




Drag, drop, done: a visual composer for Redpanda Connect
Boxes and arrows for people who move billions of events a day. No per-row invoice required.

Learn how we engineered our Raft group protocol to provide consistency during reconfiguration.








Streaming data platforms like Redpanda and Apache KafkaⓇ organize messages into topics, which are further organized by partitions. Redpanda maps partitions 1-1 to a separate Raft cluster instance, which we internally call a Raft group.
The ability to change the member set of Raft groups is very important for operating a cluster, as it is required when cluster topology changes (e.g. Nodes are either added or removed from the cluster). This process of changing a Raft group’s member set is called Raft group reconfiguration and can include adding, removing, or replacing Raft group members. Raft group reconfiguration is also leveraged during the continuous data balancing process, which you can read more about here.
In a robust and intuitive solution, the Raft group’s availability guarantees should be maintained in all scenarios, including reconfiguration. Unfortunately, the standard Raft approach based on joint consensus does not always provide standard Raft protocol availability guarantees.
In this blog, I discuss the approach we took to solve the reconfiguration availability issue and the details of how Redpanda Raft group reconfiguration now works to prevent this loss of availability.
To fully understand and benefit from what I’m going to talk about in this post, though, I’ll first clarify the difference between how Kafka and Redpanda approach replication protocols. Then, we’ll move into the heart of this post: How we re-engineered our Raft replication protocol to prevent loss of availability during reconfigurations.
In the Kafka API, topics are used to organize messages. Each topic represents a named category, and its name is unique across the cluster. Topics are sharded into partitions, and each partition is replicated. In this sense, partitions may be seen as instances of replicated log data structure.
Redpanda implements Kafka API with the same semantics for topics and partitions but uses different internals. Here’s how it works: Redpanda uses Raft as its replication protocol. As I mentioned in the introduction, each partition is backed by a separate Raft cluster instance called a Raft group.
Raft groups consist of all Raft protocol participants. Each Redpanda broker may be a part of multiple Raft groups (i.e. The broker can be a host for members of multiple Raft groups).
Raft group members are placed in a certain number of Redpanda nodes depending on desired replication factor. Raft group members are internally mapped to Kafka protocol partition replicas. One of the members is elected as a leader and the others are the followers.
In basic conditions, the Raft group can tolerate up to F failures, where the number of members N is defined as N = 2F + 1, and still accept writes or “be available.” (N can be understood as a topic replication factor.) Having the availability formula defined, we can say that, to tolerate single-node failure, we need at least three members.
Raft protocol leverages a special type of message to distribute configuration across all members. Those special messages contain a current set of nodes that are participants in a Raft group. Every time a Raft protocol instance receives a set of messages containing configuration, it immediately starts to use it as a current and valid one. This way, Raft uses the same replication mechanism to distribute both the actual data and protocol metadata (i.e. Configuration).
When configuration changes, the current leader replicates a new configuration message and sends it to the follwers. To change the configuration while maintaining Raft consistency guarantees, it is not enough to simply instruct a leader with a new set of members. This might cause a situation in which the new member set knows nothing about the old one, and can immediately elect a new leader, leading to data loss.
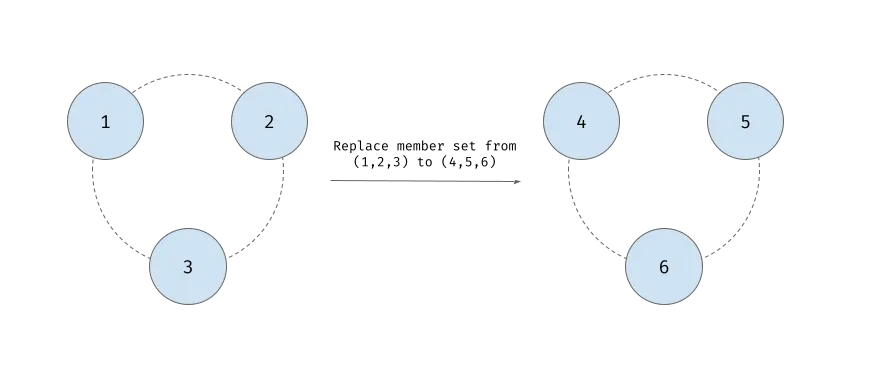
Redpanda Raft implementation leverages the joint conesus protocol to provide consistency during reconfiguration.
As described in this paper by Raft’s creator, Raft uses a joint consensus algorithm to perform member set reconfiguration. This is described in Figure 11 of the Raft paper, included here for your convenience:
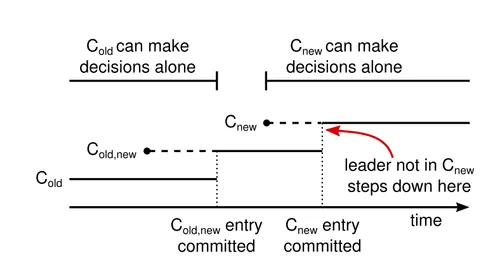
To move the member set from Cold to new member set Cnew the cluster enters a mode in which both member sets must reach an agreement on replicated messages and on the elected leader. A leader can be elected from either one of the quorums. This is joint consensus.
In Redpanda, a joint consensus algorithm with some improvements is used to perform cluster reconfigurations. An improvement we added on to the joint consensus algorithm is the introduction of learner nodes.
Learner nodes are the nodes that are the followers, but they are not accounted to the majority. That is, they are not required to elect a leader and accept writes. This way, when new members are added to the current member set, the Raft protocol can operate without interruption, even if the majority would change as a result of the addition.
For example, increasing the replication factor from 1 to 3 would require waiting for at least one of the two newly added nodes to be up to date before accepting any new writes.
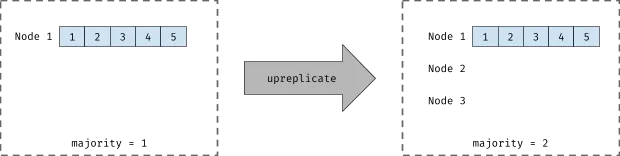
In the image above, we show the majority change as a result of replication factor change.
Adding the new members as learners that do not participate in the majority allows the Raft group to operate continuously while bringing newly added members up to speed since the learner agreement is not required to accept writes. When configuration containing a learner node is stored by the leader, it starts sending missing log pieces to the nodes.
After a learner node is up to date with the leader, it is promoted to a voter (This requires another configuration to be replicated). When a learner becomes a voter it is accounted into the majority.
Learner semantics are also useful when nodes are being removed from the current configuration. Before nodes are removed from the member set, they are demoted to learners (For more information about the need for that step see this GitHub commit).
For the purpose of this blog post, we are going to represent Raft configuration as a diagram where:

When the old configuration is grayed out in the diagram it means that only a new configuration is active.
Examples 1: Simple (stable) configuration with nodes 1, 2, and 3 as voters.
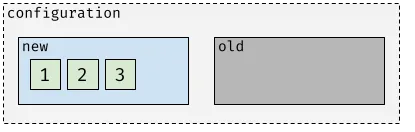
Example 2: Joint configuration with nodes 1 and 2 as voters in the new configuration and node 4 as a learner in the new configuration. Nodes 1 and 2 are voters in the old configuration and node 3 is a learner in the old configuration.

The Raft protocol, as implemented in Redpanda, was subject to reduced availability during reconfiguration. While traversing through the stages of configuration changes, the Raft group reached a point in which it was not able to tolerate any node failures, even though the Raft group had three members. I discuss the availability reduction issue, together with an explanation of the old reconfiguration protocol, in the next section.
To illustrate the availability issue we encountered, let's consider an example in which we replace one member in a three-node member set of a Raft group. Assume we are changing the member set from nodes 1,2,3 to nodes 2,3,4. Here's how that would work.
Initial state:
The move is requested, entering the joint configuration stage. Node 4 is added as a learner (a non-voting follower):
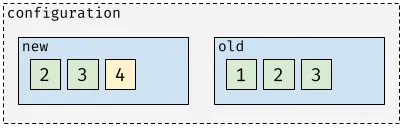
After node 4 is up to date with the current leader (meaning all previous entries were delivered to that node), it gets promoted to voter:
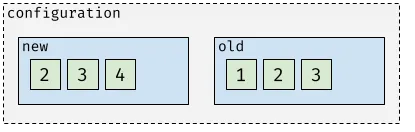
Before removing node 1 from the quorum, node 1 is demoted to learner:

Finally, node 1 is removed from the configuration after the configuration is committed:
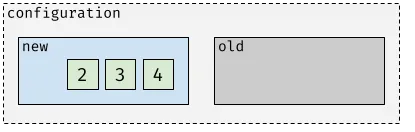
In the example above, every time the voter list contains only two nodes its availability is reduced because, according to the joint consensus rules, both old and new quorum must agree on updating the committed offset and electing the new leader.
For a quorum containing two nodes, the majority required to continue operations is two. In this example, if either node 2 or 3 fails, the whole group will be unavailable.
In order to fix the availability issue descibed above, we decided not to allow any voters’ lists to shrink to a size smaller than the requested replication factor.
Remember that, in Redpanda, we also support changing the replication factor of a partition (but do not yet support this for individual topics). In this case, the number of tolerated member failures will be the minimum of tolerated failures of source and target configurations.
The solution we implemented is based on altering two steps in the standard Raft joint consensus approach:
With the new solution in place, the change from the previously presented example is executed as follows:
In the first step, a new member is added to the current configuration as a learner:
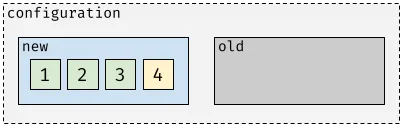
The next leader waits for all learners to be promoted to voters.
After that, the configuration would contain four voters:
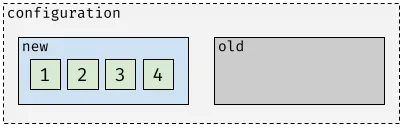
In the next step, the Raft group enters joint consensus mode with the requested member set present in the current configuration. Not-needed member 1 must be deleted.
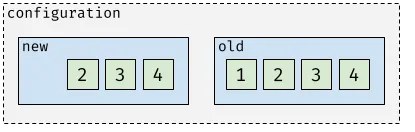
After entering the joint configuration, all steps are the same as previously described:
First, nodes that are going to be removed are demoted to learners.
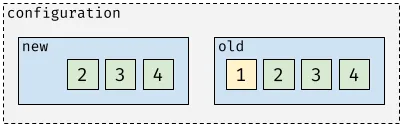
After the configuration from the previous step is committed, the leader decides to enter and replicates the new simple configuration.
Thanks to the presented solution in Redpanda, we have the same availability guarantees for the whole partition lifecycle. This availability fix was especially relevant as, in the most recent Redpanda version, we deliver our Continuous Data Balancing feature, which automates moving partition replicas without user intervention.
Though Raft is a simple, robust, and widely adopted distributed consensus protocol, implementation and operationalization in mission-critical production environments can be a challenging, difficult, and time-consuming process. At Redpanda, we do our best to make complicated things simple for our users, and this Raft group reconfiguration solution is one more way we’re able to do that.
Take Redpanda for a test drive here. Check out our documentation to understand the nuts and bolts of how the platform works, or read our blogs to see the plethora of ways to integrate with Redpanda. To ask our Solution Architects and Core Engineers questions and interact with other Redpanda users, join the Redpanda Community on Slack.
Boxes and arrows for people who move billions of events a day. No per-row invoice required.

You can't scale what you can't trust. A governance layer fixes that.

What is it, why enterprises need it, and how to evaluate one
Subscribe to our VIP (very important panda) mailing list to pounce on the latest blogs, surprise announcements, and community events!
Opt out anytime.