





Real-time Change Data Capture with Redpanda Connect and MySQL
Stream every insert, update, and delete from your database the moment it happens
Find out how we engineered our Continuous Data Balancing solution to make running Redpanda clusters safer and easier.








During the lifetime of a long-running Redpanda cluster, many changes can affect the distribution of data across a cluster. Nodes could go down or be intentionally decommissioned, new nodes could be added to the cluster, and some nodes may accumulate more data than others or have to deal with heightened producer load.
Maintaining data protection guarantees (i.e. guarantees that data is sufficiently replicated and durably persisted so it won't be lost in case of node or disk failures), as well as optimal cluster operation in the presence of these events requires actively managing data distribution by moving partition replicas between nodes.
However, manually planning and executing partition movements is hard and error-prone. In Redpanda 22.2, we introduced a new subsystem that continuously monitors the cluster and schedules necessary partition movements automatically as needed, to keep data evenly balanced and to make the best use of available disk space. We refer to this process as Continuous Data Balancing.
Note: You need a Redpanda Enterprise license to access this feature.
In this post, we'll discuss how this feature makes the cluster admin’s life easier, how we implemented it, and how to use it.
Preventing a failure is better than dealing with its consequences. This simple principle is especially important for complex, fault-tolerant systems like Redpanda. If the system isn't fault-tolerant, every small failure means the service stops until the cluster admin fixes it. But, if the system is fault-tolerant, small failures lead only to slight degradation of the system. However, these small failures have to be fixed before they inevitably lead to a much bigger failure that might be difficult to recover from.
One way to think about this is that small failures introduce disorder or entropy that slowly accumulates in the system and degrades it until it breaks down. Continuous Data Balancing can help by acting as an anti-entropy mechanism to keep the cluster in its optimal condition.
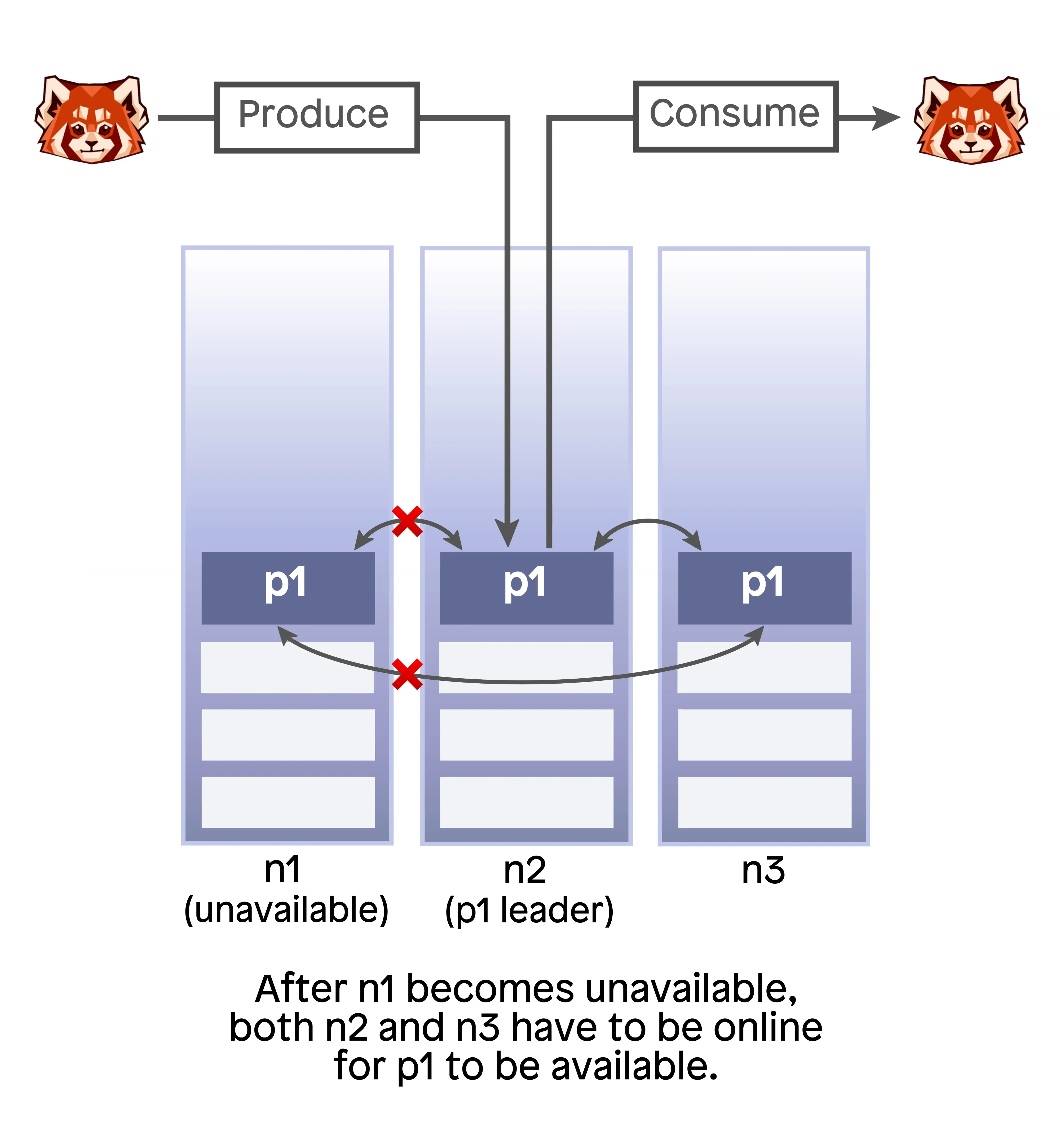
