




AI agent governance at scale: the four pillars every enterprise needs
Enterprise agents need governance infrastructure, not just better models
Mix and match different topics within the same cluster to optimize each workload for latency, cost, and performance









Yes, Redpanda can support both Cloud Topics (which store data to object storage systems such as Amazon S3) and regular, low-latency topics (stored to local SSD) in a single system. This is achieved by modeling Cloud Topics as a new kind of topic, the same way it did for Tiered Storage. This approach enables a single Redpanda deployment to be multimodal, supporting workloads with various storage options and delivering a range of choices along the cost-performance tradeoff spectrum.
In Redpanda's Cloud Topics feature, only a relatively small amount of critical metadata is replicated within Redpanda. This is a departure from the traditional approach of replicating both application data and metadata together, which simplifies the design of the system but comes at the cost of forcing all data to be transferred across expensive networks.
Redpanda uses cloud-based object storage as a near-limitless extension of local storage through a solution called Tiered Storage. With this, data is replicated across high-performance, low-latency local storage and asynchronously moved into cloud-based object storage, optimized for cost and reliability. This allows deep historical reads to be served at higher latency on a cluster with much lower infrastructure costs while retaining read-after-write latencies for the same data in the single digits or 10s of milliseconds.
Redpanda's mission is to provide high performance, simplicity, and flexibility for different types of real-time streaming data. It achieves this through its design as a replicated storage system based on the Raft consensus algorithm and its from-scratch construction in C++. This allows Redpanda to scale a system from embedded devices up to the largest NUMA machines available today.
Cloud Topics is a new feature in Redpanda designed to achieve low-cost, high-throughput streaming storage for applications with flexible latency requirements. It allows application data from Kafka clients to be sent directly to cloud storage, incurring no network transfer costs, while only a relatively small amount of critical metadata is replicated within Redpanda. This results in a significant reduction in networking costs.
Redpanda’s mission has always focused on high performance, simplicity, and flexibility to suit different flavors of real-time streaming data. From its design as a replicated storage system based on the Raft consensus algorithm to its from-scratch construction in C++ for complete control, Redpanda can scale a system from embedded devices up to the largest NUMA machines available today.
No matter how or where you deploy Redpanda, you can expect it to deliver low-latency operations. However, we’re seeing a noticeable rise in relaxed-latency workloads, where users running GB/sec workloads are happy to exchange slightly higher latencies for lower networking costs, such as for log collection and analytics.
As is the Redpanda way, we rolled up our sleeves and came up with a solution: Cloud Topics, a new way of achieving low-cost, high-throughput streaming storage for applications with flexible latency requirements. In this post, we share how we designed Redpanda Cloud Topics to persist directly to object storage and how you can be among the first to take it for a spin.
While replicated storage systems excel at providing high performance, traditional designs of such systems have struggled to take full advantage of the capabilities of modern cloud environments. For example, replicated storage systems—including Redpanda—are generally designed around the assumption that their primary storage consists of high-performance but unreliable media, such as solid-state drives. In contrast, services such as object storage available in most cloud environments provide inexpensive, highly reliable storage but come at a high performance cost, making them a poor choice for a replicated system’s primary storage.
Rather than being used as primary storage, Redpanda takes advantage of the unique capabilities of cloud-based object storage as a near-limitless extension of local storage through a solution we call Tiered Storage. With Tiered Storage, customers can get the best of both worlds, with data being replicated across high-performance, low-latency local storage and asynchronously moved into cloud-based object storage, optimized for cost and reliability. This approach enables deep historical reads to be served at higher latency on a cluster with much lower infrastructure costs while retaining read-after-write latencies for the same data in the single digits or 10s of milliseconds.
