





Full CDC semantics land in the Iceberg output for Redpanda Connect
Your lakehouse mirrors the database, instantly.
Understand the differences between using Redpanda with Spark, Flink, or ksqlDB for processing data streams.








Apache Flink can easily read data from or write data to Redpanda. As Redpanda is fully Kafka API compatible, you can just configure it as a Kafka connection, and Redpanda takes care of the rest. You can create continuous streaming pipelines where event computations are triggered in Flink as soon as the event is received from Redpanda.
Apache Spark integrates well with the Kafka API, and since Redpanda is API-compatible with Kafka, you can use Redpanda for mission-critical workloads that you need to process via Apache Spark. You can stream any data from Redpanda and process the data in batches in Apache Spark, or use the Structured Streaming API to consume the data from Redpanda, process them in Spark, and save them in the Spark SQL DataFrame.
Apache Flink is a stream and batch processing framework designed for data analytics, data pipelines, ETL, and event-driven applications. It is a fourth-generation data processing framework that supports both batch and stream processing. Unlike Apache Spark, Flink is natively designed for stream processing and treats batch files as bounded streams. It can ingest streaming data from many sources, process them, and distribute them across various nodes.
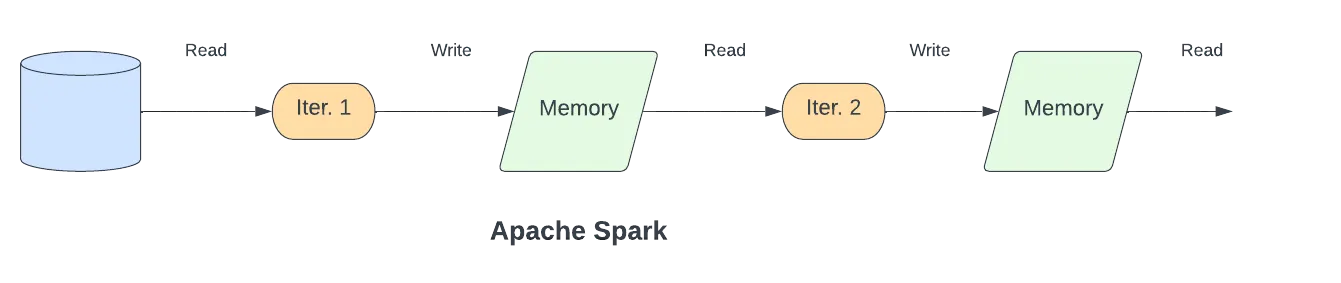
Apache Spark is a multi-language framework designed for executing data engineering, data science, and machine learning computation on single-node machines or clusters. It enhances MapReduce’s performance by processing data in memory instead of writing them to the disk in each step. Spark distributes the in-memory data in a logically partitioned way on many machines and calls these Resilient Distributed Datasets (RDDs), which are then used as an abstraction layer to manage the logically distributed data.
Apache Spark's advantages include its in-memory structure for fast performance, support for multiple languages, fault tolerance, integration with many technologies, advanced analysis capability, batch processing, stream processing, and SQL support. However, it also has some drawbacks such as high memory consumption, HDFS as the only state backend, a steep learning curve, time windowing only, and no native stream processing.
Modern business is digital and happens in real time. Users expect more interactive and instantaneous experiences all the time, which must be facilitated with suitable real-time data processing. Distributed applications like microservices, with automated deployments to public or private cloud platforms, have also incorporated more event-driven systems with a corresponding increased need for real-time capabilities. In this context, applications rely on real-time stream processing to power their business logic and deliver the appropriate real-time experiences for their users and decision-making capabilities for themselves, though it’s important to understand the difference between streaming data vs stream processing when evaluating tools and architectures.
As the amount of data that must be processed has grown, companies have focused on large-scale data processing technologies that can analyze data, run machine learning functions, and create materialized views and time windows. There are many available stream processing technologies, but this article focuses on three of the most popular:
This article introduces these stream processing frameworks and compares the pros and cons of the tools and some of their more unique features. You'll also learn how to use each tool with Redpanda for real-time data processing.
