





What is an Agentic Data Plane?
What is it, why enterprises need it, and how to evaluate one
When to choose Redpanda over Apache Kafka.








I started Redpanda in 2019 out of personal experience wanting a simpler, faster, cost effective system that didn’t lose data. This was the napkin sketch. Being an engineer is very freeing in that you don’t have to ask for permission, simply open Emacs and start materializing your ideas.
To be clear, this blog is a response to Confluent’s Field CTO, Kai Waehner, on a blog titled “When to choose Redpanda instead of Apache Kafka®.” For the impatient, every single technical point is in the Appendix.
It bears repeating, I think extremely highly of the engineers, hackers, and doers that actually write and maintain the Apache Kafka code. I was inspired by all of you.
Some will always see the world in black and white. I see the world greenfield (see references 1-12), where multiple companies can innovate and push each other’s products into design space dimensions that would be hard without competition, just like LLVM pushed GCC or Rust pushed the safety of the C++ type system. Whether it is pushing the safety properties of clients acks=ALL, or improving the local-dev container startup experience, together we make real-time streaming simpler for developers and in turn get to change how the world builds applications with streaming as default.
What the engineer cares about, however, is her application working end-to-end. End users do not care about foo, bar, baz, or the color of the bike-shed, they care about their untouched code going faster, with fewer resources and lower costs, and that’s ultimately the promise of Redpanda.
Classically, real-time streaming has not been easy. To the engineer, it still feels like distributed systems whack-a-mole with 4 or 5 systems to manage. This is still true when choosing a SaaS vendor, the axes simply shift. When building systems, one cannot eliminate essential complexity, only move it around. In particular when the data volume is high, the cost-dominant structure of cloud is network traffic, latency between your applications and the closeness of the storage engine and for some, the sovereignty of owning the hard-drive lifecycle where your customer data resides.
In this post I focus on our fully managed BYOC (Bring Your Own Cloud) offering to demystify what it is and share design tradeoffs after working with some of our larger F500 customers for the past 2 years as we co-designed our cloud. For the uninitiated, yes it is production ready, SOC2 compliant with managed connectors and VPC peering.
Data sovereignty is much harder to achieve than data privacy. Privacy can be achieved with policy: delete this, mask that, obfuscate here, index like so. Sovereignty can only be achieved if you, the user, control the hard drive lifecycle where data resides. There are no two ways about it. Data either lives inside the hard drives that you control or it does not.
Immutability is streaming’s strongest property and is also its achilles heel for classical vendors. Unlike other systems like databases, traffic on streaming systems is often 10 or 100 times larger in throughput. It is very common to have a 10-to-1 reduction in databases from writes to reads, while the opposite is common for streaming systems like Redpanda, where we see in practice 10 to 100 times more reads compared to writes.
