





5 predictions about agentic AI and analytics in 2026
What AI trends will shape analytics in the coming months?
Redpanda is 6x more cost effective than Kafka for the same workload running on legacy platforms, while helping you reduce your hardware footprint.








Redpanda is designed for usability and simplicity, which contributes to a much lower administrative burden than Kafka. It features an Autotuner that auto-detects the optimum settings for your hardware and tunes itself to best take advantage of your specific deployment. It also has a leadership balancing feature that improves cluster performance by ensuring that leadership is spread amongst nodes.
In the comparison between Kafka and Redpanda, TCO is defined as a combination of infrastructure and administration costs. Infrastructure costs include the cost of computing and storage, in this case on AWS. Administration costs involve the cost of deploying, installing, and upkeep of clusters. The TCO is the blended cost of deploying, configuring, securing, productionizing, and operating the software over its expected lifetime, including all infrastructure, personnel, training, and subscription costs.
One of the major benefits of running Redpanda is the simplicity of deployment. Redpanda is deployed as a single binary with no external dependencies, which means there is no need for any infrastructure for ZooKeeper or for a Schema Registry. Redpanda also includes automatic partition and leader balancing capabilities, so there’s no need to run Cruise Control.
The performance benchmark report found that Redpanda’s average and P99+ end-to-end latency profiles remain incredibly consistent even at high throughputs. Kafka, on the other hand, could not handle workloads at 500 MB/sec or above with three nodes. The tests could not be completed at the required production rate. For smaller workloads, Redpanda was able to run slightly faster on the cheaper AWS Graviton (ARM) CPUs, whereas Kafka was unable to operate on these instance types at any level of performance.
The main cost components when setting up Kafka include infrastructure, management overhead, integration costs, and data transfer costs. Infrastructure covers servers, cloud resources, computing power, storage, and networking. Management overhead involves the day-to-day running of your Kafka setup, including managing Kafka clusters and performance monitoring. Integration costs are incurred when integrating Kafka with other systems or apps, which might require additional tools and tech. Data transfer costs are associated with moving data in and out of your Kafka system, especially in a cloud setup.
We will define a cost model, test the physical characteristics of both systems using representative configurations, including security and disaster recovery (DR), and then evaluate the administrative costs for both systems.
When you're looking into setting up Kafka, there are a few expenses you'll want to keep in mind.
First, there's the infrastructure, which is usually the heftiest chunk of the budget. It covers everything from the servers and cloud resources you'll need to get your Kafka clusters up and running, to computing power, storage, and networking.
Then, there's the management overhead. This is all about the day-to-day running of your Kafka setup, from management of Kafka clusters to performance monitoring. Also, If you're interested in a managed Kafka service from a cloud provider, remember that there’s typically a licensing/subscription fee involved. The price can vary depending on which vendor you choose.
Next, we need to consider integration costs. Integrating Kafka with other systems or apps might need some extra tools and tech, which means more spending on software and possibly even more developer time.
Lastly, think about the data transfer costs. Moving data in and out of your Kafka system, especially in a cloud setup, might bring additional charges depending on the volume of data that's being transferred. So, if you want to make sure there aren’t any surprises down the road, understanding these costs can help when planning and budgeting for Kafka.
In this post, we explore the overall costs of running both an Apache Kafka® and a Redpanda cluster for real-world data streaming use cases and throughputs in a self-hosted deployment model.
In this economic climate costs are top of mind for everyone. Total Cost of Ownership (TCO) should be a primary consideration when evaluating the Return on Investment (ROI) of adopting a new software platform. TCO is the blended cost of deploying, configuring, securing, productionizing, and operating the software over its expected lifetime, including all infrastructure, personnel, training, and subscription costs.
For this comparison, we define TCO as a combination of the following components:
For the infrastructure cost comparison, we ran benchmarks to compare the performance of Kafka against Redpanda. By establishing infrastructure profiles with broadly similar performance characteristics, we were then able to calculate the cost differential between the two platforms.
