





Deploy agents you can trust with centralized AI governance
You can't scale what you can't trust. A governance layer fixes that.

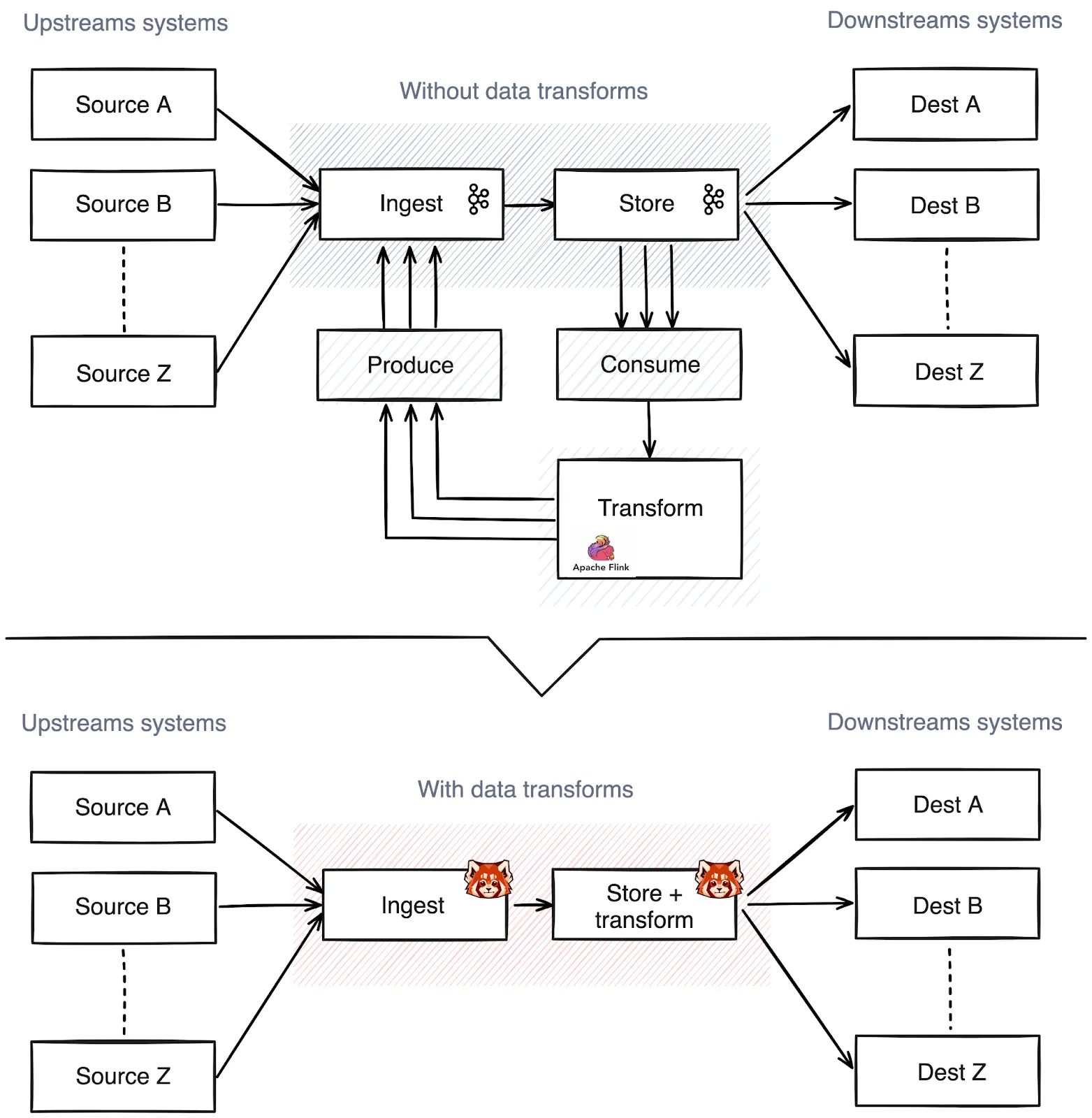
How we eliminated the data ping-pong for simple, efficient data transformation








