




Stream Oracle changes to ClickHouse in real time with Redpanda Connect
A hands-on walkthrough of our new Oracle CDC connector
The possibilities are endless when you have 280+ connectors at your fingertips — but here are 10 to get you started









Redpanda Connect can decode messages from one format, change their structure, and encode them back into a different format. This is useful for data format normalization and system integrations. The processors support formats including Avro, JSON, Protobuf, Parquet, MessagePack, and XML.
The sql_select operator in Redpanda Connect executes a select query against a database and creates a message for each row received. For writes, the sql_insert operator inserts rows into an SQL database for each message. You can also use the sql_raw operator to run an arbitrary SQL query against a database. Both operators support databases including MySQL, Postgres, MSSQL, SQLite, Oracle, ClickHouse, Trino, and Azure CosmosDB.
The cache operator in Redpanda Connect performs operations against a cache for each message, allowing you to store or retrieve data within message payloads. This enables two important use cases: message deduplication and enrichment. Redpanda Connect supports cache implementations including but not limited to Redis, AWS S3, AWS DynamoDB, Google Cloud Storage, Memcached, MongoDB, CouchDB, memory, SQL databases, and files.
With over 300 connectors, Redpanda Connect can be used for a variety of use cases, including message format transformation, executing a code for every message, message mapping and filtering, working with caches, reading from and writing to databases, enqueueing and dequeueing messages from queues, message downsampling, and compressing/decompressing and archiving/extracting messages.
A connector in Redpanda Connect integrates your Redpanda data with different data systems. There are two types of connectors: input connectors and output connectors. An input connector imports data from a source system into Redpanda Connect, while an output connector exports data from Redpanda Connect and transforms it into a format the target system can use.
Redpanda Connect is a lightweight stream processor that allows you to build streaming data pipelines in a declarative manner.
Formerly known as Benthos, Redpanda Connect is written in Go and deployed as a static binary with zero external dependencies. Its functionality overlaps with enterprise integration frameworks, log aggregators, and ETL workflow engines. So, Redpanda Connect can complement these traditional data engineering tools or act as a simpler alternative.
With an ecosystem of high-performance connectors at your fingertips, you’re spoiled for choice when it comes to potential use cases. To help you kick things off, this post highlights 10 handy use cases you can easily implement by pairing Redpanda Connect with relevant technologies.
But first, let’s get familiar with the basics of Redpanda Connect.
When working with Redpanda Connect, you’ll find connectors and processors. As a developer or data engineer, you’ll compose streaming data pipelines with Redpanda Connect using YAML. These pipeline definitions are declarative, consisting of one or more connectors and processors.

A connector integrates your Redpanda data with different data systems. There are two types of connectors: input connectors and output connectors.
aws s3 connector.sql_insert connector.
A processor is a function applied to messages passing through a pipeline. The function signature allows a processor to mutate or drop messages depending on the content of the message.
Processors are set via config, and depending on where in the config they’re placed, they’ll run either immediately after a specific input (set in the input section), on all messages (set in the pipeline section), or before a specific output (set in the output section). Most processors apply to all messages and can be placed in the pipeline section.
Here’s an example of how a processor can be configured in the pipeline section:
pipeline:
threads: 1
processors:
- label: my_cool_mapping
mapping: |
root.message = this
root.meta.link_count = this.links.length()
Browse the Redpanda Connect documentation for the full list of connectors and processors.
With 220+ connectors, you can implement an unlimited number of use cases by combining Redpanda Connect with various technologies, including databases, message queues, data warehouses, etc. These use cases cut through different domains such as data engineering, stream processing, enterprise integration, and more.
Here are 10 handy use cases to get you started.