{{featured-report="/components"}}
We ran over 200 hours of tests across small, medium, and large workloads to generate a performance profile for Apache Kafka and Redpanda.
When running our performance tests we were looking for low and predictable end-to-end latency. We adjusted the node counts to ensure that latency remains relatively stable (i.e. The system is not overloaded, even at high throughput).
The results from our performance benchmark report highlighted the following:
To build our cost model, we needed to size our Redpanda and Kafka clusters to achieve comparable performance characteristics, our target being for P99.9ms latency to be less than 20ms. Our performance testing suggested the following sizing needs (even though we were required to scale Kafka to up to 3x the number of nodes as Redpanda to even get within 20x the latency in some cases.)

One of the major benefits of running Redpanda is the simplicity of deployment. Because Redpanda is deployed as a single binary with no external dependencies, we do not need any infrastructure for ZooKeeper or for a Schema Registry. Redpanda also includes automatic partition and leader balancing capabilities, so there’s no need to run Cruise Control.
In the cost model below, we show the infrastructure costs for running Redpanda across the following:
This includes the number of brokers needed to run the workload itself and, for Kafka, instances to run Cruise Control, Schema Registry (two nodes for high availability), and ZooKeeper (three nodes).
Note: Apache Kafka added support for KRaft as a replacement for ZooKeeper in the 3.3 release; however, it is not yet feature-complete. We expect it to be a while before this feature is widely adopted and have not factored KRaft into our cost model.
For the small workload, we noticed that Redpanda and Kafka had a similar performance profile running on i3en.xlarge instances whereas Redpanda was able to show performance gains against Kafka on the smaller i3en.large instances.
We did note, however, that we couldn’t fully use the i3en.large machines, simply because the workload wasn’t large enough. By introducing AWS Graviton (ARM-based) instances, we improved the performance of Redpanda at a significantly lower cost point. As discussed in more detail in the Kafka vs. Redpanda performance blog, Kafka was unable to run on the Graviton instances.
The cost comparison in this table compares Kafka running on i3en.xlarge against Redpanda running on is4gen.medium instances.
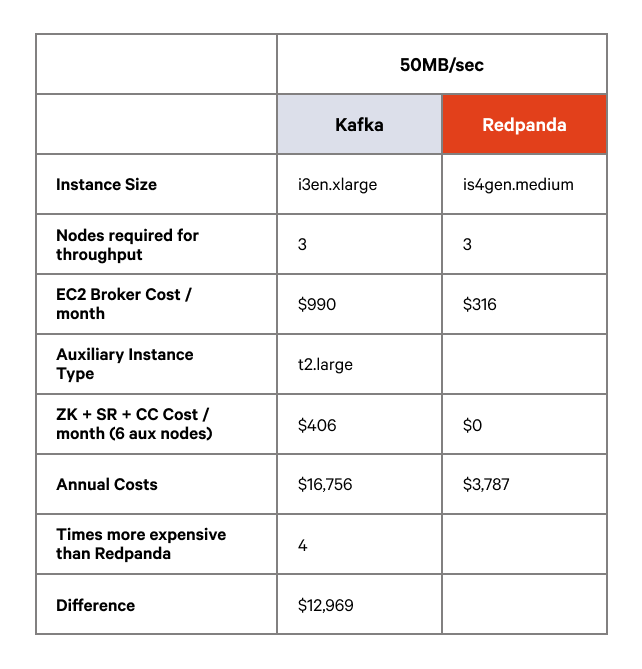
Compared to running Redpanda on AWS Graviton instances, Kafka comes in at 3-4 times more expensive. Performance on the i3en.large instances for Kafka was not as good as Kafka on i3en.xlarge nor Redpanda on the same hardware or Graviton. Annual cost savings of up to $12,969 are available by using Redpanda for this workload.