Replayability, immutability, and separating producers from consumers is ultimately the value that Redpanda or Kafka bring to the developers. If you produce data with the right schema, something else will pick it up sometime in the future. Your data is the only contract.
We invented Redpanda’s BYOC to fix data sovereignty problems. Let there be no mistake about this, companies don’t offer BYOC not because of the technical ability of their teams but because reselling AWS infrastructure artificially inflates revenue. We choose to lean into the future of how companies want to consume the data.
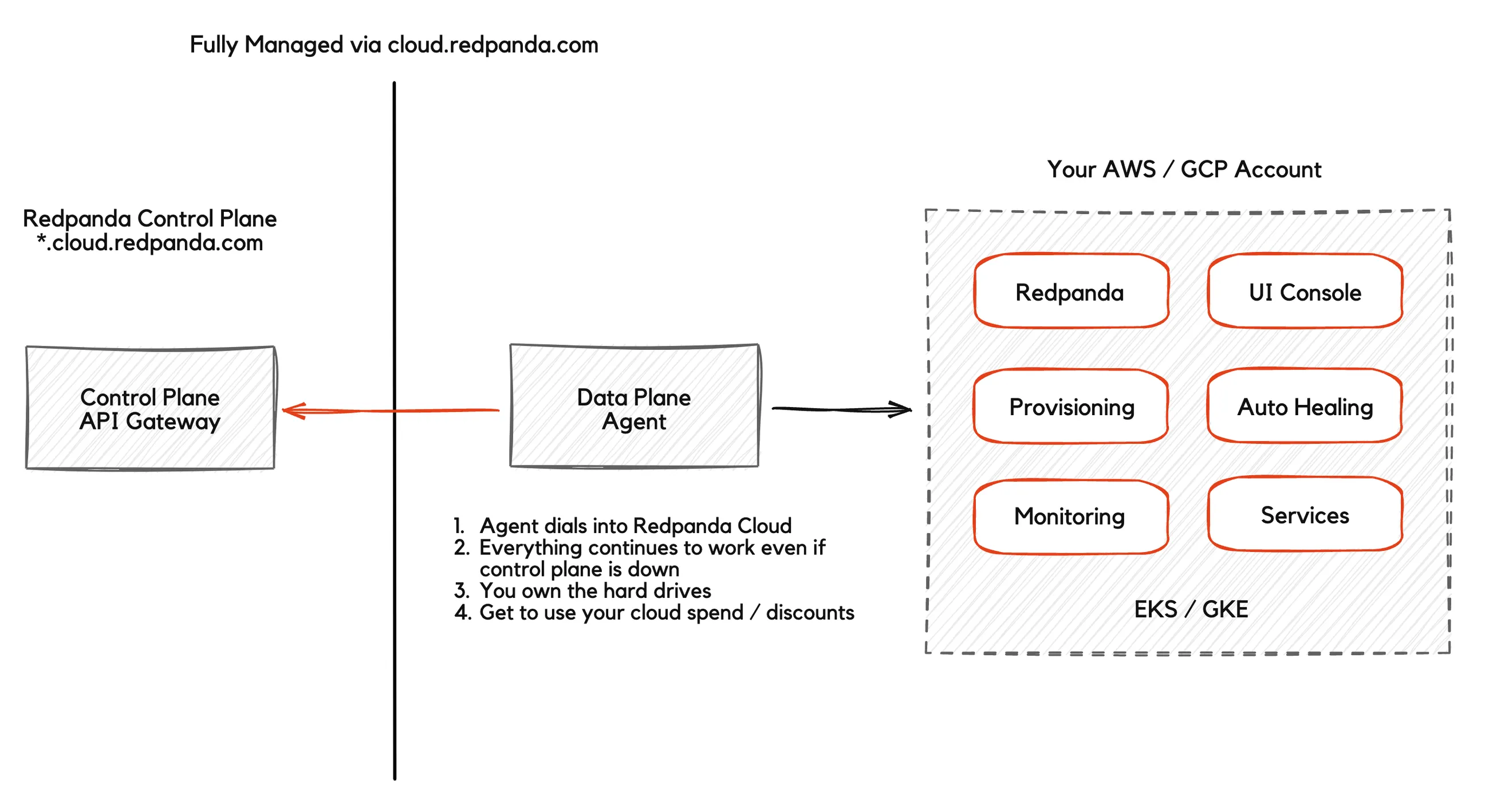
At a high level, the data-plane agent dials into our control plane. The agent is a stateless service that listens for an exhaustive list of commands with a complete list of permissions we provide our customers during the security audit. Something has to watch the watchman. The agent is not deployed inside kubernetes, instead it relies on AWS|GCP autoscaling groups. If it crashes, a new image is started with a clean VM and with no interruption of data-plane Redpanda services.
For completeness, Redpanda provides additional Dedicated single-tenant services similar to other SaaS vendors, with an upcoming Serverless offering. But in this post we’re talking about how the future should work for the most demanding workloads. We note that all deployments use the exact same architecture.
One of the nicest things about Redpanda is the fast response times when interacting with data. We spent 2 years and a full cloud re-write until we nailed the user experience. Fundamentally, your browser makes 2 TCP connections, one to the control plane and one to the data plane. This happens after some auto-negotiation and discovery so that ultimately, you can still filter, aggregate, view, explore, send and otherwise slice and dice your streaming data with our UI without Redpanda’s Control Plane ever seeing any of the actual data.
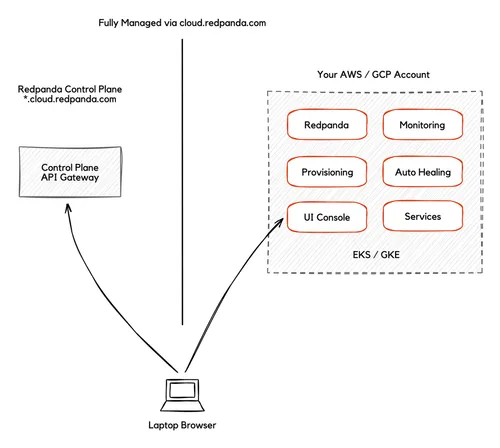
We use a technology called module federation, which allows us to ship fully functioning, versioned, micro-ui’s to the data-plane attached to the specific functionality to the installed software bill of materials. In other words - the future - fast, reliable, preserves your privacy and allows users to maintain data sovereignty. Meanwhile, your end users only observe that it works “faster,” especially for filtering, aggregations, etc. as you are not paying WAN network costs between Redpanda and your apps.
One thing is certain, there is no substitute for git clone[14] and seeing for yourself on your terminal, with your target workload - this is how engineering is done. We wrote step-by-step instructions[15] on how to run the original Open Messaging Benchmark and reproduce results, but most importantly tweak it to run your target workloads so you understand the tail latency, throughput and scalability bottlenecks of Redpanda or Apache Kafka or any other vendor.
To experience a fully managed Bring-Your-Own-Cloud (BYOC) where you retain sovereignty, privacy, lower latency and costs, get started here.
Below is a list of factual edits, nitpicks, boring but complete rebuttal to the technical points. They are in bullet list form so you may refer to them in the future.

What is it, why enterprises need it, and how to evaluate one

Enterprise agents need governance infrastructure, not just better models

What AI trends will shape analytics in the coming months?
Subscribe to our VIP (very important panda) mailing list to pounce on the latest blogs, surprise announcements, and community events!
Opt out anytime.