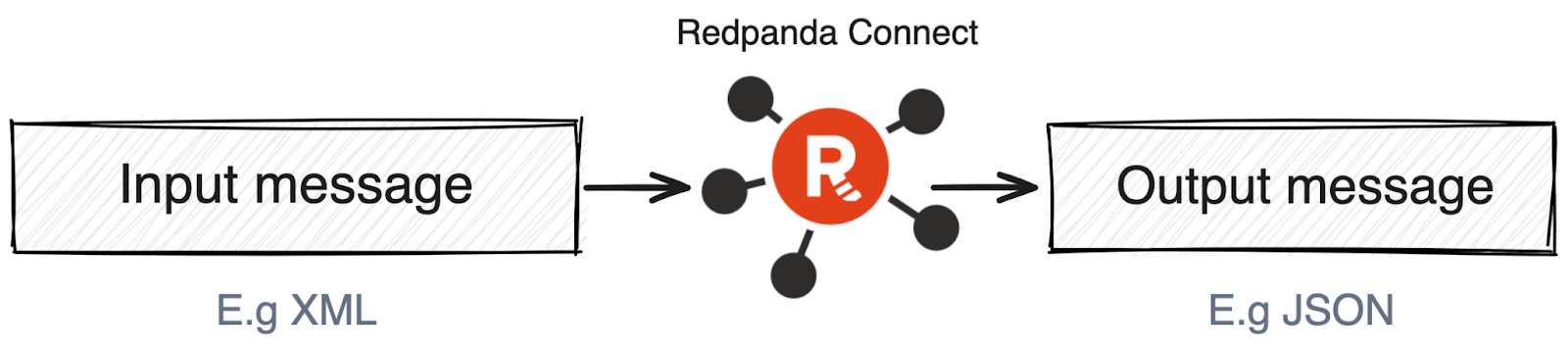
Different processors in Redpanda Connect can decode messages from one format, change their structure, and encode them back into a different format. This feature is highly useful in several scenarios, including:
Processors support formats including Avro, JSON, Protobuf, Parquet, MessagePack, and XML.
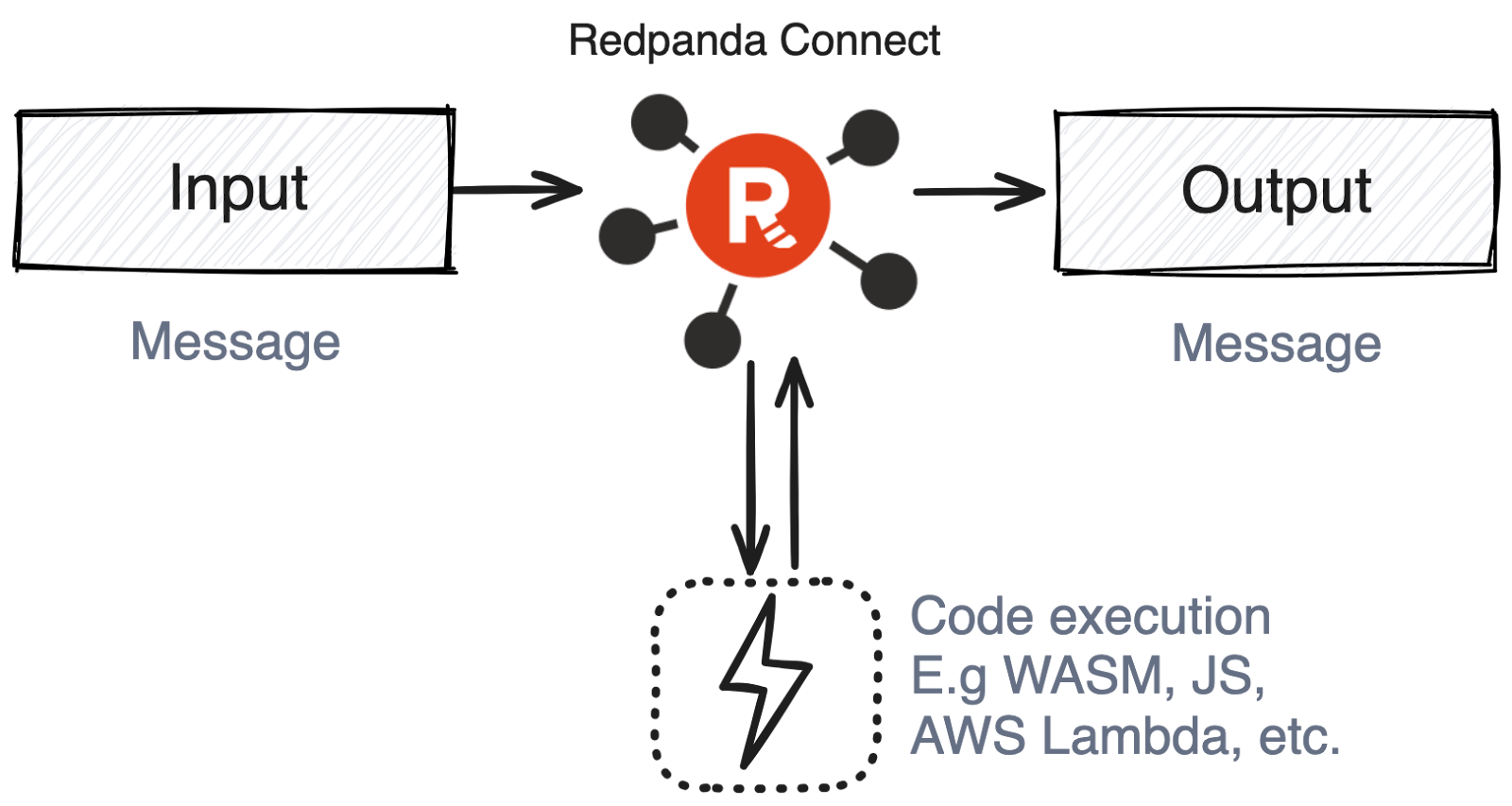
Several processors in Redpanda Connect allow you to execute a code snippet or trigger a function for each message. The contents of the message are the payload of the request, and the result of the invocation will become the new contents of the message.
