




Bridge Queries in Redpanda SQL
Have your real-time cake and eat your analytics too
Learn how to connect MySQL and Debezium for real-time change data capture use cases.









Change data capture (CDC) is a design pattern implemented to audit any changes in a database. It can be audited and tracked, whether it's a data change or schema change. This audited data can then inform actions to be taken by the listening or processing application.
Many database technologies support CDC as an out-of-the-box feature. These include MySQL, PostgreSQL, SQL Server, Oracle, DB2, Cassandra, MongoDB, and so on. This article focuses on CDC in the MySQL database, which captures changes made in real time via the “binlog” change log functionality. The changes then pass through Debezium, Kafka ConnectⓇ, and Redpanda, enabling the downstream services and analytical dashboards to data that has been changed, as it happens.
The following are some of the use cases of CDC in MySQL-based applications. Debezium is responsible for capturing and sending the following examples to Redpanda:
A strong understanding of CDC and how to use CDC data as part of a real-time data pipeline system can make your life easier in several ways.
For example, CDC-based data processing does not put much load on the systems involved because it's on an event basis. So you can save time and effort when dealing with performance issues.
Additionally, CDC provides a simple solution for hard-delete scenarios because each deleted event is tracked and can be easily addressed within the data-processing pipeline. Many organizations are building real-time data pipelines to get better operational insights and data visibility, including some of the most influential global companies. Learning CDC-based technologies can improve your skill set and give you valuable industry knowledge.
This article will help you to understand the following:
To fully understand the value of CDC in MySQL, you must be aware of how data pipelines were built before CDC. Conventional data pipelines (without CDC) were built based on extracting data from MySQL databases in terms of a pull-based mechanism using SQLs and traditional ETL tools.
This data extraction method typically happens at scheduled intervals and hence, does not facilitate real-time data processing or visibility in analytical dashboards. Additionally, this approach directly impacts the source transactional database's performance and isn't able to track scenarios where data is hard deleted in the source application.
CDC in MySQL is considered as an alternative approach to overcome these inefficiencies and disadvantages. With CDC-based data pipelines, you can stream and process data in real time, which is useful in several applications.
For example, consider an e-commerce application where you want to track changes to users' payment methods in real time. You can use the binlog process to track any data manipulation language (DML) changes in the payment_method table in the MySQL database. The tracked data can then be read by Debezium, an open-source platform with distributed processing capability, well known for its application in the CDC space.
Debezium facilitates CDC for any database changes and produces a message into Redpanda/Apache KafkaⓇ for each change, and it is run in the Kafka Connect infrastructure, an open source data integration framework, facilitating connecting Kafka with other data sources or data targets, including data streams from MySQL to Debezium, without needing to develop and maintain code for that purpose.
This section provides step-by-step instructions on implementing Redpanda with Debezium and MySQL for CDC. Redpanda is used in this stack as it offers a single binary or image with built-in components required for streaming use cases. It is also API-compatible with Kafka, meaning it works natively with existing Kafka tools, thereby eliminating the need to learn new tools.
The source code for this project is available in this GitHub repository.
The goal of this sample project is to set up all the dependent software, to enable CDC in the MySQL database, and to extract CDC data from the MySQL database in a sample table named payment_method through the Debezium MySQL connector. You will then push the extracted CDC data to Redpanda using Kafka Connect.
You will need the following prerequisites to follow these instructions:
The repo's Docker Compose file, mysql-debezium-connect-redpanda.yml, contains the relevant instructions for the list of images to be pulled and other settings that need to be configured for the container environment. A brief overview of this YML file is given below.
There are three services in the file:
All these services are defined with a corresponding image to be pulled and a container name. Note the container names for each service as you will use these names to connect the corresponding Docker container terminal to perform certain actions.
As usual, all these services are set with a restart strategy, so when there is a failure, the service is automatically restarted by the Docker engine. Based on the services, the corresponding environment variables that are required to be set are specified in place.
Note the username and password defined as part of the mysql service definition. This is required for you to interact with the database at a later stage.
mysql:
image: mysql:8.0
container_name: mysql
restart: always
environment:
- MYSQL_ROOT_PASSWORD=redpanda
- MYSQL_USER=redpanda
- MYSQL_PASSWORD=redpanda
ports:
- '3306:3306'
volumes:
- db:/var/lib/mysql
- ./mysql-scripts/init.sql:/docker-entrypoint-initdb.d/init.sqlAn initialization script, init.sql, has also been defined to execute MySQL commands at the time of service initialization. As part of this initialization script, a sample database named redpanda, a table named payment_method, and some sample data for this table are auto-created.