Apache Spark is a popular open-source analytics engine that is designed for scalable big data analytics. The Apache Spark research project was started in 2014 at UC Berkeley as a solution to the limitations of a MapReduce algorithm.
MapReduce is a first-generation distributed data processing system. It processes data that is parallelizable and performs computation on a distributed, horizontally scalable infrastructure. As a distributed system, MapReduce applies a particular linear data flow structure, which consists of MapReduce programs that read input from a disk, map a function across the data, reduce the resulting data of the map, and store it on the disk again.

Spark is a third-generation data processing framework that enhances MapReduce’s performance by processing data in memory instead of writing them to the disk in each step. Spark distributes the in-memory data in a logically partitioned way on many machines and calls these Resilient Distributed Datasets (RDDs), which are then used as an abstraction layer to manage the logically distributed data.
Spark consists of many components such as Spark SQL, MLlib, Spark Streaming, and GraphX. These components were not included from the start but have been developed over the years to satisfy many big data system requirements. Spark Streaming is one of the most important components, which provides support for live data streams generated by a variety of sources such as Apache Kafka, Apache Flume, Twitter, ZeroMQ, Amazon Kinesis, and more.
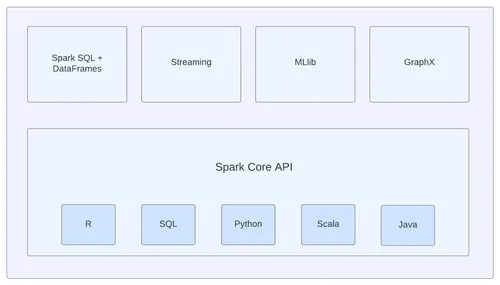
Moreover, Spark has a high-level API called Structured Streaming, which is built on top of Spark SQL API. Structured Streaming can stream the same operations that you would perform in batch mode, such as querying a static RDD.
Both Spark Streaming and Structured Streaming API integrate well with the Kafka API.
Because Redpanda is API-compatbible with Kafka, you can use Redpanda for mission-critical workloads that you need to process via Apache Spark.
You can stream any data from Redpanda and process the data in batches in Apache Spark. Or, you can also use the Structured Streaming API to consume the data from Redpanda, process them in Spark, and save them in the Spark SQL DataFrame as an example.
The following Python code snippet is a very high-level example of reading a stream from a Redpanda topic called my-redpanda-topic, by accessing the Redpanda cluster via redpandahost:9092:
df = spark \
.readStream \
.format("kafka") \
.option("kafka.bootstrap.servers", "redpandahost:9092") \
.option("subscribe", "my-redpanda-topic") \
.load()
df.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)")You can use Redpanda and Spark Streaming for real-time analysis, sentiment analysis, real-time fraud detection, and many more real-time stream processing use-cases that require the computational capabilities of Apache Spark. For more detailed information on how to use Apache Spark with Redpanda, check out our blog on structured stream processing with Redpanda and Apache Spark.
Apache Spark is a great framework to use with Redpanda streaming, but as is the case with many tools or frameworks, there are a few pros and cons worth mentioning.
One of the game-changing advantages of Spark is its in-memory structure, which provides very fast performance. However, Spark’s in-memory structure can cause high memory consumption as it might respond to many stream processing requests simultaneously.
Apart from the in-memory structure, the following is an aggregated list of pros and cons for Apache Spark:
These are just some examples, and there will likely be many other pros and cons of Apache Spark that are either use-case specific or related to the streaming technology being used.
Apache Flink is an open source distributed processing engine that provides stateful computations over unbounded and bounded data streams. In Flink, everything is considered as a stream, including the batch files.
Flink is a fourth-generation data processing framework and supports both batch and stream processing. Unlike Apache Spark, Flink is natively designed for stream processing. It treats batch files as bounded streams.