wasm executes a function exported by a WASM module for each messagejavascript executes a provided JavaScript code block or file for each messagecommand executes a Linux command for each messageaws_lambda invokes an AWS lambda for each message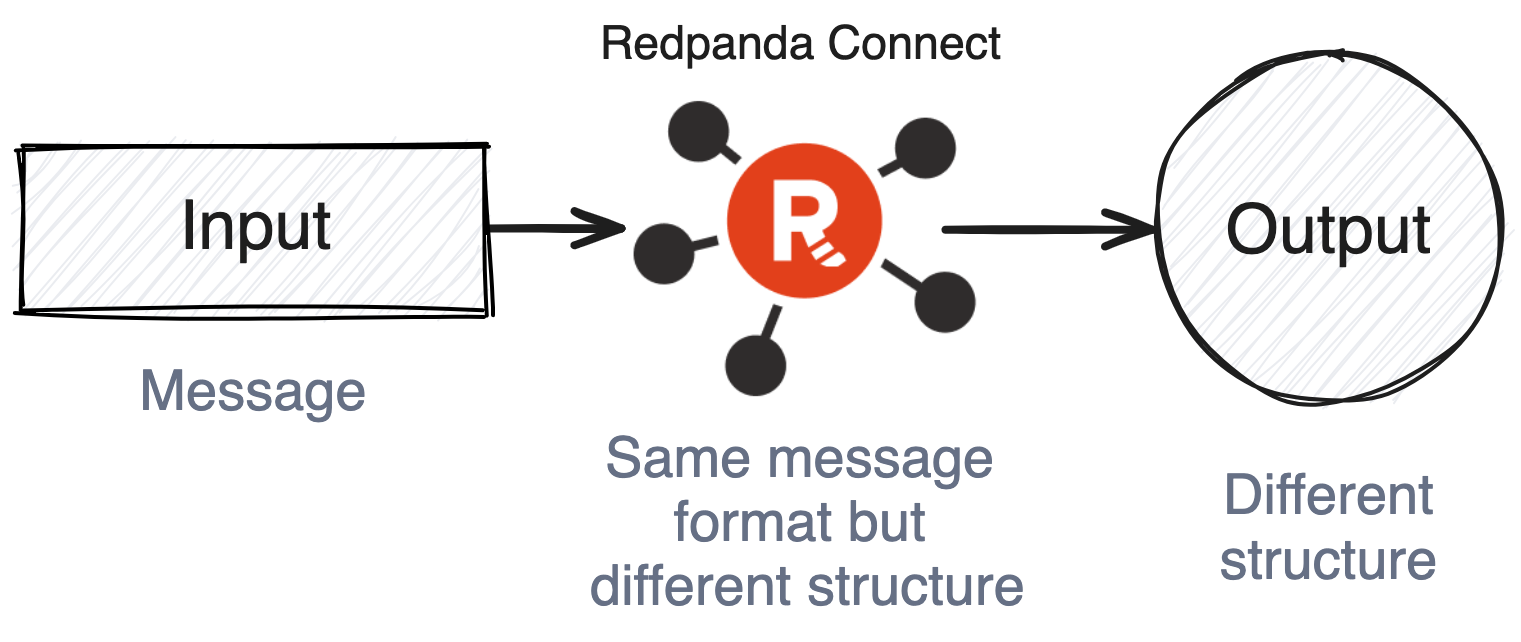
Execute various expressions on the content, transforming it into a different structure. The result of the expression will replace the original message content. If the expression does not emit any value, the message is filtered — producing no result.
awk: Executes an AWK program on messages, querying and mutating message contents and metadata.grok: Parses messages into a structured format by attempting to apply a list of Grok expressions.jmespath: Executes a JMESPath query on JSON documents and replaces the message with the resulting document.jq: Transforms and filters JSON messages using jq queries.Additionally, the mapping and mutation processors can do the same with Bloblang, a powerful language that enables a wide range of mapping, transformation, and filtering tasks.
