





Full CDC semantics land in the Iceberg output for Redpanda Connect
Your lakehouse mirrors the database, instantly.

Learn how they compare, their benefits, and potential use cases








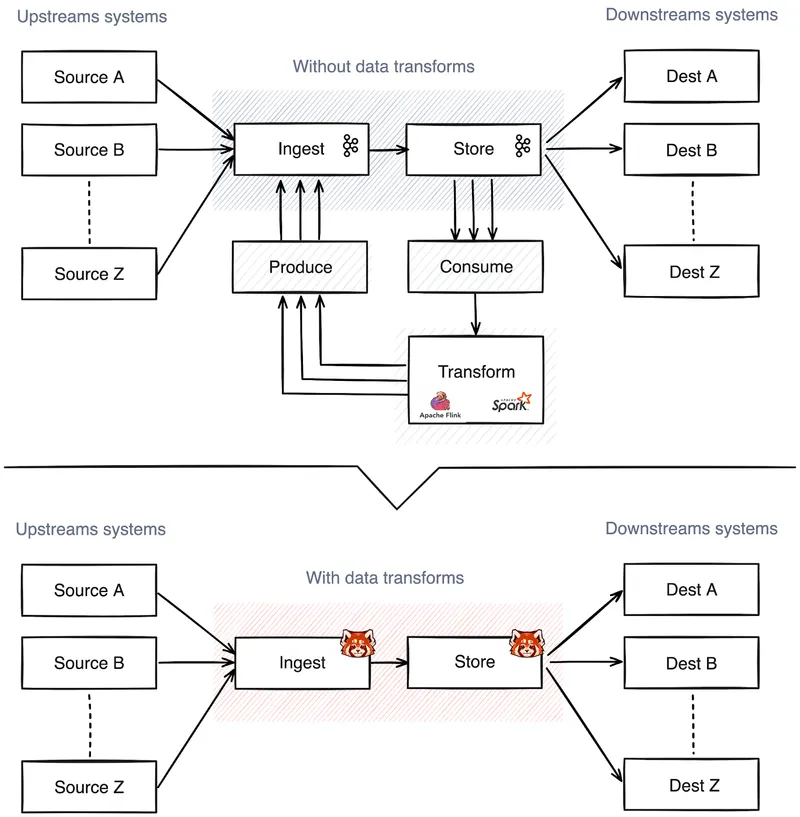
Transforming a data stream usually requires an external consumer, like a stream processor or an event-driven microservice. This leads to the data first being transferred from the event broker to the consumer and then returned to the broker after transformation. No matter how simple or complicated the transformation is, this data ping-pong results in added latency, increased networking costs, and complex stream processing pipelines.
Here’s where in-broker data transformations step into the limelight, enabling stateless transformation functions like filtering, scrubbing, and transcoding to execute within the broker itself, entirely eliminating the need to move data between external systems.
Apache Flink® is a popular choice for both stateless and stateful stream processing. However, Redpanda recently announced the public beta of Data Transforms, powered by WebAssembly (Wasm), for simpler and less expensive in-broker data transformations.
In brief, Redpanda Data Transforms allows developers to read data, prepare messages, and make API calls without the “data ping pong” for more cost-efficient pipelines and improved data quality for downstream consumers.
Naturally, those working with stream processing workloads are wondering what distinguishes the two technologies and when to use them. Let’s compare Redpanda Data Transforms and Apache Flink across their best features, along with potential use cases and benefits.
Choose Flink if your transformations are stateful. A state is maintained across multiple invocations. For example, when counting the occurrences of different types of events in a topic, it must keep counters in the state and also ensure the state is fault-tolerant.
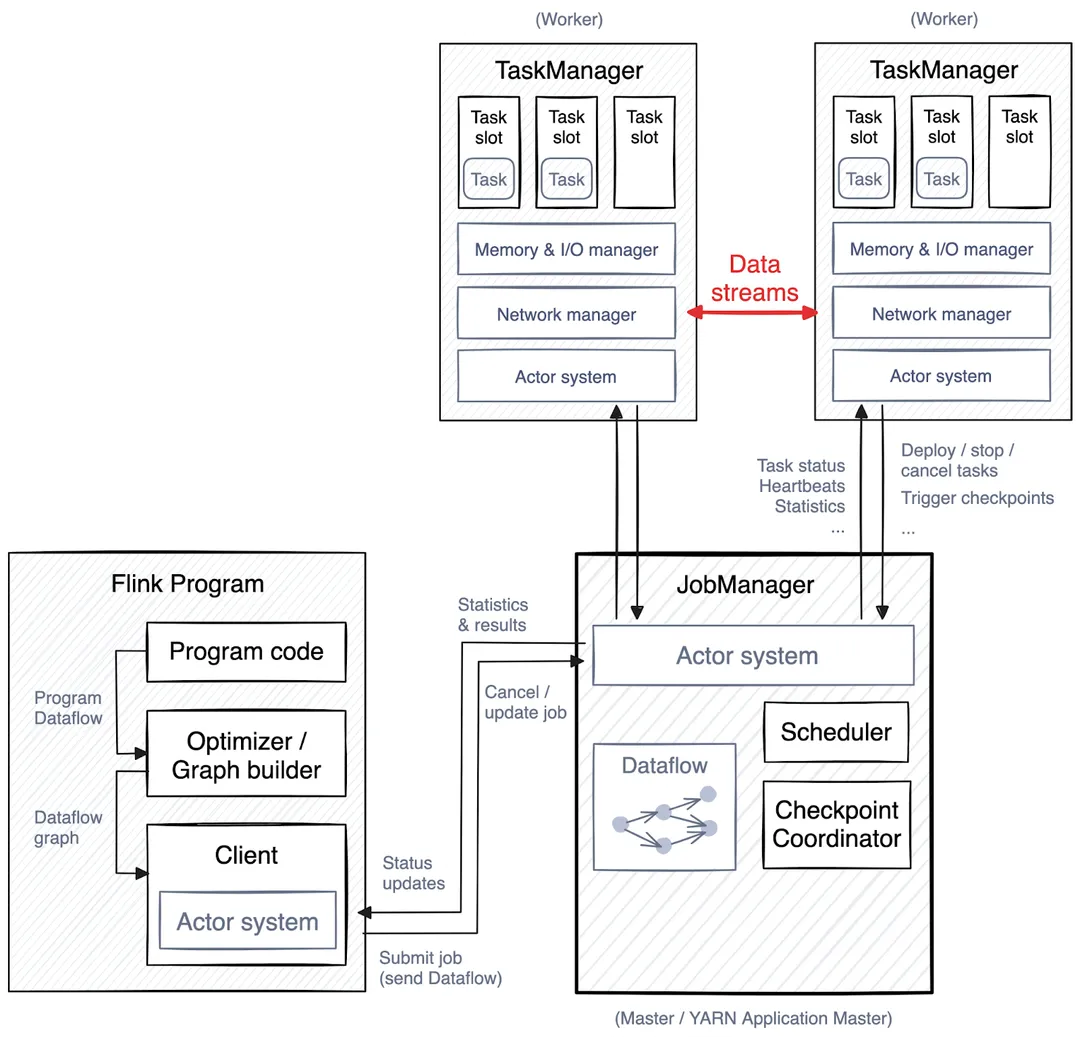
Flink excels at stateful stream processing on unbounded streams, which involves aggregations, joins, window operations, and event time processing. If your transformation belongs there, Flink is your best choice.
Choose Flink if your transformations want to read from and write to external systems, such as databases, services, and file systems.
At the time of this writing, Redpanda Transforms doesn’t support making network calls or accessing the local disk. So Flink and its rich connector ecosystem come in handy, especially if your transformation is data-intensive.
Choose Redpanda if your transformations are stateless. This means the processing of an event does not depend on any events seen in the past, and no history is kept. Stateless transformations are self-contained and the output is purely a function of the input data.