We saw similar results for the medium and large workloads – on identical hardware configurations (three nodes) Kafka was unable to complete the workload at the required throughput so we were required to add nodes to try and get comparable results. In order for tail latency to be within a tolerance of 3x Redpanda’s for the medium and large workloads, we needed to scale Kafka up to nine nodes, which has a significant infrastructure cost impact.
The following tables compare Redpanda and Kafka with the requisite number of nodes to sustain the throughput at reasonable latency thresholds. All of these tests ran on i3en hardware.
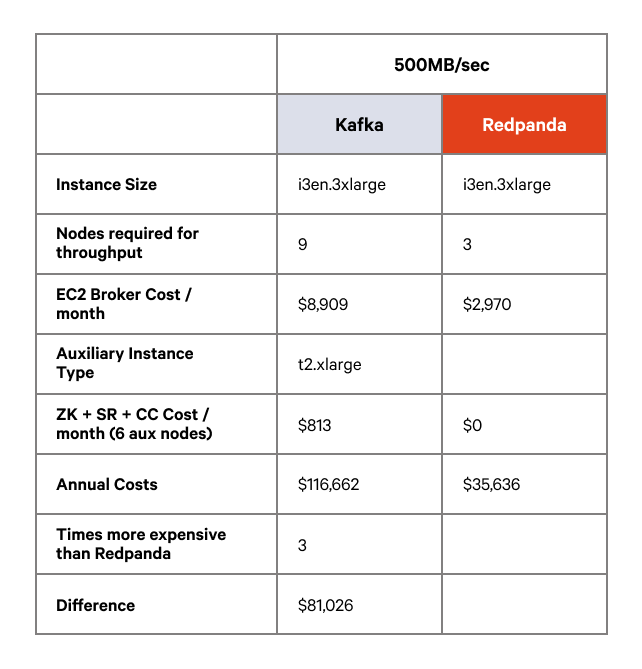
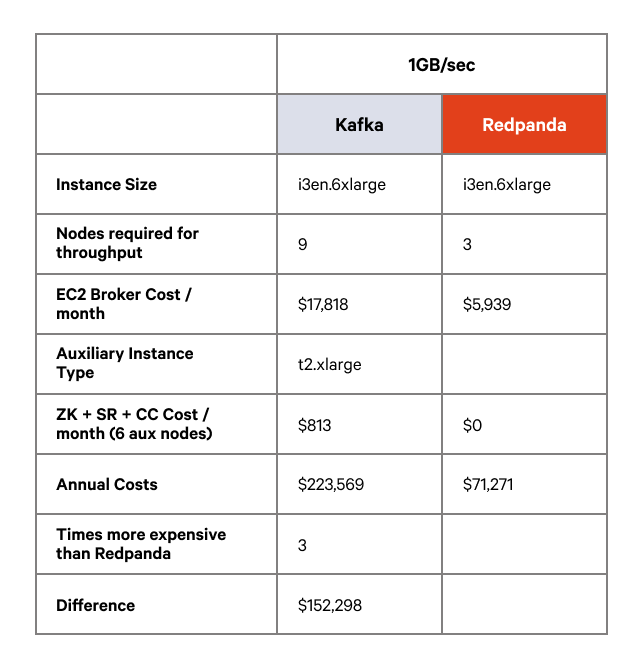
On infrastructure costs alone you can expect to see cost savings of between $80K and $150K depending on the size and scale of your workload, which can represent a 3x cost saving against Kafka.
Redpanda is designed first and foremost for usability and simplicity (along with record-breaking performance). The following Redpanda features all contribute to a much lower administrative burden than Kafka:
Redpanda is also designed with data safety in mind as highlighted in the report from Jepsen. Improved data safety significantly reduces the operations and management overhead of running a Redpanda cluster and therefore reduces costs in this area.
[CTA_MODULE]
The report highlights the key design differences between Redpanda and Kafka, specifically around weaknesses in Kafka’s ISR mechanism that can lead to data loss or unsafe leader election. Redpanda has no such weakness and is much more stable under failure scenarios, including benefiting from having a single fault domain (compared to Kafka having ISR and ZooKeeper/KRaft as fault domains).