Consider this scenario: A common replication factor for a partition in Redpanda is three. This means that copies of each partition are stored on three different servers and, even if one server goes down, the partition remains available for both producing and consuming. This could go unnoticed by the client (apart from possibly a small latency hiccup caused by the leader election), but the partition in this state is very fragile – a single additional node failure will cause data unavailability and may even cause data loss. In this scenario, you'd want to move the unavailable replica to a healthy node so the partition retains its usual resilience guarantee of tolerating a one-node failure.
Data balancing can help not only with ensuring data protection and data availability, but also performance. By intelligently placing partition replicas, we can ensure that there is no skew in the usage of CPU and I/O resources, thereby reducing latency (existing Redpanda mechanisms such as automatic leadership balancing also help with this).
In this first release of Continuous Data Balancing, we decided to focus on the following two scenarios: Node failure and disk usage skew.
We already introduced the node failure scenario above. After Redpanda detects that a node has been unavailable for some time, it'll move partition replicas hosted by that node to other, healthy nodes.
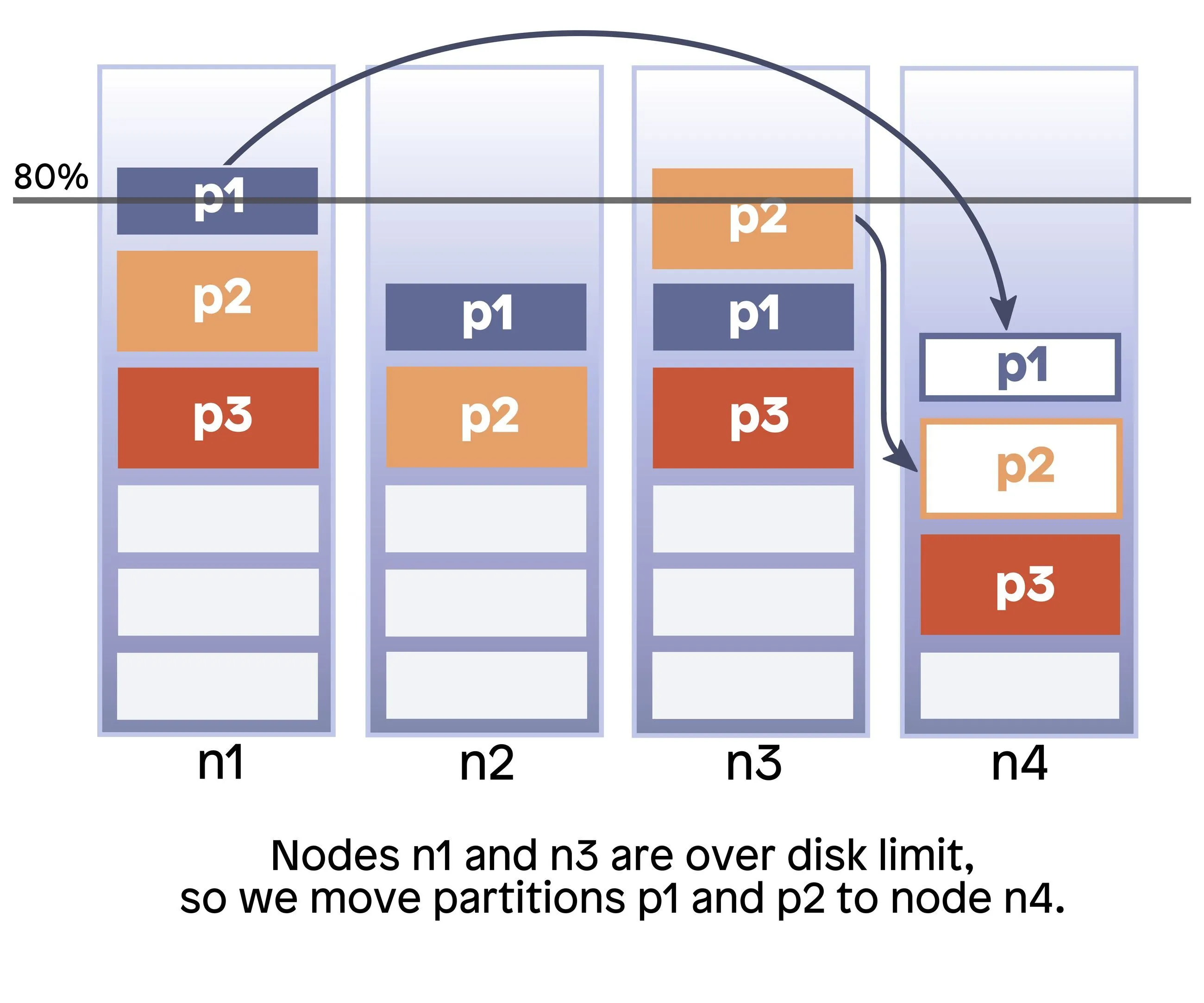
The disk usage skew scenario can arise if uneven producer load leads to one of the nodes receiving more data than others in the cluster. Sooner or later, the clients will have to stop producing, even if there's a lot of free space on other nodes of the cluster. This could unfortunately lead to some of the incoming data having to be “dropped on the ground” because the cluster won’t accept it.
From the producing application’s perspective, this can result in data loss. In this scenario, moving some partition replicas away from the node with the most partitions and least disk space will spread the load and also allow the cluster to continue receiving data.
As Continuous Data Balancing is developed further and becomes more sophisticated in the future, we expect it to be helpful in a number of additional scenarios.
In this section, we’ll discuss how Continuous Data Balancing works under the hood. It can be understood as two layers:
To make data balancing work, we first needed a solid foundation to build upon – a mechanism to move partition replicas from one node to another in a way that is safe, fault-tolerant, and doesn’t impact client operations.
We can think of the partition movement solution as being broken down into four needs:
Replication of partition data in Redpanda is implemented using the Raft consensus protocol. We can think of moving partitions as changing a set of replicas. For example, if a partition had replicas on nodes 1, 2, and 3, then moving a replica from node 1 to node 4 is equivalent to changing the set of replicas to 2, 3, 4. Luckily, Raft natively supports changing the set of replicas via the joint consensus mechanism.
In short, when a partition enters joint consensus, making decisions such as acknowledging client writes requires quorum from both new and old replica sets. The new node (4 in our example) is first added as a learner - a node that isn’t needed for quorum. Only when it catches up with the leader does it become a voter - a full member of the consensus group. The next step is to transition to the simple configuration with the new set of nodes. Finally, we can delete the partition data on nodes that are no longer part of the replica group.
The great thing about joint consensus is that, during the whole process, we can continue servicing client operations with the same strong consistency guarantees as Raft normally provides!
One challenge we had to overcome in developing the partition movement primitive was its availability. We uncovered this when we tested partition movement while introducing disruptions, such as randomly crashing Redpanda nodes and bringing them back up. It turned out that if one of the nodes that hosted a replica in both old and new configurations (nodes 2 and 3 in our example above) crashed in the joint consensus phase, we couldn’t elect a new partition leader, and the partition would then become unavailable for client reads and writes.
This was unacceptable because this meant that in the joint consensus phase our availability guarantees were lower than during the normal operation. The nitty-gritty of the solution will be discussed in an upcoming blog post. In short, it involves adding an additional Raft configuration change step.
