





Full CDC semantics land in the Iceberg output for Redpanda Connect
Your lakehouse mirrors the database, instantly.

Say hello to redaction made simple with our pre-built, no-code library








With the recent announcement of Redpanda 23.3, users can now embed stateless data transformations right into the heart of Redpanda using Data Transforms powered by WebAssembly (Wasm). There are many use cases for this, including format transcoding, validation and verification, filtering, and redaction of sensitive information.
In this post, we introduce a pre-built library that performs config-driven data redaction, showing how it can be used to sanitize incoming messages — allowing the resulting data product to be consumed by a wider audience within an organization.
The more data you work with, the more data you’ll come across that is sensitive. Records often contain particular fields that hold sensitive financial, medical, or personally identifiable information (PII). These fields, essential for their original purpose, also come with a compliance responsibility, placing legal constraints from regulations like GDPR, HIPAA, CCPA, and PCI on how that data should be handled and used.
While the sensitive parts of a record clearly need to be treated with utmost care, the majority of the data fields may be entirely innocuous - and can often contain significant untapped business value. Removing or otherwise transforming the sensitive fields — known as redaction — transforms the data from a metaphorical hot potato into a proverbial golden nugget.
Data transformations within Redpanda are easy to get started with. Beginning in 23.3, we provided a new rpk command that enables you to:
All you need to do is create the topic that will hold your redacted data and then deploy your transform.
For folks who love to craft and code, or who require full control of the redaction process, this approach gives you everything you need. For the rest of us — the architects, the admins, the data stewards, the perpetually busy — there’s an even simpler approach: use a pre-built no-code solution.
Most redaction requirements are very similar: drop a field; change a value to “REDACTED”; replace digits with X’s, and so on. With a code-based approach, each redaction process requires a unique code solution that is tightly coupled to the data it processes.
To make the process of redaction easier to implement and simpler to understand, we’ve developed a framework that uses a config-driven approach to define redaction rules for JSON data. It’s available today from Redpanda Labs under the Apache Software License 2.0 — feel free to use it on your data!
To get going, you’ll need to clone the GitHub repository, configure your redactions, and run the deploy script. You also need a Redpanda cluster running 23.3 or later, since we’ll be relying on Data Transforms.
In this section, we’ll use the Owl Shop e-commerce demo as an example, since it already produces order messages that contain personal information. We plan to process the orders, remove any personal information, and leave only content that could be used to understand what is being ordered.
The redaction framework contains the following built-in actions:
("")REDACTED"hashedKey” and the value to the MD5 hash of the original valueNote: If these actions don’t cover your use case, it might be possible to still use the redaction framework - see the section on “custom redaction” for more details.
Looking at an unredacted Owl Shop order, we see personal information throughout the record, which means that multiple redaction rules will be needed. Each rule specifies both an action to perform (from the list above) and a JSON path to which that redaction applies.
The table below shows a few examples of the redaction rules in action:

With the redaction rules in mind, we’re now in a position to write our configuration file:
We start the deployment process by first creating the output topic that will store our redacted orders. Since the redaction transform will write out as many messages as it receives, it makes sense to create the topic with the same number of partitions as the source. That way, there is a 1->1 mapping of the partitions for the transform writes:
Next, we deploy the transform by running a deployment script. While we could just use rpk transform deploy, the script also handles the redaction config by compressing and encoding it. We proceed by calling the script and passing it the config and the topic names:
At this point, you should now have redacted messages flowing into your new topic, so it’s a great time to look at the content in Redpanda Console and verify that they are suitably transformed:
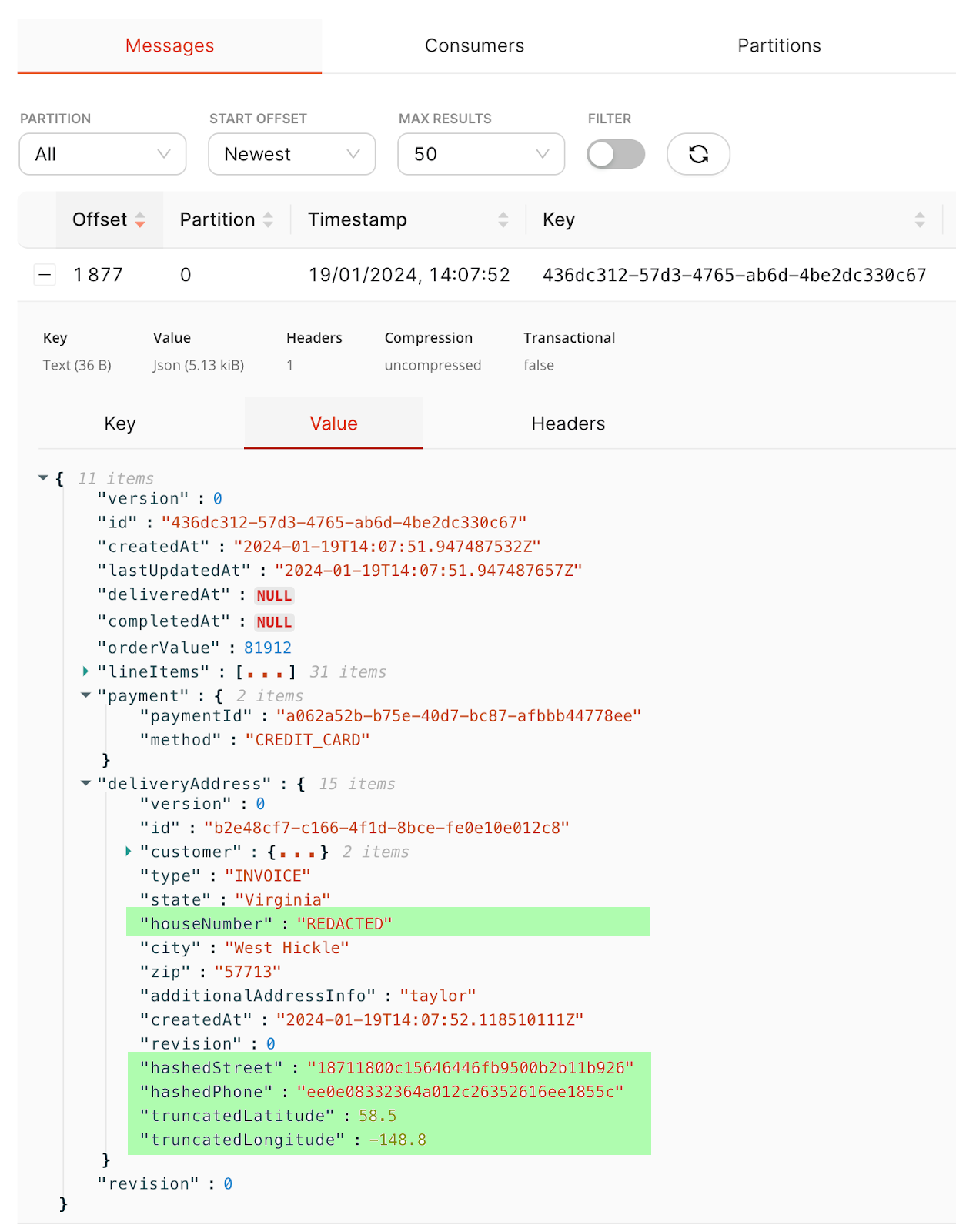
For more complex redaction processing, testing outside of Redpanda is recommended. For this reason, the redaction framework includes a standalone script to show how a message would be affected by a particular redaction configuration.
To run the redaction tester, use a command line such as the following:
When run, this writes the transformed message back to the screen, allowing a visual inspection as well as direct comparison using tools such as diff.
While the built-in redaction capabilities may be all you ever need, you may have a use case that requires a different transformation. The redaction framework was designed to be extensible, allowing you to create your own functions that specify how a key or value will be transformed.
Details on how to achieve this can be found in the GitHub repository.
As you’d expect, pull requests are welcome!
In addition to the redaction transform itself, we also have an end-to-end demonstration of redaction using Docker Compose. To run the demo, clone the GitHub repository and use the following:
This starts the Redpanda Broker and Console in containers, along with Owl Shop to simulate e-commerce traffic. It also runs a short-lived container that deploys the redaction transform using the build and deploy script. Feel free to customize the configuration and see how orders change!
We walked through how stateless data transformations using Data Transforms allow us to embed data processing within a Redpanda broker, without needing an external processing platform such as Flink.
We then covered an example transformation project for handling redaction that only requires a user to write configuration, allowing anyone with a need to redact data to do so quickly and simply. Finally, we saw an end-to-end demonstration of redaction and how we can go further if needed.
To learn how else Redpanda can make your job easier, check our documentation and browse the Redpanda blog for use cases and tutorials. If you have questions or want to chat with our team, join the Redpanda Community on Slack!
Subscribe to our VIP (very important panda) mailing list to pounce on the latest blogs, surprise announcements, and community events!
Opt out anytime.