The cache operator performs operations against a cache for each message, allowing you to store or retrieve data within message payloads.
This enables two important use cases: message deduplication and enrichment. Deduplication can be achieved by adding a message to the cache with a key, extracted from the message itself. If the add operation fails, it indicates that the key already exists, and we can eliminate the duplicate using the mapping processor.
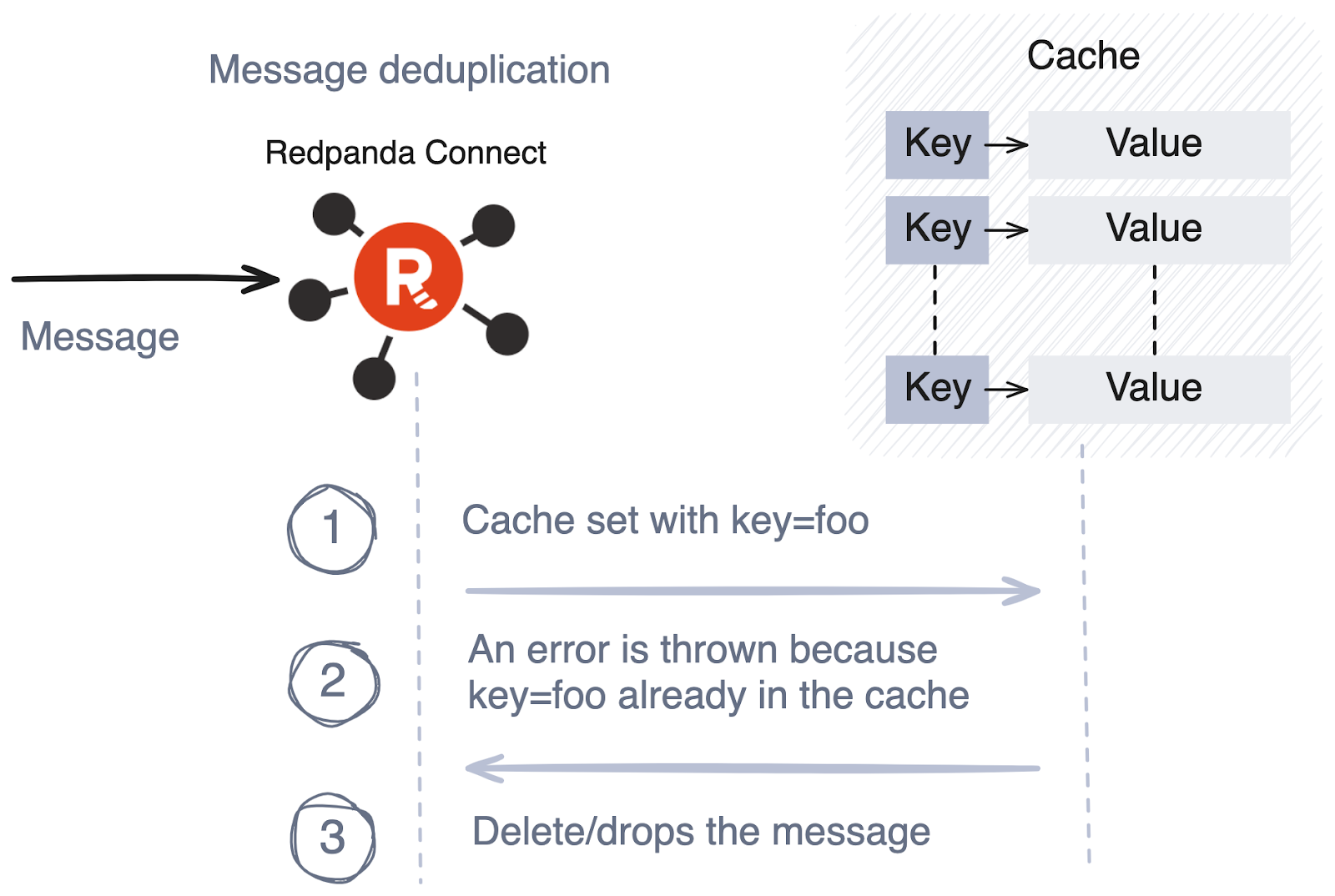
Similarly, you can enrich message payloads with content previously stored in a cache.