The database user, redpanda, which was created as part of the Docker Compose definition file, is also granted all of the necessary privileges in the redpanda database along with the privileges to read CDC data. You can refer to the SQL script file named init.sql from the project directory, mysql-scripts.
For the most up-to-date instructions on setting up Redpanda, please check the official documentation.
As part of this sample project, the CDC data from the payment_method table will get pushed to the Redpanda topic using the Debezium–MySQL connector. Note that each change made in the database will be registered as an event in the topic. You will see this in action at the final stage of the tutorial.
The kafka-connect service definition uses Debezium's official Docker image to pull the Kafka Connect image. Following is the YML code snippet of kafka-connect service:
kafka-connect:
image: confluentinc/cp-kafka-connect:7.2.0
container_name: kafka-connect-debezium-mysql
depends_on:
- redpanda
- mysql
restart: always
ports:
- "8083:8083"
environment:
CONNECT_BOOTSTRAP_SERVERS: "redpanda:9092"
CONNECT_REST_ADVERTISED_HOST_NAME: kafka-connect
CONNECT_GROUP_ID: "mysql-deb-kc-rp"
CONNECT_CONFIG_STORAGE_TOPIC: "redpanda.configs"
CONNECT_OFFSET_STORAGE_TOPIC: "redpanda.offset"
CONNECT_STATUS_STORAGE_TOPIC: "redpanda.status"
CONNECT_CONFIG_STORAGE_REPLICATION_FACTOR: "1"
CONNECT_OFFSET_STORAGE_REPLICATION_FACTOR: "1"
CONNECT_STATUS_STORAGE_REPLICATION_FACTOR: "1"
CONNECT_PLUGIN_PATH: /data/connect-jars
KEY_CONVERTER: org.apache.kafka.connect.storage.StringConverter
VALUE_CONVERTER: org.apache.kafka.connect.storage.StringConverter
CONNECT_KEY_CONVERTER_SCHEMA_REGISTRY_URL: http://redpanda:8081
CONNECT_VALUE_CONVERTER_SCHEMA_REGISTRY_URL: http://redpanda:8081
PLUGIN_PATH: /data/connect-jars
volumes:
- ./data:/data/connect-jarsThe following are some of the key points from the above kafka-connect service code snippet:
kafka-connect service listens on port 8083 for the incoming requests. This port will be used for configuring the Kafka Connect/Debezium to MySQL connector.CONNECT_CONFIG_STORAGE_TOPIC, CONNECT_OFFSET_STORAGE_TOPIC, and so on. The main purpose of these environment variables is managing the internal operations of Kafka Connect, which are compacted topics that work seamlessly with RedpandaCONNECT_PLUGIN_PATH variable points to the path from which to load Debezium's connector libraries. I have included these libraries (Debezium–MySQL connector libraries) as part of the project's data directory. A volume mount is defined in the kafka-connect service to mount the libraries in the data directory to the container's /data/connect-jars directory.The KEY_CONVERTER and the VALUE_CONVERTER, are used to specify how you'll be formatting the data. You're going to use a simple StringConverter. There are also other types you could use, such as the AvroConverter; however, using the AvroConverter would require that you serialize the data in your application code to be able to read it by casting it into Json format. The AvroConverter would be helpful if you wanted to auto create the schema, but the data that you'll consume won’t be readable in the console. So, for this tutorial you'll use the StringConverter and then create the Schemas using curl commands.
The CONNECT_KEY_CONVERTER_SCHEMA_REGISTRY_URL and CONNECT_VALUE_CONVERTER_SCHEMA_REGISTRY_URL are used to point to the schema registry. As you're using Redpanda, the schema registry comes within the Redpanda container, and there's no need to create a separate container to handle it. You'll learn more about schema registry later in this tutorial.
You can refer to the Kafka Connect documentation for more details on Kafka Connect environment variables.
