





Deploy agents you can trust with centralized AI governance
You can't scale what you can't trust. A governance layer fixes that.

In the first post of this multi-part series, we cover common failure scenarios, deployment patterns, and cluster characteristics to consider for high-availability deployments.








You can monitor the health of your Redpanda cluster through the command 'rpk cluster health'. This command will inform you about the number of nodes that are down, if any, as well as if you have any leaderless partitions. This helps in ensuring the availability and performance of your Redpanda cluster.
Redpanda offers four key deployment patterns for high availability (HA) and disaster recovery (DR): Clustered deployment, Multi-availability-zone deployment, Multi-region deployment, and Multi-cluster deployment. Each pattern has its unique features and considerations, such as handling individual node failure, tolerating loss of a rack or failure domain, and managing inter-AZ bandwidth and latency characteristics.
In Redpanda, a cluster's availability is directly tied to replica synchronization. Brokers can be either leaders or replicas for a partition. The leader handles writing data to the log and determining which replica brokers are in-sync. The replicas receive messages written to the partition of the leader broker and send acknowledgments to the leader after successfully replicating the message to their internal partition. Redpanda uses the Raft replication protocol and a quorum-based majority for synchronization.
Rack awareness is a crucial feature in Redpanda's deployment for ensuring cluster availability regardless of failures. It allows Redpanda to spread partition replicas across available brokers in a way that avoids keeping those replicas in the same physical location. Redpanda determines where a replica is placed based on criteria like the number of racks versus replicas, the number of available CPU cores, and node utilization.
Redpanda is the modern, distributed, and fault-tolerant platform for streaming data. It is designed to ensure data integrity and availability, even at high-throughput levels. However, the choices you make as you deploy a Redpanda cluster can have an impact on the overall availability of the platform, and may have an effect on performance. When you are streaming important data, it is imperative that the availability of the platform and the data is maintained under failure conditions.
In this post, we will look at the different options available when you are considering a business-critical deployment of Redpanda. For some scenarios, an active/passive deployment will be appropriate, whereas others will trade latency for geo-resilience. We’ll teach you how to evaluate such scenarios and the appropriate deployment patterns to mitigate them.
In the era of plentiful infrastructure, it’s easy to believe that we don’t need to consider failure domains. However, the reality is that, even on virtualized infrastructure, failures do happen, both localized and systemic, albeit with various probabilities. Architects need to consider the probability of specific types of failure and the likely impact on their overall system availability.
Some typical failure modes are summarized in the table below:
| Impact | Typical Mitigation | |
| Individual node failure | Loss of function for an individual node, or for VMs hosted on that node | Clustered deployment |
| Rack or switch failure | Loss of all (and/or connectivity to) nodes/VMs hosted within that rack | Clustered deployment spread across multiple racks and/or network failure domains |
| DC/DC-room failure | Loss of all (and/or connectivity to) nodes/VMs hosted within that DC/DC-room | Stretch cluster and/or replicated deployment |
| Region failure | Loss of all (and/or connectivity to) nodes/VMs hosted within that region | Geo stretched-cluster (latency dependent) and/or replicated deployment |
| Global, systemic outage (DNS failures, routing failures, etc.) | Complete outage for all systems and services impacting customers and staff | Offline backups; replicas in 3rd party domains |
| Human action (inadvertent or malicious) | Human action can corrupt availability of data and any synchronous replicas up until detection | Offline backups |
In this section, we’ll explore some of the key patterns for high availability (HA) and disaster recovery (DR) before deep-diving into a typical HA deployment. We will provide additional coverage of other patterns in several follow-up posts to this one.
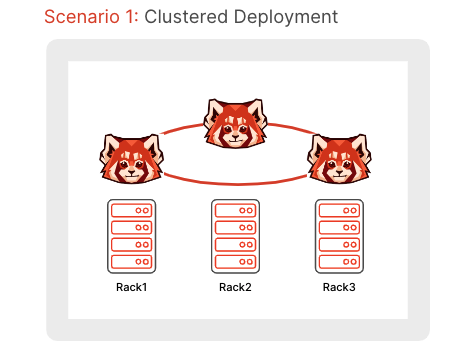
Redpanda is designed to be deployed in a cluster (although clusters with a single node work perfectly well, they aren’t resilient to failure). Redpanda has been proven to scale to many nodes, which introduces the ability to handle individual node failure. Redpanda’s rack awareness feature ensures that Redpanda can tolerate the loss of a rack or failure domain.
Note: By “availability zone” (AZ) we are referring to discrete data centers or data halls that have discrete failure domains (power, cooling, fire, network), but are served by high-bandwidth links with low latency (and typically are within a small number of miles of one another). Availability zones will still have common-cause failure domains (such as force majeure events).