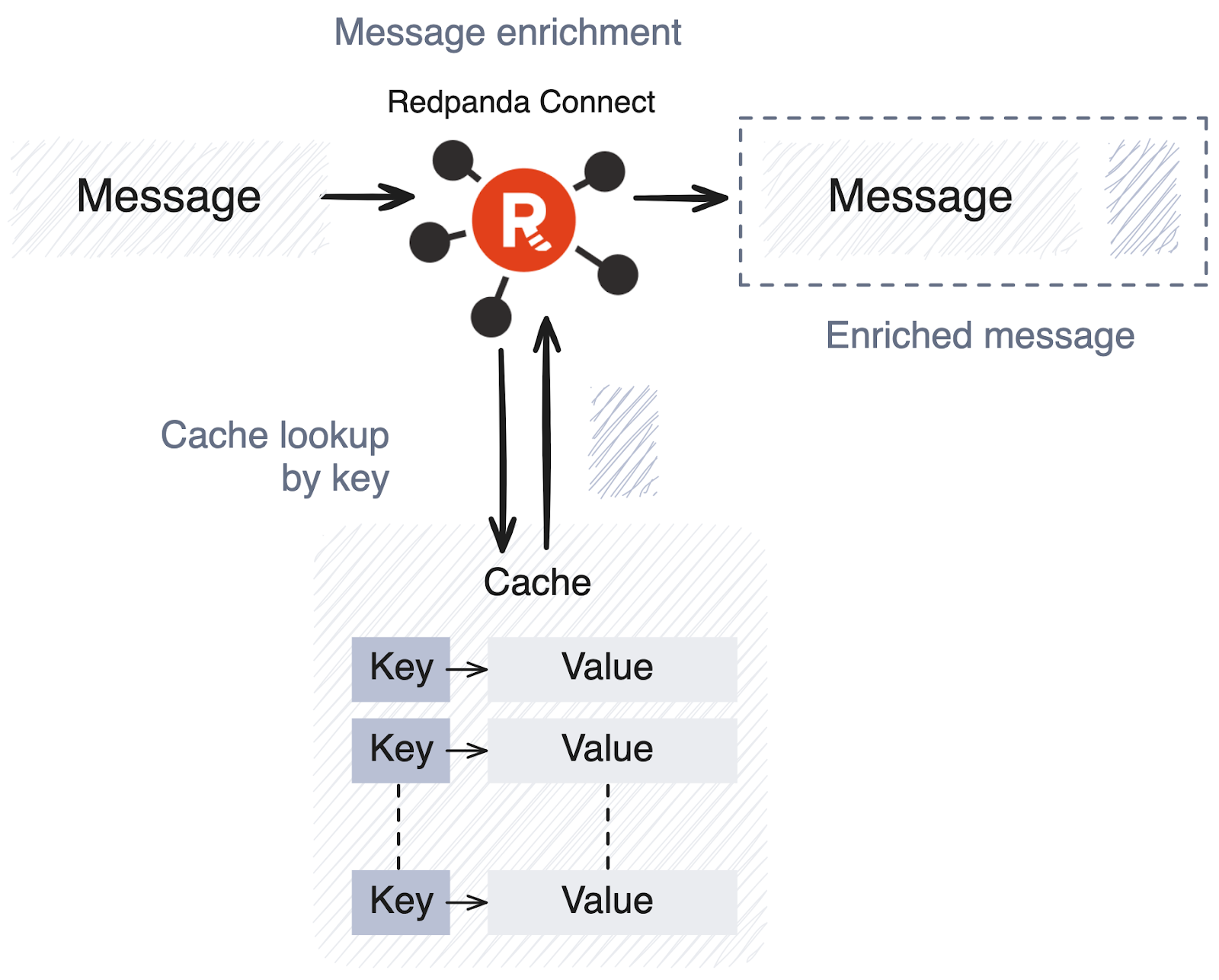
Redpanda Connect supports cache implementations including but not limited to Redis, AWS S3, AWS DynamoDB, Google Cloud Storage, Memcached, MongoDB, CouchDB, memory, SQL databases, and files.