To build indicative cost comparisons for Redpanda against Kafka, we worked with what our customers told us. Since Redpanda skips the need for JVM or ZooKeeper, customers affirmed they spend less time balancing partitions, tuning the JVM, ZooKeeper, and operating systems, as well as recovering from outages caused by ISR problems.
That said, we’ve made the following assumptions based on direct customer feedback:
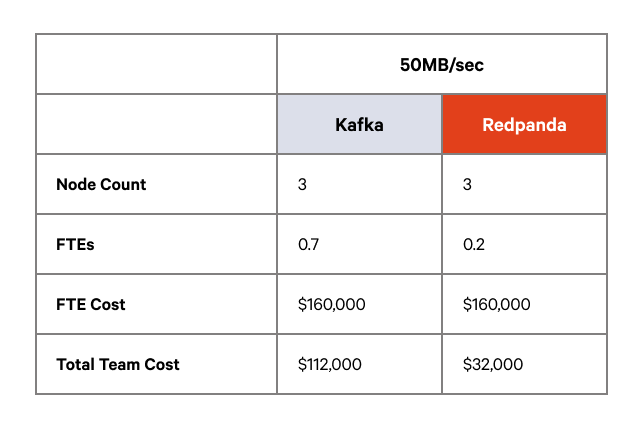
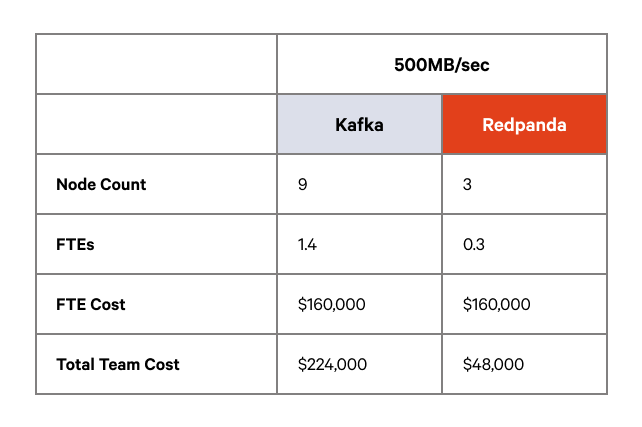

In the consolidated cost model, we bring together the costs of hosting the primary cluster infrastructure and administration costs as specified above. In this model, we do not include the cost of any DR site, or associated data transfer costs, although it’s a fair extrapolation to say that infrastructure costs alone