




Bridge Queries in Redpanda SQL
Have your real-time cake and eat your analytics too
A friendly beginner's guide to real-time data streaming and how to get started









The ability to process and analyze data in real time is no longer a luxury but a necessity for many businesses. Real-time data streaming allows organizations to harness the power of continuous data flows, enabling immediate insights and responsive decision-making.
Whether it's monitoring financial transactions for fraud detection, optimizing user experiences on a website, or ensuring high availability in mission-critical applications, real-time data streaming is increasingly central to many business functions. Read on to learn how it works, how it differs from batch data processing, its benefits, real-world examples, and how you can get started.
Real-time data streaming involves collecting, processing, and analyzing continuous streams of data in real time. These data streams could include server activity logs, user engagement events in an app or website, stock market fluctuations, or any other context where data is generated continuously at a high speed with no set beginning or end.
Streaming data is time-stamped and often highly time-sensitive, making continuous, real-time analysis key for a variety of business applications. This requires specialized software architectures that reduce processing times to a matter of microseconds.
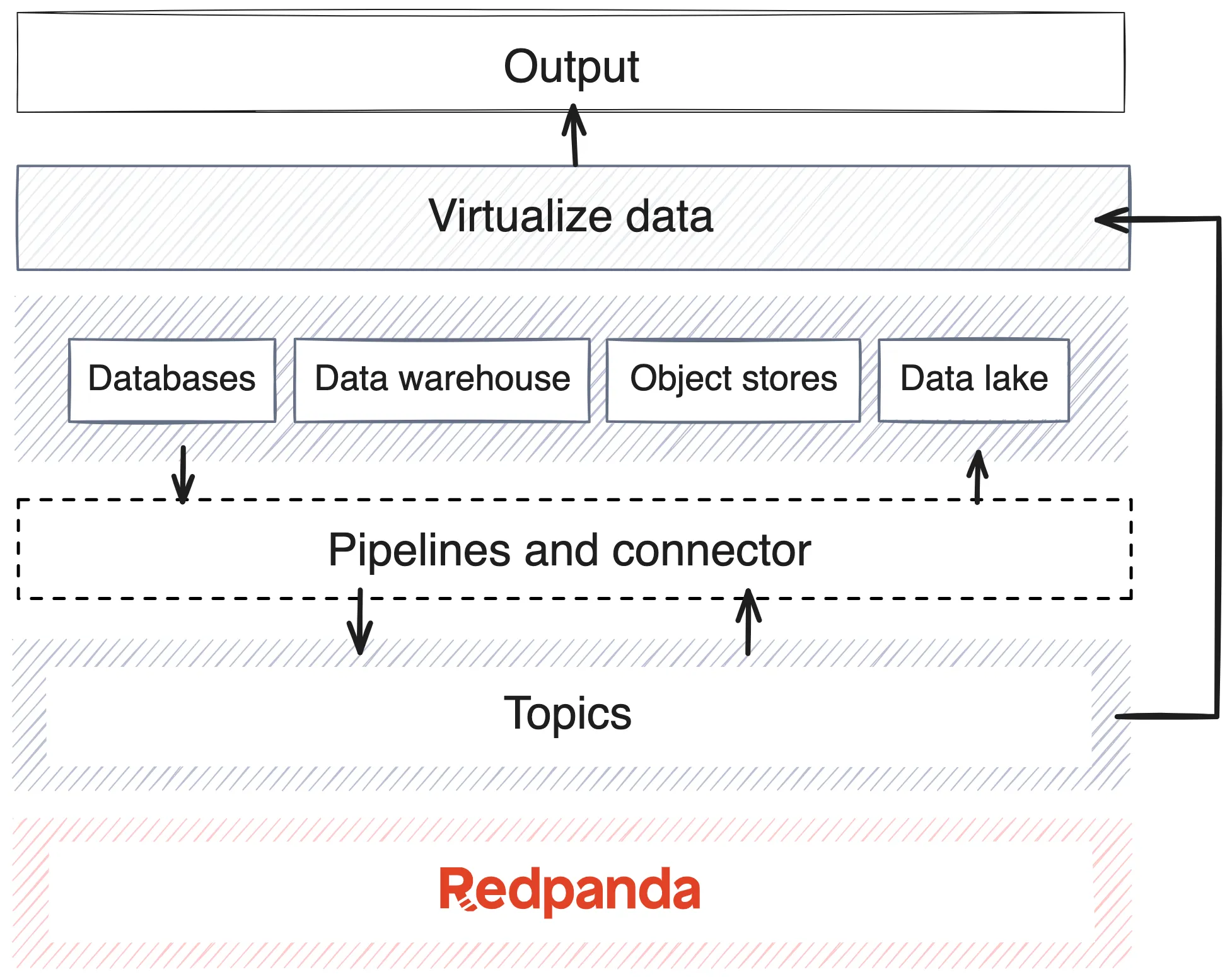
The process of real-time data streaming starts with a data source, like a website or app, an IoT sensor, or any other device or endpoint generating a stream of data. From there, the stream passes through data streaming architecture with a few key software components:
While this simplified explanation implies a simple one-directional flow, actual streaming data architectures can be considerably more complex. For example, some topics may feed back into the systems that originated the data, turning data pipelines into loops. Your organization’s streaming data architecture will ultimately depend on your specific use cases, existing legacy infrastructure, and other factors.