The sql_select operator executes a select query against a database and creates a message for each row received. For example, you could use this operator to read records from a table created within the last hour and forward them to a different processor in the pipeline.
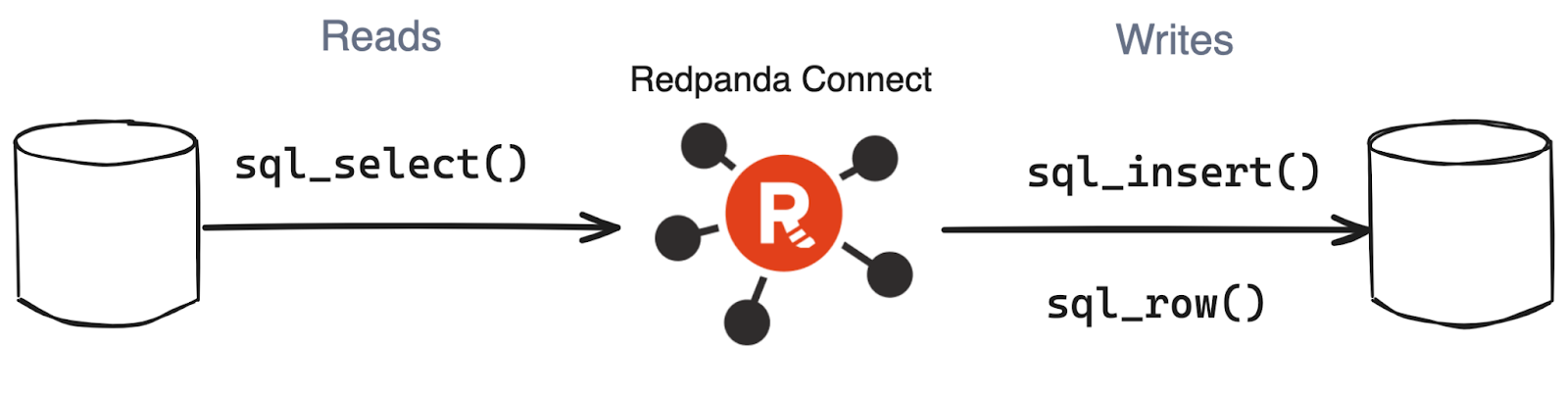
For writes, the sql_insert operator inserts rows into an SQL database for each message and leaves the message unchanged.
Additionally, you can use the sql_raw operator to run an arbitrary SQL query against a database, including SELECT, INSERT, UPDATE, and DELETE queries. For SELECT queries it returns the result as an array of objects, one for each row returned.
Both operators support databases including MySQL, Postgres, MSSQL, SQLite, Oracle, ClickHouse, Trino, and Azure CosmosDB. Additionally, you can work with other databases via relevant processors, such as Couchbase, MongoDB, and Apache Cassandra.

Redpanda Connect has the necessary inputs and outputs to both consume messages from message queues and produce messages to them. This is handy if you want to bridge messages between different message brokers.
Supported implementations include AMQP, MQTT, AWS S3, AWS SNS, AWS Kinesis, Azure Queue Storage, Google Pub/Sub, NATS, Pulsar, Redis Pub/Sub, Kafka, and ZeroMQ.

The rate_limit operator controls the throughput of a pipeline based on a specified limit. This is useful when the downstream system has a lower processing capacity than the data producer.

The compress operator compresses messages using the chosen algorithm. The supported compression algorithms include flate, gzip, lz4, pgzip, snappy, and zlib.
The decompress operator does the opposite—decompresses messages according to the selected algorithm. Supported decompression algorithms are [bzip2 flate gzip lz4 pgzip snappy zlib]
The archive operator archives all the messages of a batch into a single message according to the selected archive format. The output can be a tar or a zip file, a JSON array, a concatenated text, or a binary message.
The unarchive operator does the opposite.

The retry operator attempts to execute a series of child processors until succeeding.
For instance, imagine a child processor attempting to write a message into a database, but it receives an error because the database is offline. After a specified backoff period, the retry operator reattempts the same message at a configured interval until the operation succeeds.
