraform. We also discussed the settings required to enable this within Redpanda and looked at how Ansible can be used to provision a cluster with rack awareness.
Finally, we ran an end-to-end example of provisioning a highly available Redpanda Cluster.
For the final part of this series, we’ll explore creating highly available clusters across availability zones and regions. In the meantime, join the Redpanda Community on Slack to ask your HA deployment questions, or to request coverage of other HA-related features.
Subscribe to our VIP (very important panda) mailing list to pounce on the latest blogs, surprise announcements, and community events!
Opt out anytime.