You can ingest streaming data from many sources, process them, and distribute them across various nodes with Apache Flink.
Apache Kafka is one such streaming source, which is considered a great persistent layer for stream processing applications. Flink provides a Kafka connector library for reading data from a Kafka topic or writing data to Kafka topics.
Apache Flink can easily read data from or write data to Redpanda. It does not provide a particular API or connector for Redpanda, but because Redpanda is fully Kafka API compatible, you can just configure it as a Kafka connection, and Redpanda takes care of the rest.
You can create continuous streaming pipelines where event computations are triggered in Flink as soon as the event is received from Redpanda.
The following Java code snippet is a small example of using the connector library to read a stream from a Redpanda topic called my-redpanda-topic:
KafkaSource<String> source = KafkaSource.<String>builder()
.setBootstrapServers("redpandahost:9092")
.setTopics("my-redpanda-topic")
.setGroupId("my-group")
.setStartingOffsets(OffsetsInitializer.earliest())
.setValueOnlyDeserializer(new SimpleStringSchema())
.build();
DataStream<String> dataStreamSource = env.fromSource(source, WatermarkStrategy.noWatermarks(), "Redpanda Source");
//Stream processing actions on dataStreamSource...You should note that a class called KafkaSource is used for consuming the data from Redpanda. Inversely, to send messages to Redpanda, you must use the KafkaSink to stream data to Redpanda. You might come across some examples that use classes like FlinkKafkaConsumer and FlinkKafkaProducer, which are the deprecated Flink Kafka connector classes.
For more detailed information about using Apache Flink with Redpanda, check out the building streaming applications using Flink SQL and Redpanda tutorial.
Apache Flink is a great native stream processing system to use with Redpanda. However, as with the other streaming technologies, there are several pros and cons of Apache Flink you should consider.
One of the great benefits of Apache Flink is its very shallow learning curve. It’s very easy to get started and has good documentation. However, good documentation is not enough in terms of support, particularly if you run into more advanced issues; compared to Apache Spark, Apache Flink has a smaller community that can provide limited support.
Apart from the learning curve, documentation, and the support, the following is an aggregated list of pros and cons for Apache Flink:
Again, these are simply some examples of Apaches Flink’s pros and cons, which can vary depending on the specific use-case or related to the streaming technology you are using.
The database ksqlDB is for building stream processing applications on top of Apache Kafka. It is based on the Kafka Streams API and licensed under the Confluent Community License Agreement. It is also a distributed, scalable, real-time stream processing framework that provides a lightweight SQL syntax.
Powered by the Kafka Streams API, ksqlDB is a robust, embeddable, stream processing engine that provides a simple way to build standard Java stream processing applications. It extends Kafka Streams API by providing more features, such as a streaming server and an easy-to-use SQL interface.
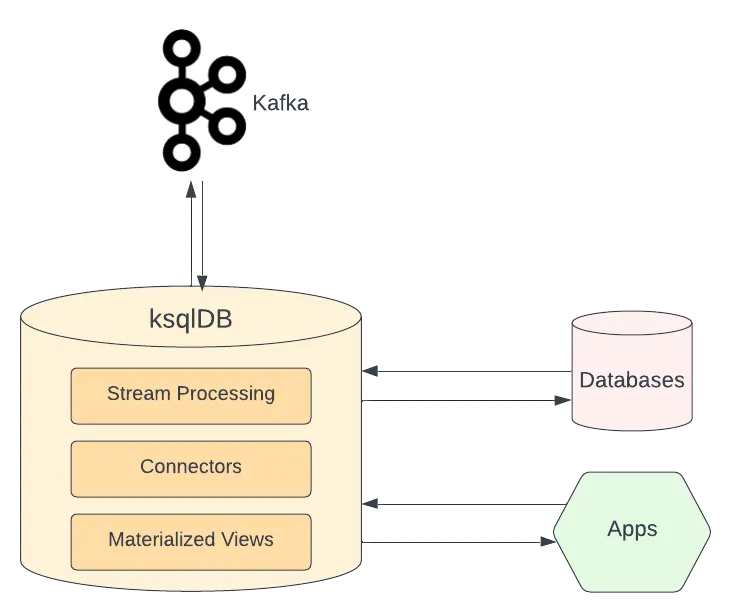
The ksqlDB has Apache Kafka in its core as the persistence layer. Since it uses the Kafka Streams API, it can access and use any Kafka cluster without integration configuration.