No matter how you deploy Redpanda today, you can expect the system to deliver on its commitment to low-latency operation. However, we also recognize the limitations of a system that is too narrowly optimized and how it can become inflexible. This is especially true for specific applications running on cloud-based deployments of Redpanda: as a replicated storage system, every byte an application writes into the system is copied over the network to multiple fault domains to keep data safe. Cloud providers understand this requirement and tend to charge for this critically important traffic. In some cases, the cost of these data transfers can be a significant proportion of the total cost of operation (estimates have ranged from 70-90% at high write throughput). Unfortunately, escaping these costs in replicated storage systems like Redpanda is difficult, even when applications can tolerate higher latencies.
At the same time, we see a meaningful rise in relaxed-latency workloads where users must run GB/sec workloads reliably but are perfectly happy to experience higher end-to-end latency in exchange for lower costs — as long as Redpanda keeps up with their throughput and respects durability guarantees. Such cases include cybersecurity/SIEM applications that detect anomalies in event streams and CDC streams that deliver data to systems of record.
We recently helped a large customer purposefully clamp Redpanda's produce latency up to single-digit seconds to reduce the compute overhead of a small batch workload. We found that consolidating two large same-sized clusters running a ~2GB/sec workload with >2 million messages/sec could save them over 50% of their cloud instance costs while also reducing their CPU utilization in the smaller cluster by almost 3x. This says nothing of the cloud networking costs that could be saved using the approach described in the next section.
In addition to wanting to take the relaxed latency tradeoff, we also see a growing class of Apache Kafka® workloads that actually require purely “cheap and deep” cloud storage to be economically viable at all, such as an observability storage layer for long-term storage of application logs and metrics.
Today in Redpanda, when a Kafka client produces data to a partition, the partition leader replicates the data and various supporting metadata (e.g., offsets and transactional information) to a set of partition replicas. Replicating both application data and metadata together simplifies the design of the system. Still, it comes at the cost of forcing all data to be transferred across expensive networks, even when applications would otherwise be able to trade off performance for reduced costs.
Cloud Topics changes this by introducing a new replication path into Redpanda through object storage. Rather than replicating all data across availability zones (AZ), the application data from Kafka clients is sent directly to cloud storage—incurring no network transfer costs—and only a relatively small amount of critical metadata is replicated within Redpanda. The result can be an orders-of-magnitude reduction in networking costs.
The trade-off for achieving these cost savings is that applications experience the higher latencies of cloud storage services. However, Redpanda’s new approach to internal batching of uploads ensures topic data arrives in cloud storage as quickly as possible and is available to consumers with a latency similar to the storage service’s own latency SLA, meaning sub-second. This batching also allows Redpanda to use broker resources more efficiently, reduce the number of cloud storage API calls, and realize a lower RPO for disaster recovery.
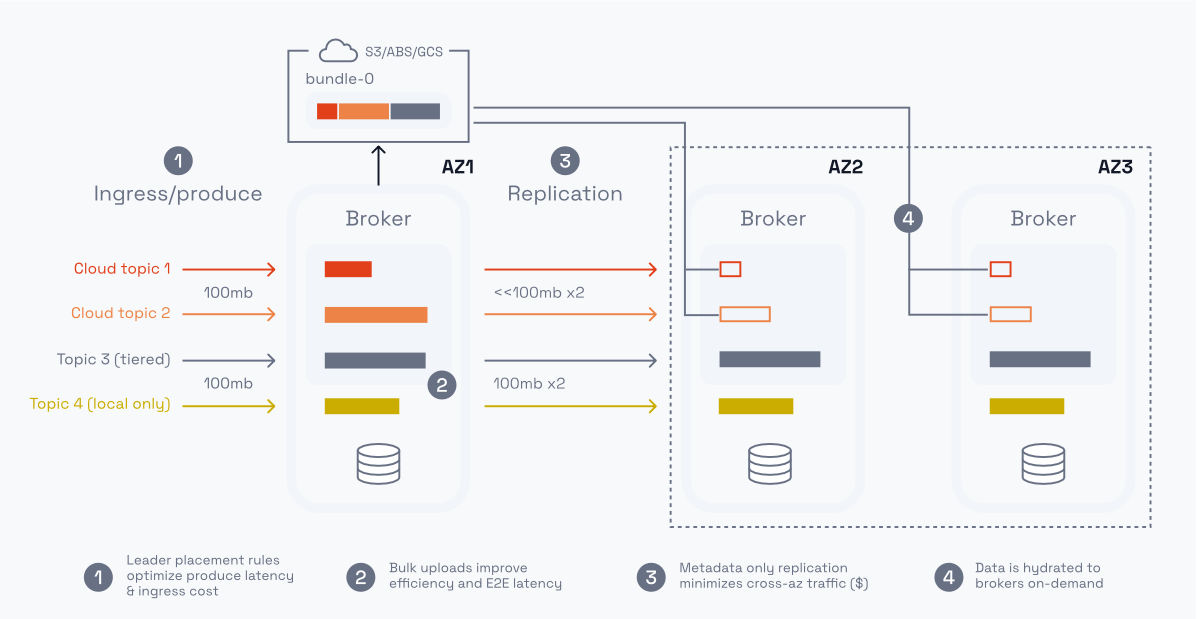
Since day one, Redpanda has emphasized operational simplicity and continues to deliver on this in many ways, including our dedication to a single-binary broker. During early design discussions, we wondered if Cloud Topics would require us to sacrifice operational simplicity by bringing in separate systems to manage metadata. However, we quickly realized that we could use our existing, industrial-strength Raft implementation to handle all of our metadata requirements without depending on new services that would otherwise complicate operations.
Having recognized that Redpanda already included the critical components for supporting Cloud Topics, the remaining challenge was supporting both Cloud Topics and regular, low-latency topics in a single system. We achieved this by modeling Cloud Topics as a new kind of topic, the same way we did for Tiered Storage, which can coexist with other types of topics.
This approach enables a single Repdanda deployment to be multimodal — that is, support workloads with various storage options delivering a range of choices along the cost-performance tradeoff spectrum; meeting the requirements of any operational or analytical streaming workload and allowing their topics to be used or combined seamlessly in a range of applications with the minimal overhead of a single system.
To learn more about Redpanda’s Cloud Topics and how you can get early access, contact us.
Enterprise agents need governance infrastructure, not just better models

What AI trends will shape analytics in the coming months?

How we turned opaque agent behavior into governed, provable workflows
Subscribe to our VIP (very important panda) mailing list to pounce on the latest blogs, surprise announcements, and community events!
Opt out anytime.