Next, open a terminal and execute the following command to start setting up your machine with the required software:
docker-compose -f mysql-debezium-connect-redpanda.yml up -d
Open the Docker Desktop application on your machine, and click on the Container/Apps option in the left-side menu bar. You should be able to see that all three containers are up and running as shown in the following image:
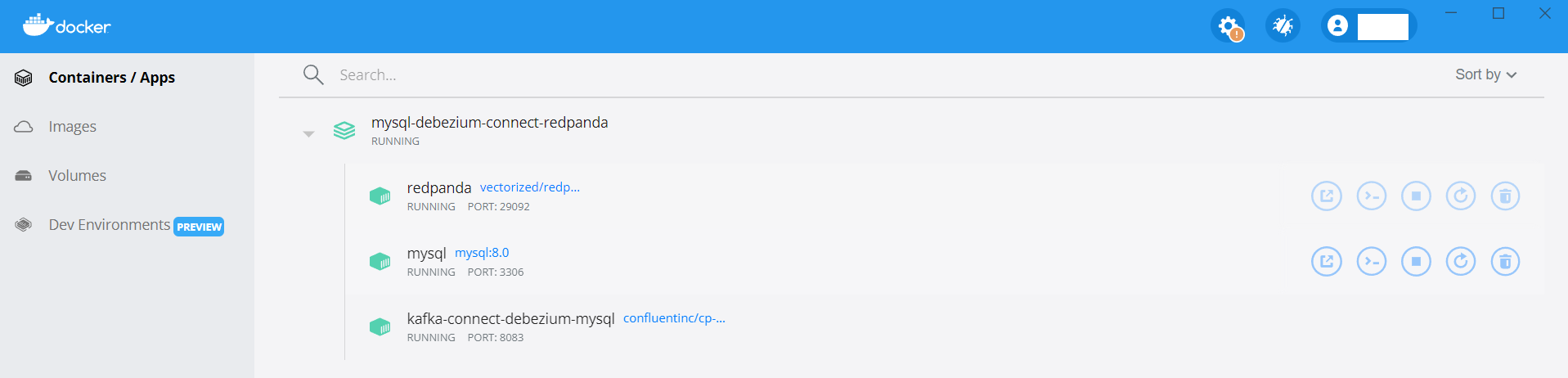
You can also execute the command docker ps to check the status of these containers.
Next, log in to the terminal of redpanda container by executing the command docker exec -it redpanda bash.
You need to be in this container terminal to interact with Redpanda's CLI called rpk. Use the following commands to enable automatic topic-creation configuration, which is required to automatically create the topics in Redpanda, including Kafka Connect's metadata topics and the topic to receive CDC events data:
rpk cluster config set auto_create_topics_enabled true
rpk cluster config get auto_create_topics_enabledThe first command enables the configuration, and the second verifies if the configuration is enabled.
Open another terminal and log in to the kafka-connect container terminal by executing the command docker exec -it kafka-connect-debezium-mysql bash.
Execute the following curl command to post the connector configuration to Kafka Connect:
curl --request POST --url http://localhost:8083/connectors --header 'Content-Type: application/json' --data ' {"name": "mysql-db-connector","config": { "connector.class": "io.debezium.connector.mysql.MySqlConnector", "tasks.max": "1", "database.hostname": "mysql", "database.port": "3306", "database.user": "redpanda", "database.password": "redpanda", "database.server.id": "1", "database.server.name": "mysql", "database.allowPublicKeyRetrieval":"true", "database.include.list": "redpanda", "table.whitelist": "redpanda.payment_method", "database.history.kafka.bootstrap.servers": "redpanda:9092", "database.history.kafka.topic": "dbhistory.mysql", "include.schema.changes": "true"} }'
Note that the post request is made on the 8083 port as indicated earlier. This connector configuration also takes care of the following important aspects of this sample project:
database.include.listpayment_method table; hence, it is added to the table.whitelist variable. Unless unspecified, all tables in the database.include.list will be considered for CDC data extraction. For each table, its own topic will be created by default.To explore more Debezium–MySQL connector properties, refer to this documentation link.
Once the connector configuration is created, you can make a GET request to retrieve the configuration at any time and verify the details or entries made in Kafka Connect.
curl -X GET http://localhost:8083/connectors/mysql-db-connector
Switch back to the Redpanda container terminal and execute the following command to check if all the configured topics were created in the Kafka broker:
rpk topic list
You will notice that the topic mysql.redpanda.payment_method has been created

Aas good practice you're going to create a schema for our data. The purpose of the schema registry is to provide a RESTful interface for storing and retrieving Avro schemas. This is important, and it’s used for documenting your APIs so you may be able later to evolve your APIs and version them.