Similar to a standard clustered deployment above, a cluster can be deployed across multiple AZs by configuring each AZ as a “rack” when using the Rack Awareness feature.
With Redpanda’s internal implementation of Raft, Redpanda can tolerate losing a simple minority of replicas for a given topic or for controller groups. For this to translate to a multi-AZ deployment, however, it is necessary to deploy to at least three AZs (affording the loss of one zone). It’s worth noting that in a typical multi-AZ deployment, cluster performance will be constrained by the inter-AZ bandwidth and latency characteristics.
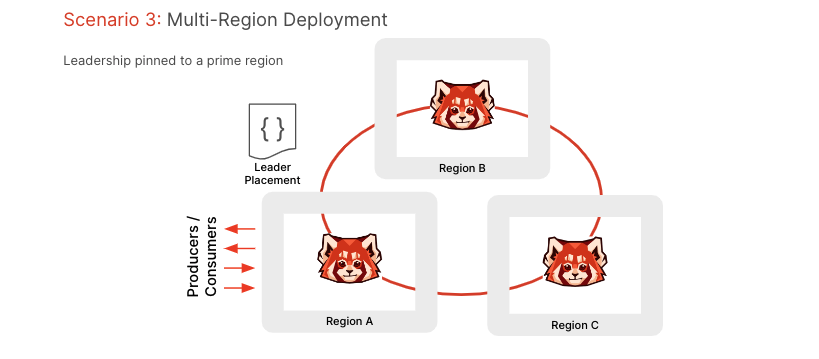
A multi-region deployment looks similar to a multi-AZ deployment, with the same condition that you would need at least three regions to counter the loss of a single region. In this deployment pattern, there are two options to retain produce and fetch latency (if these measures are important for your deployment).
The first option is to manually configure leadership of each partition to ensure that leaders are congregated on the primary region (i.e. closest to the producers and consumers). The second option is to configure producers to have acks=1, which introduces the possibility of losing messages in the event of the primary region being lost/unavailable for a period.
In a multi-cluster deployment, each cluster can still be configured according to one of the HA patterns above, but standby clusters (or read replica clusters) are available in one or more remote locations. Redpanda does not support synchronous replication and, therefore, one or more options for asynchronous replication are required:
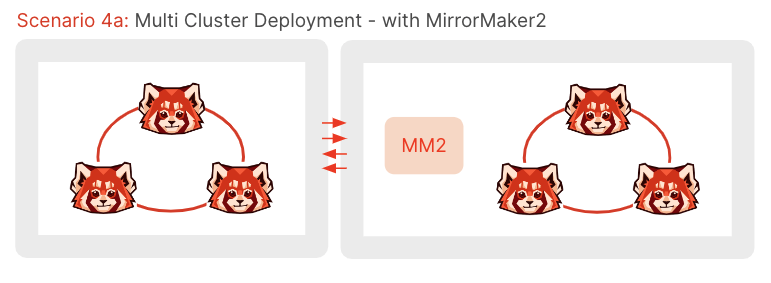
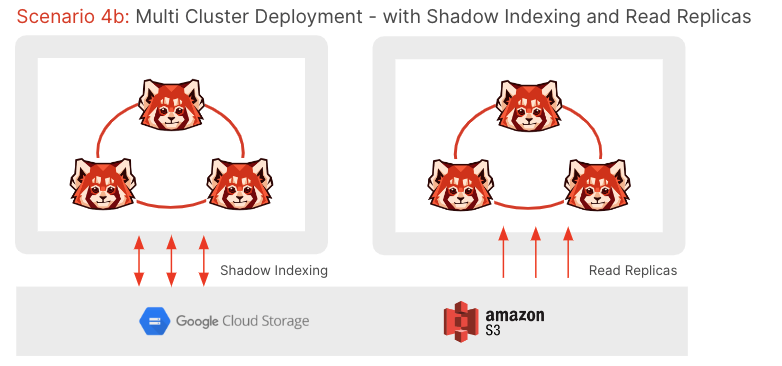
Another option is to dual-feed clusters in multiple regions. However, this puts additional complexity onto the producing application, and similarly requires consumers that have sufficient de-duplication logic built in to handle the fact that offsets won’t be the same across each cluster.
As covered in the section above, there are many ways to deploy a Redpanda cluster. Configuration of the broader system components (such as Kubernetes), as well as Redpanda itself, can differ greatly depending on which path you take.
Here are some important cluster characteristics to consider, regardless of the way you choose to deploy your cluster. We cover each of the following in more detail below:
A cluster’s availability is directly tied to replica synchronization. A cluster’s brokers can only be available for clients (consumers or producers) if the brokers are consistent with the leader. But what do the terms leader, replica, and consistent mean?
Brokers can be either leaders or replicas (i.e. followers) for a partition. The leader handles writing data to the log and determining which replica brokers are in-sync. The replicas receive messages that are written to the partition of the leader broker and send acknowledgments to the leader after successfully replicating the message to their internal partition. The leader then sends an acknowledgment to the producer of the message as determined by that producer’s acks value (see below for more details).
Apache Kafka® uses the concept of in-sync replicas, while Redpanda uses a quorum-based majority. This is because Redpanda uses the Raft replication protocol, while Kafka uses a different asynchronous replication implementation. What this means in practice is that Kafka performance will be negatively impacted while any replica is out-of-sync, but a Redpanda cluster will tolerate replica failures without any noticeable performance degradation. For more details see our blog post about availability footprints in Redpanda vs. Kafkalability.
One way to monitor the health of your cluster is through the command rpk cluster health, which will tell you how many (if any) nodes are down, as well as if you have any leaderless partitions.
Another thing to consider is that replicas can be either consistent or inconsistent. The leader of a cluster will consider a replica to be inconsistent if it fails to reply with an acknowledgment after the leader sends a message. It may be acceptable to have some inconsistent replicas in some cases.
For example, a topic could have enough partitions spread across brokers that one unresponsive broker would be acceptable. This is configured by setting min-insync.replicas to the number of replicas that must be in sync.
Rack awareness is one of the most important features for ensuring that your cluster remains available regardless of failures. This is because rack awareness enables Redpanda to spread partition replicas across available brokers in a way that avoids keeping those replicas in the same physical location.
Redpanda will determine where a replica is placed based on the following criteria:
Remember that location of these racks is up to the user, so you still must ensure that setting separate rack IDs actually leads to a physical separation of brokers. More details on how rack awareness works in Redpanda can be found in our documentation here.