Redpanda Transforms can be deployed with a single command using 'rpk transform deploy'. You can view the deployed transforms running in the cluster, their status, and any lag using 'rpk transform list'. All these commands use Redpanda's Admin API and are auditable events. Redpanda takes care of storing and managing the code, running the code, moving data around, and providing metrics and logs.
Redpanda Transforms complements the existing tooling and frameworks already used in the enterprise. It inverts the relation of shipping data to compute by shipping code to data. This means that the Redpanda controller can tell you exactly what code is touching what piece of data, on what computers, and at what offsets.
The architecture of Redpanda Transforms consists of three main components: Client-side tooling and SDKs, Data Transforms lifecycle management, and Data flow through the WebAssembly runtime. These components work together to provide a simple experience for data transformation, manage the lifecycle of Data Transforms, and ensure smooth data flow through the WebAssembly runtime.
WebAssembly fundamentally changes server-side software by allowing the injection of code inside Redpanda at strategic points. This changes what the storage engine can do for you while providing isolation, high function density, granularity of execution, native performance, and multi-tenant design — all in your favorite programming language.
Redpanda addresses the data ping-pong issue with Redpanda's Data Transforms. This feature, powered by WebAssembly (Wasm), allows engineers to read data, prepare messages, and make API calls without the need for back-and-forth data movement. This results in simpler and less expensive in-broker data transformations.
WebAssembly (Wasm) enables engineers to transform Redpanda by shipping computational guarantees (code) to the storage engine. It allows for the codification of business practices like GDPR compliance or custom on-disk encryption mechanics with near native-level performance at runtime. It's like what JavaScript did for the web in the late 90s, fundamentally changing the way server-side applications work.
Around 60% of stream processing is spent on mundane transformation tasks. Format unification for machine learning (ML) workloads, filtering for privacy, simple enrichments like geo-IP translations — the list goes on.
To stand up something “simple” often involves three or four distributed systems, multiple nights of reading configurations, and a few too many espressos. Once you’re done, you end up ping-ponging the data back and forth between storage and compute, when all you had to do was remove a field from a JSON object.
To the data engineer, it feels like an endless game of system whack-a-mole before you can start working on the good part of actually understanding the data.
Redpanda solves this problem and eliminates the data ping-pong with Redpanda's Data Transforms. Powered by WebAssembly (Wasm), this feature allows engineers to read data, prepare messages, and make API calls without the “data ping-pong” for simpler and less expensive in-broker data transformations.
In this post, we go under the hood to show you how this engine runs.
Redpanda Data Transforms is built on the Wasmtime engine, which powers many other modern serverless platforms. Embedding this virtual machine directly onto each shard in Redpanda's thread-per-core architecture provides an alternative to the classical data back-and-forth when trying to make sense of real-time streaming data.
What JavaScript did for the web in the late 90s is what Wasm can do for server-side applications. JavaScript allowed developers to turn static content into the immersive web experiences of today, fundamentally changing the web by shipping code to the user’s computer.
Similarly, Wasm empowers the engineer to transform Redpanda by shipping computational guarantees (code) to the storage engine. Codifying business practices like GDPR compliance or custom on-disk encryption mechanics, with near native-level performance at runtime.
In brief, Redpanda Data Transforms lets you tell Redpanda what piece of code (.wasm) can run on what data (topics), on what location, at a specific time (on event triggers) in an auditable fashion.
In other words, the Redpanda controller can tell you exactly what code is touching what piece of data, on what computers, and at what offsets.
The most exciting part about sharing this feature is that Redpanda Data Transforms complements the existing tooling and frameworks you already have in the enterprise. It simply inverts the relation of shipping data to compute by shipping code to data.
Check out our post on how Redpanda Data Transforms compares to Apache Flink to learn how they compare and when to use them.
The architecture of Redpanda Data Transforms is composed of three important components:
Redpanda Data Transforms provides a simple experience to transform your data. You simply write a function that takes a record in, and then you write back out the transformed records. Redpanda takes care of storing and managing the code, running the code, moving data around, and providing metrics and logs. We've baked a full development experience into rpk, our development tool.
rpk transform init will generate a getting started template. You don't need to use the scaffolding, but rpk takes care of all the boilerplate so you can focus on getting the job done.
Our SDKs allow you to focus on modifying each record as it's written to the input topic. Once you've written your transformation, you can build it to WebAssembly using rpk transform build.
Here’s an example of a transformation that redacts a single field from a JSON record.
// This example shows a transform that removes a
// sensitive field from a JSON object.
func main() {
transform.OnRecordWritten(redactJson)
}
type RecordPayload struct {
UserName string `json:"username"`
Email string `json:"email"`
Purchase TransactionInfo `json:"purchase"`
}
func redactJson(e transform.WriteEvent, w transform.RecordWriter) error {
var payload RecordPayload
if err := json.Unmarshal(e.Record().Value, &payload); err != nil {
return err
}
payload.email = "" // Remove sensitive field
b, err := json.Marshal(e.Record().Value)
if err != nil {
return err
}
return w.Write(transform.Record{
Key: e.Record().Key,
Value: b,
})
}Data Transforms can be deployed in one command using rpk transform deploy --input-topic=foo --output-topic=bar.
To see the deployed transforms running in the cluster as well as their status and if there’s any lag, you can use rpk transform list.
All of these commands use Redpanda's Admin API and are auditable events. Once a transform is deployed, Redpanda stores the metadata and binary internally with other cluster metadata.
After that, any core that becomes the Raft leader for a partition on the input topic will also spin up a WebAssembly Virtual Machine (VM) with the code deployed to run your transformation code. If the Raft leadership changes, we stop processing records, persist the latest offset that was processed, and then start the Wasm VM on the same core as the new leader.
With the Raft leader and your code running on the same core, we can easily process records by reading from the local Raft leader's log and pushing those through the WebAssembly VM — and your code.
The resulting records are directly written to the Raft leaders for the output topic that you specify at deployment. If the output leader is on another broker, we use our internal Remote Procedure Calls to write these records, bypassing the Kafka API, and writing directly to our internal Raft layer.

While these transforms are running, we periodically commit the offset of the records that have successfully processed in the input topic. This allows us to resume processing in the correct place if there are failures, crashes, or redeploys. This is similar to using consumer groups in the Kafka API, except it's all transparently handled for you, so you can focus on the task at hand.
WebAssembly will change server-side software permanently. Allowing injection of code inside Redpanda at strategic points fundamentally changes what the storage engine can do for you while giving you isolation, high function density, granularity of execution, native performance, and multi-tenant by design — all in your favorite programming language.
Currently, Redpanda Data Transforms is a beta feature for Redpanda Cloud's Dedicated and BYOC options. If you’re a developer fascinated with hacking low-latency storage systems, we’d love to know more about you, so check out Redpanda's open engineering jobs!
To learn more about running data transformations with Wasm, here are a few handy resources:
Lastly, follow us on LinkedIn and X to catch our upcoming product updates!
You can't scale what you can't trust. A governance layer fixes that.

Your lakehouse mirrors the database, instantly.

What is it, why enterprises need it, and how to evaluate one
Subscribe to our VIP (very important panda) mailing list to pounce on the latest blogs, surprise announcements, and community events!
Opt out anytime.