Currently, Redpanda supports the Avro format, but the Protobuf and JSON format schemas will be added in the future. The registry enables you to organize your schemas and allows your applications to flexibly interact with each other. For example, whenever you want to consume data from a topic, you can call the schema registry and get the contract/model that your data should have and cast your received events based on that specific schema. This will allow you to make sure you are consuming consistent data into your application, and remove the properties that you are not using.
A schema is registered against a subject in the form of {topic}-key and {topic}-value. The key schema is used for the unique identifier, and the value defines other properties. You'll use the Avro format to define the key and value of our topic mysql.redpanda.payment_method
To create the key with Avro schema, run the following command inside the redpanda container, since the schema registry is built-in with Redpanda.
curl -s \
-X POST \
"http://localhost:8081/subjects/mysql.redpanda.payment_method-key/versions" \
-H "Content-Type: application/vnd.schemaregistry.v1+json" \
-d '{"schema": "{\"type\":\"record\",\"name\":\"payment_method\",\"fields\":[{\"name\":\"id\",\"type\":\"int\"}]}"}'
Then to create the value run the following command
curl -s \
-X POST \
"http://localhost:8081/subjects/mysql.redpanda.payment_method-value/versions" \
-H "Content-Type: application/vnd.schemaregistry.v1+json" \
-d '{"schema": "{\"type\":\"record\",\"name\":\"value\",\"namespace\":\"mysql.redpanda.payment_method\",\"fields\":[{\"name\":\"code\",\"type\":\"string\"},{\"name\":\"description\",\"type\":\"string\"},{\"name\":\"created_date\",\"type\":\"long\",\"logicalType\":\"timestamp-millis\"},{\"name\":\"last_modified_date\",\"type\":\"long\",\"logicalType\":\"timestamp-millis\"}]}"}'Now you've created your schema in the Redpanda schema registry, you can fetch the created schemas by calling the RESTful endpoint:
curl -s "http://localhost:8081/schemas/ids/1"
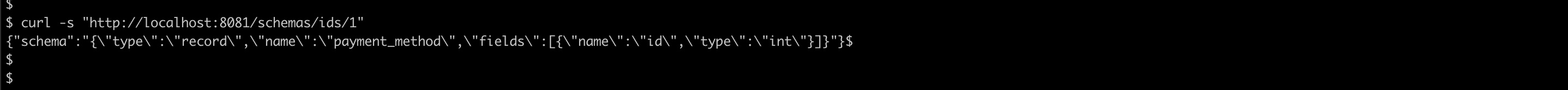
curl -s "http://localhost:8081/schemas/ids/2"

The mysql.redpanda.payment_method topic receives CDC events for any change in the payment_method table in the sample MySQL database.
Execute the following consumer utility command in Redpanda rpk CLI to listen for any events received by the mysql.redpanda.payment_method topic, and keep the terminal running to see the events:
rpk topic consume mysql.redpanda.payment_method
Now that all the required topics are in place and the connector configuration is set up, open another terminal and log in to the mysql container with the following command:
docker exec -it mysql bash
Now initiate the MySQL CLI using the command mysql -u redpanda -p. Specify the password on the prompt. The password, as configured in the Docker Compose file, is “redpanda”.
Execute the following SQL commands to access the Redpanda database and check the sample data in the payment_method table:
use redpanda;
select * from payment_method;Next, execute the following command in the payment_method table to update the table's data and stream it to Debezium:
update payment_method set name='Net Banking' where id= 1;Finally, the data reaches the topic mysql.redpanda.payment_method via Kafka Connect.
If you switch your terminal to the Redpanda container, you should see a new event received for the change made in the database table. Given below is a sample CDC event that got registered on the topic:

With the example project in this article, you have now experienced the power of real-time CDC processing with Debezium and MySQL via Kafka Connect, and Redpanda. Changes in database tables are streamed through the data pipeline and reach the topic as they happen. You can now design real-time reports or dashboards based on this pattern, thus ensuring data visibility and rapid delivery of operational insights. What you create next is up to you!
As a reminder, all of the code and files used in this tutorial can be found in this GitHub repo.
Take Redpanda for a test drive here. Check out our documentation to understand the nuts and bolts of how the platform works, or read our blogs to see the plethora of ways to integrate with Redpanda. To ask our Solution Architects and Core Engineers questions and interact with other Redpanda users, join the Redpanda Community on Slack.
Subscribe to our VIP (very important panda) mailing list to pounce on the latest blogs, surprise announcements, and community events!
Opt out anytime.