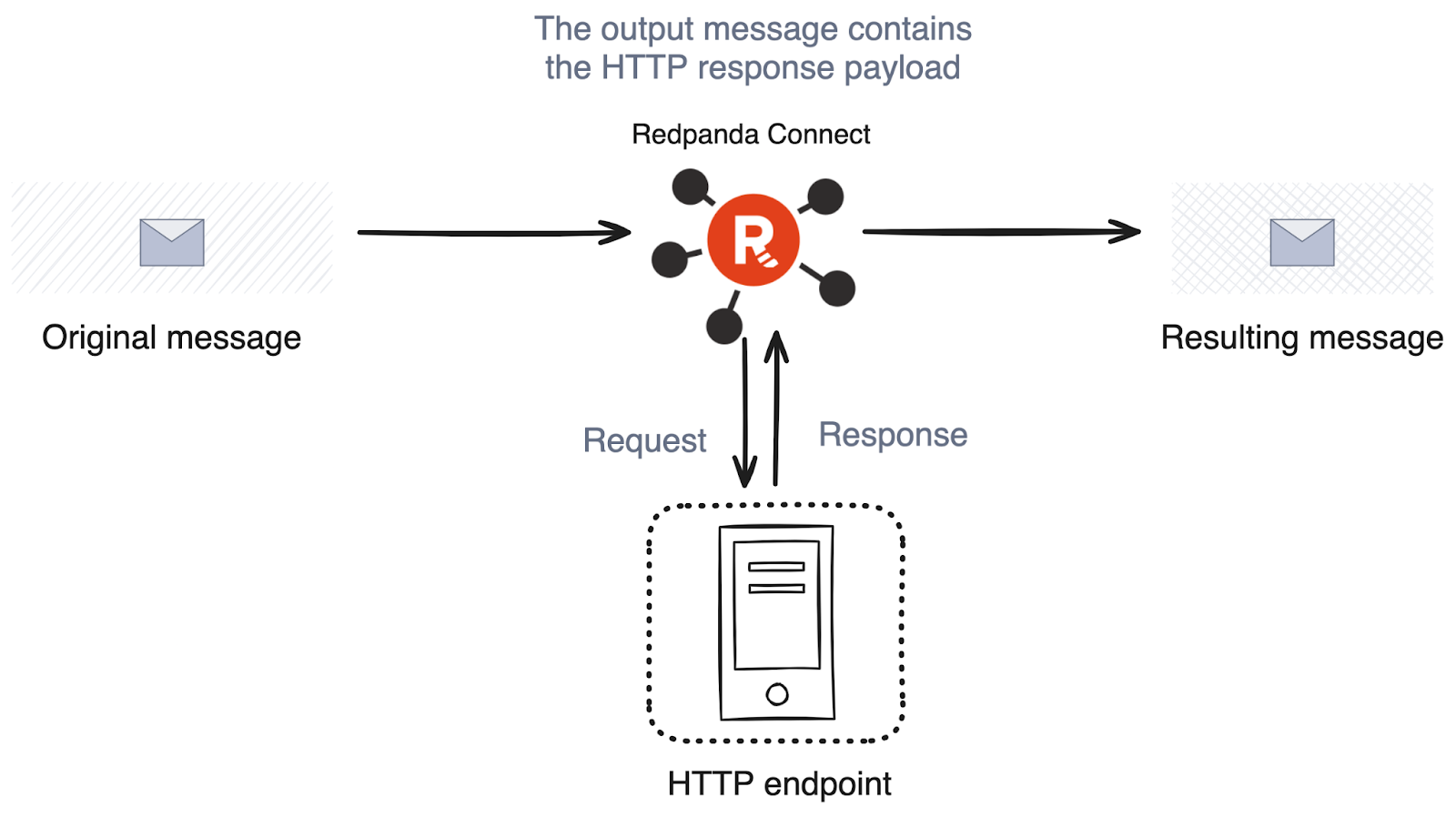
The https operator performs an HTTP request using a message batch as the request body and replaces the original message parts with the body of the response. This is useful when invoking a Webhook or fetching data from an API.
Redpanda Connect allows you to compose streaming data pipelines that move data between systems. You’ll author these pipelines with YAML, making them declarative and version control-friendly.
With its 280+ prebuilt connectors, Redpanda Connect complements Redpanda’s data platform offering by providing smooth integrations to various systems, enabling reliable and efficient data flow.
Want to kick off with Redpanda Connect? Check out our quickstart guide.
Subscribe to our VIP (very important panda) mailing list to pounce on the latest blogs, surprise announcements, and community events!
Opt out anytime.