will at least double, with the additional infrastructure required to host a MirrorMaker2 cluster on Kafka Connect (although for Redpanda Enterprise it is possible to use S3 replication - for further details see our blog on HA deployment patterns).
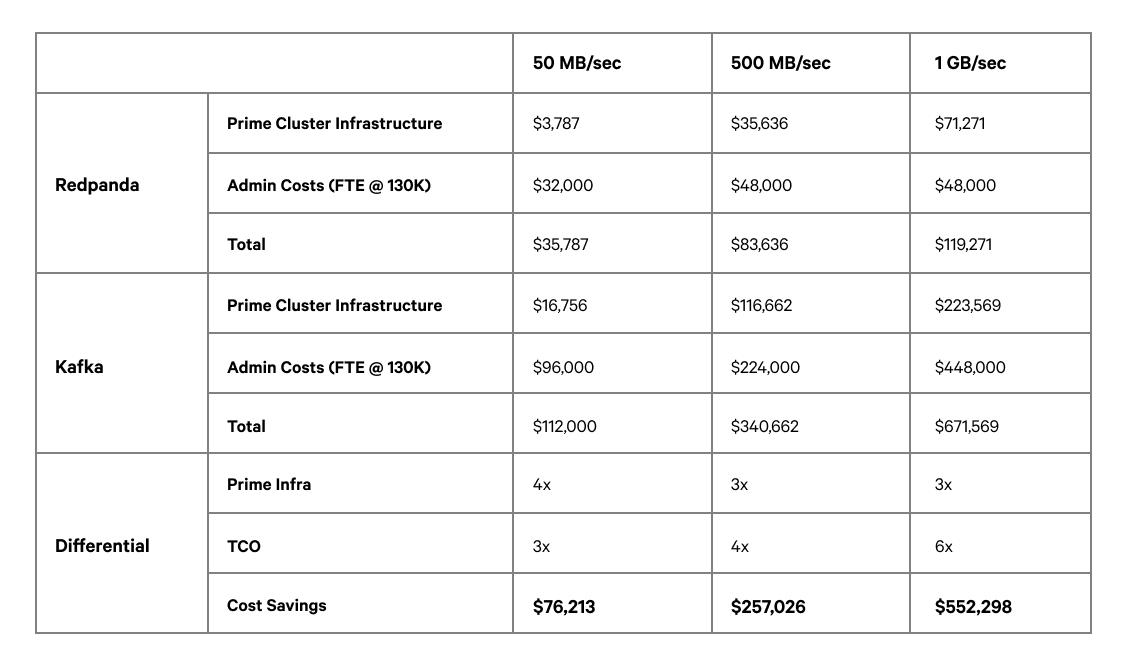
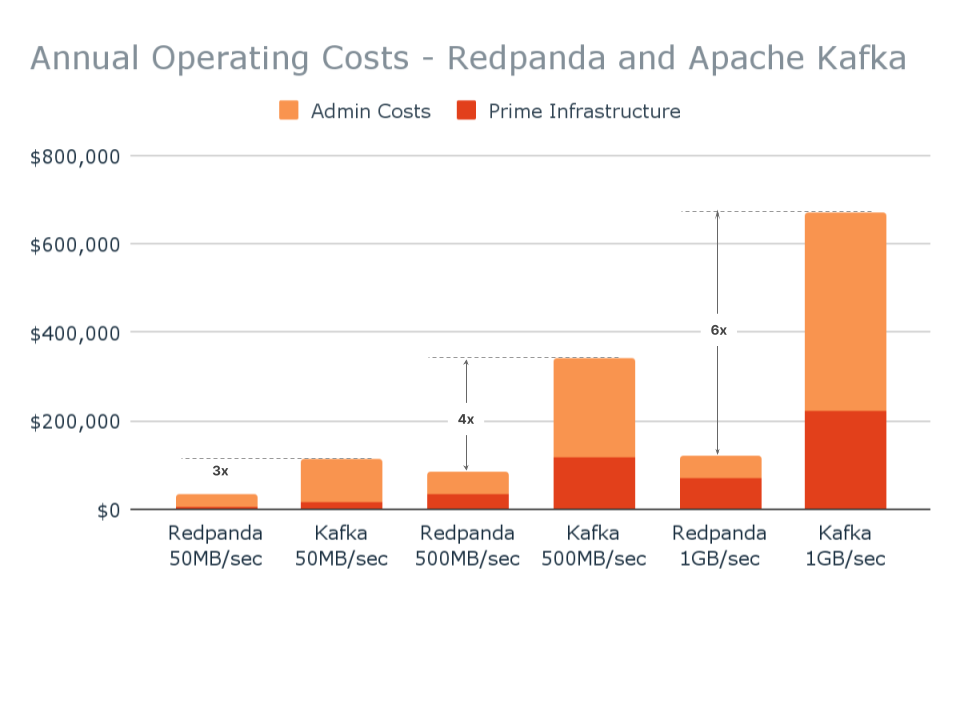
All of the prices above compare Kafka with the Redpanda Community edition. According to this model, savings in infrastructure and administrative costs can range from $76K for a small workload to $552K for large workloads, a multiplier of 6x.
Redpanda Enterprise includes several features that can be leveraged to further reduce the TCO of a Redpanda cluster – even when compared against commercial Kafka offerings, including Redpanda Console and Redpanda’s tiered-storage capability.