Streaming data processing and batch data processing are two distinct approaches to handling and analyzing data, each suited to different types of use cases.
Think of the difference between streaming a video to your computer vs. downloading a video file. In the first case, your computer receives a continuous stream of data you use in real time (to watch the video). In the other, you wait to download all the data you need in one chunk.
Here are a few key differences between these approaches:
One of the primary benefits of real-time data streaming is the ability to gain immediate insights from data as it is generated. This enables organizations to make faster, more informed decisions, which is crucial in environments like financial markets, where rapid responses to data can mean the difference between profit and loss, or in cybersecurity, where suspicious activity within a system must be addressed immediately to counter potential cyberattacks. Real-time data streaming allows businesses to react swiftly to changing conditions, such as market fluctuations, customer behavior, or system anomalies, enhancing overall agility and responsiveness.
In addition, in customer-centric industries, real-time data streaming can significantly improve the user experience by enabling personalized interactions and services. For example, in e-commerce, real-time analytics can be used to recommend products based on a customer's current browsing behavior, increasing the likelihood of a purchase. This level of immediacy and personalization helps build stronger relationships with customers and drives customer loyalty.
When it comes to data streaming use cases, the benefits almost always outweigh the potential downsides. If you design your data streaming architecture properly, you can mitigate common challenges including:
For some types of data streams, traffic can be highly variable, with sudden bursts or spikes. For example, a web publisher might see a sudden spike in user engagement activity when a piece of content goes viral, potentially overwhelming its systems. You need infrastructure that can scale up and down rapidly without delays, downtime, or data loss.
Real-time data streaming does require you to invest in dedicated infrastructure and in some cases additional cloud storage or compute capacity. But you can control costs with solutions that maximize operational efficiency. For example, Redpanda utilizes tiered cloud storage and Cloud Topics that batch writes directly to cost-efficient object storage and replicate only metadata to save on cross-AZ networking costs.
Streaming data applications need to pull from the stream continuously, which means any downtime can cause significant issues. Mitigate the risks of stream interruption due to broker downtime by distributing your data pipelines and underlying data across multiple availability zones (AZs).
Be mindful, however, that this can drive up network bandwidth costs, since traffic that crosses AZs may incur additional fees from your cloud provider. A streaming data platform with features like follower fetching can provide the high availability you need while optimizing your network traffic to minimize added costs.
Backing up data stored in the cloud or on-prem is a basic element of security and disaster recovery protocols at most enterprises. However, it’s less common to back up data in motion. If real-time streaming data is lost or corrupted in transit, it can be difficult to recover — unless you’re using a highly fault-tolerant, durable, and enterprise-grade solution.
Besides distributing data across availability zones, Redpanda also guarantees a high level of data safety through our Raft consensus algorithm, which governs data replication across clusters. Both data and cluster metadata are regularly backed up to cloud object storage, allowing entire clusters to be efficiently restored directly from object storage.
Because real-time data streaming enables the generation of immediate, actionable insights from data, it’s important for a number of use cases across industries that require fast, accurate decision-making at scale.
You need a data streaming platform powerful enough to manage all the real-time data streams you need, but simple to deploy and manage.
Redpanda’s enterprise-grade streaming solution delivers 10x lower tail latencies and 6x faster transactions without the technical complexity of Apache Kafka. With Redpanda, you manage all your clusters through a single tool, and gain visibility into all your streams with the industry’s most complete web UI. Best of all, there’s no need for external dependencies like JVM that make deploying in modern environments a headache.
Ready to accelerate your data pipelines? Check out Redpanda’s platform capabilities.
Subscribe to our VIP (very important panda) mailing list to pounce on the latest blogs, surprise announcements, and community events!
Opt out anytime.