An additional primitive that we needed was movement cancellation. To understand why this is necessary, consider a situation in which we start moving a partition to a node that then goes offline. While that node is offline, we can’t exit joint consensus and finish the movement process. To make progress, we need to be able to cancel the movement and return to the old replica set. Fortunately, cancellation can be neatly and safely implemented in the reconfiguration protocol by transitioning back to the old replica set instead of the new one from the joint consensus state.
We also needed a way to make progress when clean cancellation is not possible. For example, when not one but two of the nodes in the new replica set go down. For these cases we implemented a forced movement abort primitive. Because this is an unsafe operation that can in some cases lead to loss of already acknowledged data or replica divergence, we never do it automatically but, instead, leave the decision to trigger it to the human operator.
The final piece of the puzzle was limiting the network bandwidth used by partition movement so that client traffic always has sufficient network bandwidth even when a lot of data needs to be moved to nodes hosting new partition replicas.
In this section, we discuss the higher-level mechanics of data balancing: how the balancing subsystem plans and schedules movements.
The planner is centralized – it analyzes and plans movements for the whole cluster instead of local planning for a single node or a Raft group. This makes it easier to generate optimal movement plans and helps avoid thrashing – undesirable behavior when partition distribution does not stabilize quickly and partitions are needlessly moved back and forth between nodes. On the other hand, scaling a centralized planner presents a significant engineering challenge.
The planner uses the state reconciliation pattern. According to this pattern, the planner runs in a loop and at each iteration of this loop it compares the current state with the desired state, generates a step that brings us closer to the goal, executes it, and then re-plans (instead of generating a large plan that should bring us to the desired end state and executing it in a fire-and-forget fashion). This makes the balancer more resilient and responsive to unexpected changes in the environment, such as a rapid change in produce skew.

It's natural to co-locate the balancer with the controller log leader (controller log is an internal Redpanda partition that is replicated on all nodes and contains cluster management commands including, among others, partition movement commands). This way the balancer can always see the latest partition map and can easily add new commands to the controller log. It also provides fault tolerance – if the controller partition leader fails, a new leader will be elected, and the balancer process will simply restart there. As noted earlier, scaling is a concern, but in our tests the planner comfortably handled several tens of thousands of partitions.
The balancer also needs information about the state of the nodes (including free and total disk space). This information is provided by the component called the health monitor that periodically polls nodes and collects per-node data.
Planning an optimal step is, generally speaking, an NP-hard problem. But, in our experience, a greedy approach is easy to understand and is enough to generate a sufficiently useful plan. To generate the step we need to:
Placing the replicas is done using the partition allocator. This is a Redpanda component that solves the problem of replica placement that is subject to hard constraints (e.g. the replica must not be placed on an unavailable node) and soft constraints (e.g. the replica should preferably be placed on the node with the most free space).
Having built out the partition movement and balancer components, Continuous Data Balancing was now ready to use.
Enabling continuous data balancing is pretty simple: Set the partition_autobalancing_mode cluster config property to continuous (You’ll need a Redpanda Enterprise license).
The default node unavailability timeout is 15 minutes. To change it, set the partition_autobalancing_node_availability_timeout_sec property. The default maximum node disk usage percentage is 80%. To change this, set the partition_autobalancing_max_disk_usage_percent property. All properties are runtime-configurable and do not require a restart after change.
The main way to observe the high-level state of the balancer is to use Redpanda’s CLI: rpk. In this case, use the rpk cluster partitions balancer-status command. Here is a sample output:
Status: in_progress
Seconds Since Last Tick: 1
Current Reassignment Count: 19
Unavailable Nodes: [4]
Over Disk Limit Nodes: []In this example, data rebalancing is underway because node 4 is unavailable and 19 partitions are currently moving. The Seconds Since Last Tick field shows how much time has passed since the reconciliation loop last ran.
Check out the documentation for more information on how to configure and use Continuous Data Balancing in Redpanda.
In this post, we’ve discussed how data balancing can make operating a long-running Redpanda cluster easier and safer with lower administrative overhead, and how to enable and monitor Continuous Data Balancing in Redpanda.
We’re always interested to hear about our users’ experiences with our features, including this one! Share your feedback or ideas for improvements in our Redpanda Community on Slack. You can also submit an issue on GitHub, or reach out to us on Twitter @redpandadata.
Happy data balancing!
Subscribe to our VIP (very important panda) mailing list to pounce on the latest blogs, surprise announcements, and community events!
Opt out anytime.