Redpanda’s Tiered Storage capability works by asynchronously publishing closed log segments into an S3 compatible object store such as AWS S3, GCS, Ceph, MinIO, or a physical device such as Dell ECS, PureStorage, or NetApp ONTAP.
Redpanda’s Tiered Storage provides two additional features:
Kafka is working on tiered storage under KIP-405—but this has been ongoing for over two years. Some commercial vendors do have support for proprietary tiered storage offerings. Still, these solutions do not offer read-only replicas, nor the ability to rebuild a cluster in a DR scenario. So, if Kafka is to be used in a DR active/passive topology, an additional Kafka Connect and MirrorMaker cluster would be required.
The largest cost saving is when sizing a cluster to have more than the amount of data retention that would otherwise be available on the provided disk at the throughput required.
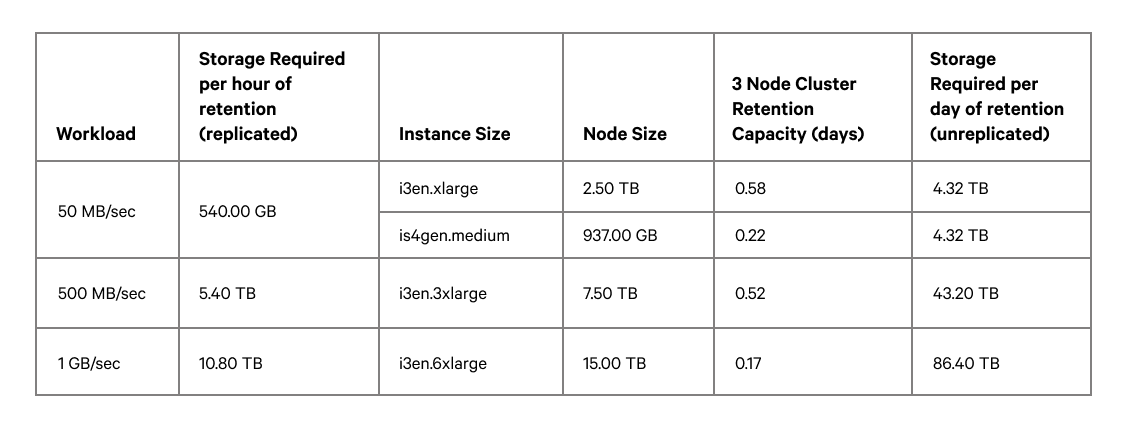
Because S3 storage is significantly cheaper than SSD/NVMe-based instances it is advantageous to use tiered storage both to reduce cloud or infrastructure costs, but also to reduce the operational complexity of running a large Kafka cluster that is sized simply for retention.
The following tables provide an illustrative comparison of running Redpanda Enterprise, Commercial Kafka (including tiered storage, noting the limitations above and that the Kafka cluster needs to be larger anyway for throughput), and both Redpanda Community and Kafka without tiered storage available.
For each workload, we evaluate the potential infrastructure cost that would be incurred at one-, two-, and three-days’ worth of retention, with the relative comparison to running Redpanda Enterprise with tiered storage enabled. This calculation gives us the cost savings of Redpanda tiered storage over its open-source comparators.