Redpanda Data Transforms is ideal for the following transformations:
Choose Redpanda if the processing latency of transformations is critical and you absolutely need real-time processing. This is because Redpanda transformations are executed in-process — near where the data resides — reducing the processing latency as there’s less data transfer across the network.
Moreover, stateless transformations lend themselves to parallelization. Since each event can be processed independently, multiple events can be processed simultaneously across multiple processing units or threads. This parallelization can lead to significant performance improvements, especially on multi-core or distributed systems.
Choose Redpanda if you want to give developers the freedom to pick their preferred language for the transformations.
Each transformation is deployed inside a WebAssembly (Wasm) engine inside a Redpanda broker. Wasm allows developers to write code in languages like C/C++, Rust, and other high-level languages like Python or TypeScript, and then compile them into Wasm bytecode. This bytecode is then distributed across a Redpanda cluster and deployed.
As of this writing, Redpanda supports Wasm transformations with Go and Rust. The support for C++ and Javascript is well underway, while adding Kotlin later is in the plans.
Despite Flink's support for polyglot programming with Java, Scala, and Python, Wasm offers a broader range of options while providing performance, portability, security, and flexibility.
Flink is a distributed system that requires additional resource provisioning, monitoring, and staffing. Sometimes using such a system for a trivial task, such as redacting a password, can be overkill.
In conclusion, Apache Flink is a great choice if most of your workloads are stateful and embody complex processing logic, such as event time semantics, state fault tolerance, and large-scale aggregations. If your transformation use case is stateless, latency sensitive, and you want to operate with cost efficiency in mind — go with Redpanda Data Transforms.
For example, if you’re kicking off a streaming data project and your requirements are simple, like masking a PII field or a JSON to CSV conversion, you might not want to manage an external distributed system just for that.
If you’re still not sure or have a different question, ask away in the Redpanda Community on Slack.
Originally published on The New Stack.
Subscribe to our VIP (very important panda) mailing list to pounce on the latest blogs, surprise announcements, and community events!
Opt out anytime.