Redpanda can be easily used as the Kafka replacement of ksqlDB. The standalone installation of ksqlDB requires a Kafka backbone, so Redpanda can be a great replacement as it is fully compatible with the Kafka API.
The following Docker Compose YAML is an example of setting up a ksqlDB server and a ksqlDB CLI container that is connected to the Redpanda cluster:
---
version: '2'
services:
redpanda:
command:
- redpanda
- start
- --smp
- '1'
- --reserve-memory
- 0M
- --overprovisioned
- --node-id
- '0'
- --kafka-addr
- PLAINTEXT://0.0.0.0:29092,OUTSIDE://0.0.0.0:9092
- --advertise-kafka-addr
- PLAINTEXT://redpanda:29092,OUTSIDE://localhost:9092
image: docker.vectorized.io/vectorized/redpanda:latest
container_name: redpanda-1
ports:
- 9092:9092
- 29092:29092
ksqldb-server:
image: confluentinc/ksqldb-server:0.25.1
hostname: ksqldb-server
container_name: ksqldb-server
depends_on:
- redpanda
ports:
- "8088:8088"
environment:
KSQL_LISTENERS: http://0.0.0.0:8088
KSQL_BOOTSTRAP_SERVERS: redpanda:9092
KSQL_KSQL_LOGGING_PROCESSING_STREAM_AUTO_CREATE: "true"
KSQL_KSQL_LOGGING_PROCESSING_TOPIC_AUTO_CREATE: "true"
ksqldb-cli:
image: confluentinc/ksqldb-cli:0.25.1
container_name: ksqldb-cli
depends_on:
- ksqldb-server
entrypoint: /bin/sh
tty: trueYou can use Redpanda and ksqlDB to create a streaming ETL pipeline (aka a streaming data pipeline) for real-time data analysis, creating materialized views of event-driven microservices, predictive analytics, and many more similar use-cases.
For more detailed information on how to use ksqlDB with Redpanda, check out this tutorial on how to build a materialized cache with ksqlDB and Redpanda.
The ksqlDB is a Kafka native stream processing system that is very easy to use with Redpanda. However, as with the other tools, it does have its pros and cons.
One of ksqlDB’s greatest advantages is strong integration with Apache Kafka. Whereas other streaming frameworks manage this integration using connectors or Kafka libraries, ksqlDB has Kafka in its core. However, ksqlDB has poor analytics capability in comparison with Flink and with Spark, especially, that have more tools to handle workloads for analytics.
Apart from the Kafka integration, analytics, capabilities and licensing model, here is an aggregated list of pros and cons for ksqlDB:
As was the case with the other tools, the stated pros and cons are just examples, and there might be many more depending on either the specific use-case or related to the streaming technology that is used.
Now that you understand the differences between popular stream processing frameworks Apache Spark, Apache Flink, and ksqlDB, you can make more informed decision about when to use each tool. And, thanks to the integration tutorials we’ve linked in each section above, you know how to use any of them with Redpanda to accomplish your stream processing needs. Use any of these tools with Redpanda for real-time sentiment analysis, fraud detection, predictive analytics, and more.
Follow the Redpanda Blog for future tutorials and articles about integration use-cases of Redpanda and other cool data technologies, and join our Slack community to share what you plan to build with Redpanda. To contribute to our GitHub repo, submit an issue here. For specific feature and usability questions, our documentation can help.
Subscribe to our VIP (very important panda) mailing list to pounce on the latest blogs, surprise announcements, and community events!
Opt out anytime.