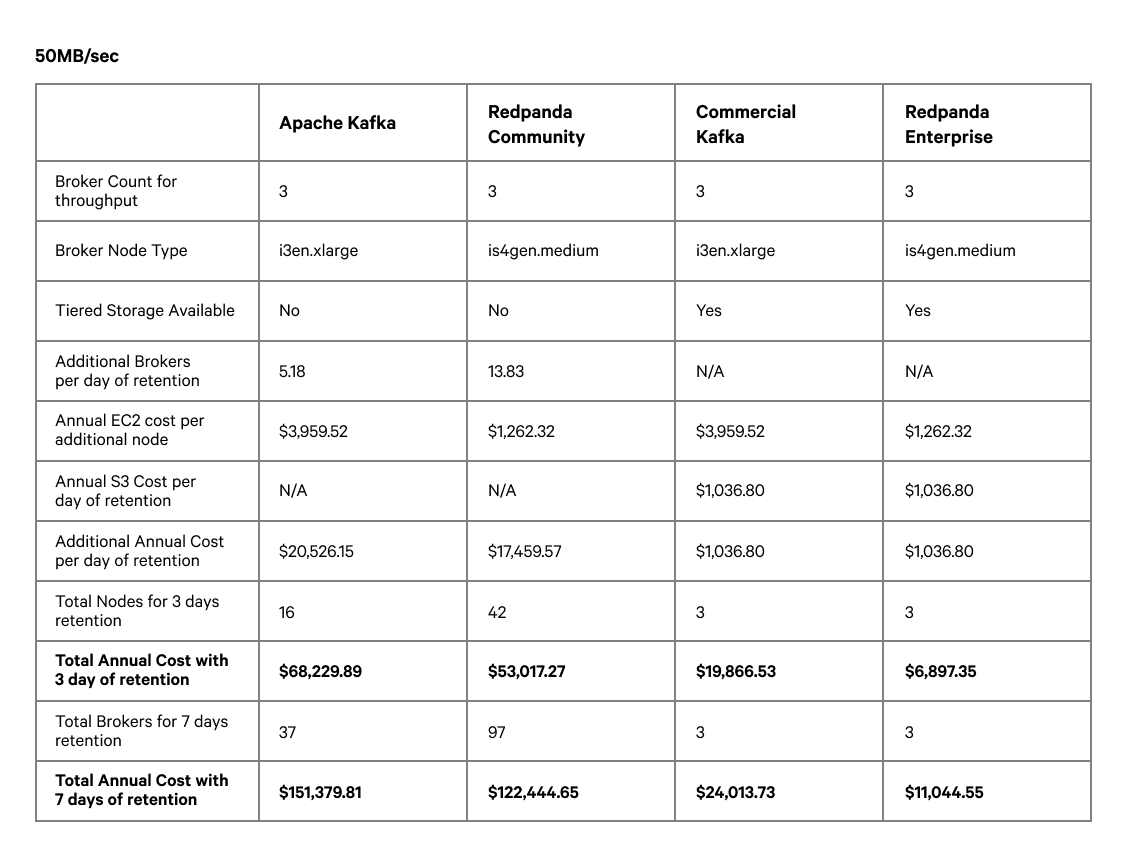
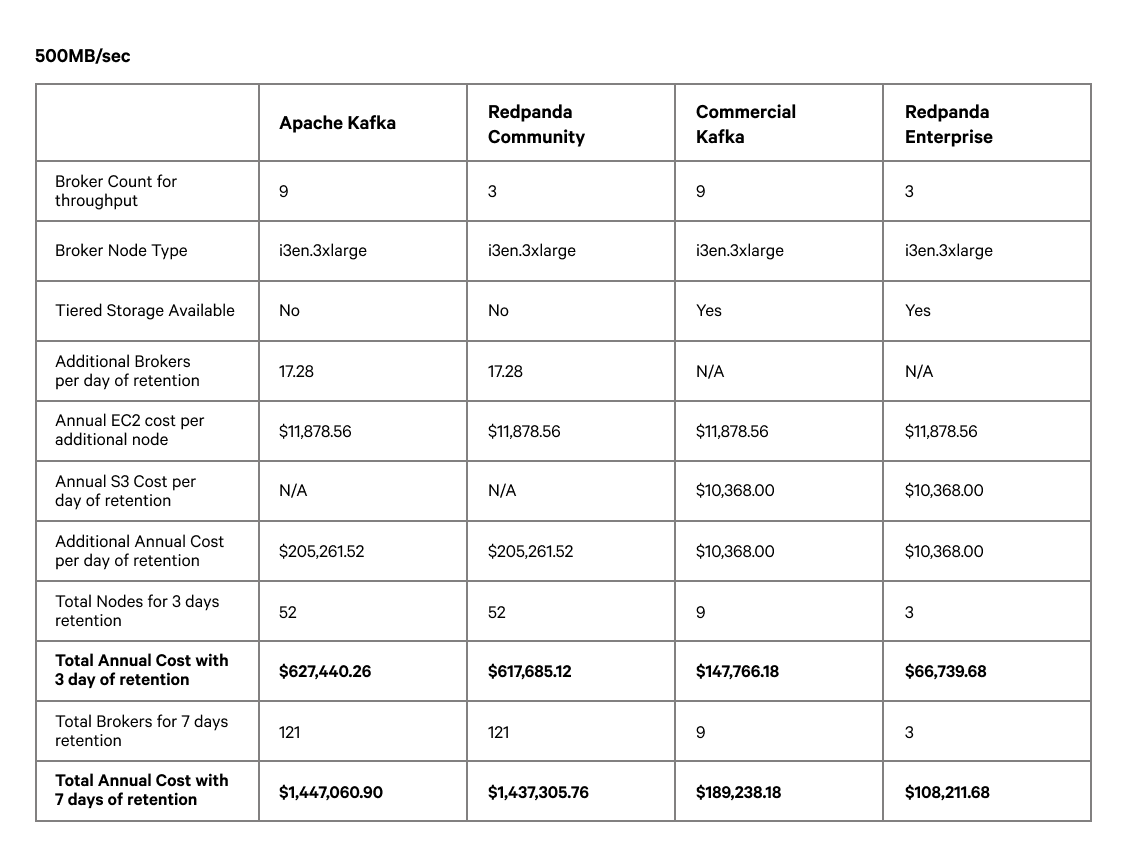

In the tables above we can see that the incremental retention costs on clusters without tiered storage can be quite significant. The table below summarizes the results across all of the workloads:

We can see that the cost savings of an enterprise subscription can range from $70K up to $1.2M or higher for bigger workloads or retention requirements. That does not account for the indirect cost savings of Redpanda Enterprise features, such as Redpanda Console with SSO and RBAC, remote read replicas, continuous data balancing, and hot-patching.
When it comes to managing costs in Kafka, automated tools that remove the need for manual oversight by providing real-time monitoring and predictive analytics are becoming more popular. By making it easier to identify errors and establish scalable foundations, these tools can make it easier to forecast and manage costs while also simplifying operations.
Serverless configurations are also gaining traction. They offer a pay-as-you-go model which lowers barriers of entry for smaller projects or companies. Platforms are gradually embracing serverless configurations and automated tools to reduce complexity and lower total cost of ownership.