Leader election is part of the Raft protocol, and it defines the process all brokers in a cluster follow to elect a new leader whenever the previous leader has become unresponsive for whatever reason. But what happens if the leader becomes unresponsive before the replicas have fully synchronized? This could result in an unclean leader election. This may be important to ensure availability of the cluster, but it would come at the expense of durability (potential loss of data). An alternative way to handle this scenario would be to not allow unclean leader election, which would instead lead to a cluster failure.
Deciding which approach is right for your system is something that needs to be determined based on your specific use case scenario. How important is your data? Can your clients handle minor outages? When deploying clusters for HA environments these are important questions to ask.
Producer acknowledgment defines how producer clients and broker leaders communicate their status while transferring data. There are three acks values that are used to determine both producer and broker behavior when writing data to the event bus:
acks=0: The producer will not wait for acknowledgments from the leader broker, and will not retry sending messages. This increases throughput and lowers latency of your system at the expense of durability.acks=1: The producer waits for an acknowledgment from the leader broker, but it doesn’t wait for the leader to get acknowledgments from replicas. This setting doesn’t prioritize throughput, latency, or durability. Instead, acks=1 attempts to provide a balance between these characteristics.acks=all: The producer receives an acknowledgment once the leader and all replicas acknowledge the message. This increases durability at the expense of lower throughput and increased latency.There are many more details to discuss about how Redpanda handles acknowledgments.
Automatic partition rebalance is enabled by default in Redpanda, which rebalances partitions across nodes in a cluster when a node becomes unresponsive. This is important so that topics continue to be available to clients regardless of node failures. This rebalancing can also be triggered when a new node is detected by setting enable_auto_rebalance_on_node_add to true.
You can monitor partition rebalancing through a few metrics created to increase visibility of the partition movement process:
vectorized_cluster_members_backend_queued_node_operations: Number of queued node operationsvectorized_cluster_controller_pending_partition_operations: Number of partitions with ongoing/requested operations (creation, move, deletion, update)vectorized_raft_configuration_change_in_progress: Indicates if current Raft group configuration is in joint state (i.e. configuration is being changed)The main consideration for HA storage is to choose a remote storage option over local storage. If a broker only has local storage and is running in a containerized environment like Kubernetes, all state will be lost for this broker once the pod is removed for whatever reason.
But there are other considerations for storage in a Redpanda system, such as ensuring you have enough space, the storage is as fast as possible, and also making use of an XFS filesystem. For more details on this, see this documentation.
Having a plan for how to recover from disasters is critical to successfully deploying an HA cluster. Once a disaster occurs, your HA cluster may still be available, but you will need to return to the state where redundancy can again save your cluster. The sooner this happens, the better.
Redpanda has a tiered storage architecture, which is responsible for backing up partitions to any S3-compatible location. Tiered Storage includes some other features listed below:
Tiered Storage can be enabled either for all topics, or per topic if needed. You can learn more about Tiered Storage solutions in our documentation here. You can also learn how we built Tiered Storage here.
As you can see, there’s a lot to consider when deploying Redpanda in an HA manner. This article is the first in a series dedicated to HA deployments. Part two will focus on deploying a cluster in a single AZ, and Part three will focus on multi-AZ and multi-region clusters.
There are a number of topics related to deploying an HA cluster that we haven't yet covered and, eventually, we plan to focus on each of them in future articles. Some of these topics are async replication and detailing a full disaster recovery process. In the meantime, join the Redpanda Community on Slack to ask your HA deployment questions, or to request coverage of other HA-related features.
You can't scale what you can't trust. A governance layer fixes that.

Your lakehouse mirrors the database, instantly.

What is it, why enterprises need it, and how to evaluate one
Subscribe to our VIP (very important panda) mailing list to pounce on the latest blogs, surprise announcements, and community events!
Opt out anytime.