Additionally, integration technologies are expected to improve, meaning we'll likely see more streamlined, cost-effective integration solutions emerging. Redpanda serverless is already jumping on this trend with integrated capabilities that eliminate dependencies like Zookeeper, helping to reduce costs and administrative overhead.
[CTA_MODULE]
In this post, we compared the TCO of running Kafka and Redpanda based on benchmarking that we have carried out on public cloud infrastructure. Here are our main findings:
The bottom line is: Redpanda is up to 6x more cost-effective to operate than Kafka, and Redpanda’s flexible deployment options mean that it’s simple to deploy both in Redpanda’s cloud, across your own cloud environment or self-managed on-premise, bare metal, or Kubernetes.
Interested in trying it for yourself? Take Redpanda’s free Community edition for a spin! Make sure to check our documentation to understand the nuts and bolts of the platform, and browse the Redpanda blog to learn all the cool ways you can integrate Redpanda.
If you have questions or just want to chat with our architects, engineers, and other Redpanda users, join the Redpanda Community on Slack.
What AI trends will shape analytics in the coming months?

Benchmark shows Vera provides 5.5x lower latencies and up to 73% higher throughputs than other leading CPU models

Learn from the leaders actually shipping and scaling AI agents today
Subscribe to our VIP (very important panda) mailing list to pounce on the latest blogs, surprise announcements, and community events!
Opt out anytime.