




Drag, drop, done: a visual composer for Redpanda Connect
Boxes and arrows for people who move billions of events a day. No per-row invoice required.

New capabilities to reduce storage costs, increase data safety and improve security








Redpanda 22.3 introduces enhancements designed to reduce the Total Cost of Ownership (TCO) of your streaming data environments. It includes features to increase data safety, improve security, and reduce the complexity in operating Kafka workloads. The update introduces unified retention controls and a "cloud-first" tiered storage facility. It also brings transactions into general availability with a 10x throughput improvement, self-healing multi-AZ data balancing, and uniform security across all Redpanda endpoints.
Redpanda 22.3 brings better support for securing critical services, extending access to HTTP clients, and improvements to simplify day-to-day security and operational hygiene. It enables a consistent security profile with AuthN+TLS everywhere. With support for HTTP basic authentication added to both the HTTP proxy and the schema registry services within Redpanda clusters, HTTP clients can now use Redpanda securely and uniformly. It also introduces user and access management in Redpanda Console and ephemeral credentials for HTTP Proxy and Schema Registry.
Redpanda 22.3 brings Kafka transactions to general availability. Transactions are part of Apache Kafka and enable "exactly-once" semantics to help ensure guaranteed delivery of messages for applications with these requirements. Using transactions with Redpanda provides between 2x and 10x more throughput with the same latency as Apache Kafka. If a transaction cannot be completed and is aborted, the failure is clearly visible to the client, who may then retry the transaction to ensure delivery.
In Redpanda 22.3, the cloud is the default storage tier for Redpanda clusters. Administrators and application developers can apply standard Kafka data retention properties to customize the data retention behavior. The Redpanda platform manages the data archival, uses read-ahead caching & bulk transfers to protect latency and two-level indexing to maintain optimal performance at scale. This enables access to infinite data storage, without complexity and without breaking the bank.
Redpanda 22.3 is here! Today, we’re excited to bring you new enhancements designed to significantly reduce TCO of your streaming data environments as well as several features to increase data safety, improve security, and further reduce the complexity in operating your own Kafka workloads.
New unified retention controls combined with Redpanda’s tiered storage architecture, enable a “cloud-first” tiered storage facility that makes the public cloud the default data storage platform for all your streaming data, and yes, of course, compacted topics included. Additionally, 22.3 brings transactions into general availability with a 10x throughput improvement, self-healing multi-AZ data balancing and uniform security across all Redpanda endpoints.
Redpanda 22.3 delivers game-changing cost performance, reducing storage costs by up to 10x
Amazon’s S3 has evolved from a pioneering ‘utility computing’ innovation in 2006 into the de facto standard for separating compute from storage in applications, and the reference protocol for the implementation of both hyperscale cloud storage services and on-premise storage appliances. It’s no longer acceptable for any storage or data infrastructure vendor to lack S3 protocol support or to collocate compute and storage and remain competitive. Redpanda is no different. How we leverage S3, however, is a space where significant innovation is happening in Redpanda around this transformative technology.
Redpanda launched tiered storage in 22.1 to give developers unified access to both real-time and historical data, using a common (Kafka) API and without inflating the cost of data storage. Built on our unique Tiered Storage technology, the initial tiered storage capability archived topic data to cloud object storage and transparently managed data retrieval for Kafka consumers. However, the lifecycle of the data in tiered storage had to be managed separately from that of the data stored locally in a cluster’s storage volumes.
With 22.3, the cloud is the default storage tier for Redpanda clusters. Administrators and application developers can apply standard Kafka data retention properties to customize the data retention behavior. Thus, existing applications can be deployed unchanged, while leveraging cloud storage transparently. Behind the scenes, the Redpanda platform intelligently manages the data archival, uses read-ahead caching & bulk transfers to protect latency and two-level indexing to maintain optimal performance at scale, enabling access to infinite data storage, without complexity and without breaking the bank.
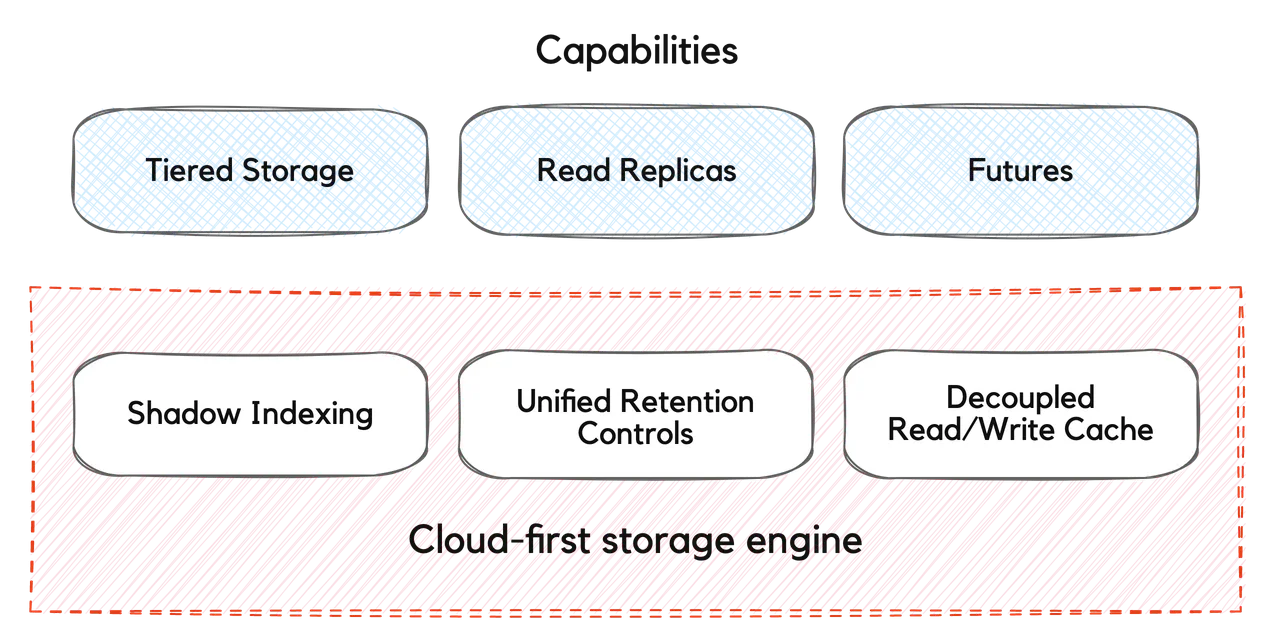
Redpanda’s cloud-first storage engine stores even actively used topics_ fully self-contained and portable_ in cloud storage services, making this data available for a variety of purposes such as tiered storage, remote read replicas and disaster recovery, regardless of whether the original cluster is still running. It will also enable future advanced use cases such as migration to other clouds, and curation for downstream applications, making this architecture flexible and future-proof.
Consequently, developers can design and build applications that are free from constraints imposed limits of locally attached storage and the costs of remotely attached storage volumes, while preserving fine-grained control of local data placement with topic-level overrides if desired. Meanwhile, cluster administrators are freed from housekeeping tasks such as manually purging cloud storage of expired data and deleted topics.
Got you excited? Check out the documentation for our updated tiered storage capabilities here.
Who wants 10x more throughput? Anyone? I thought so….
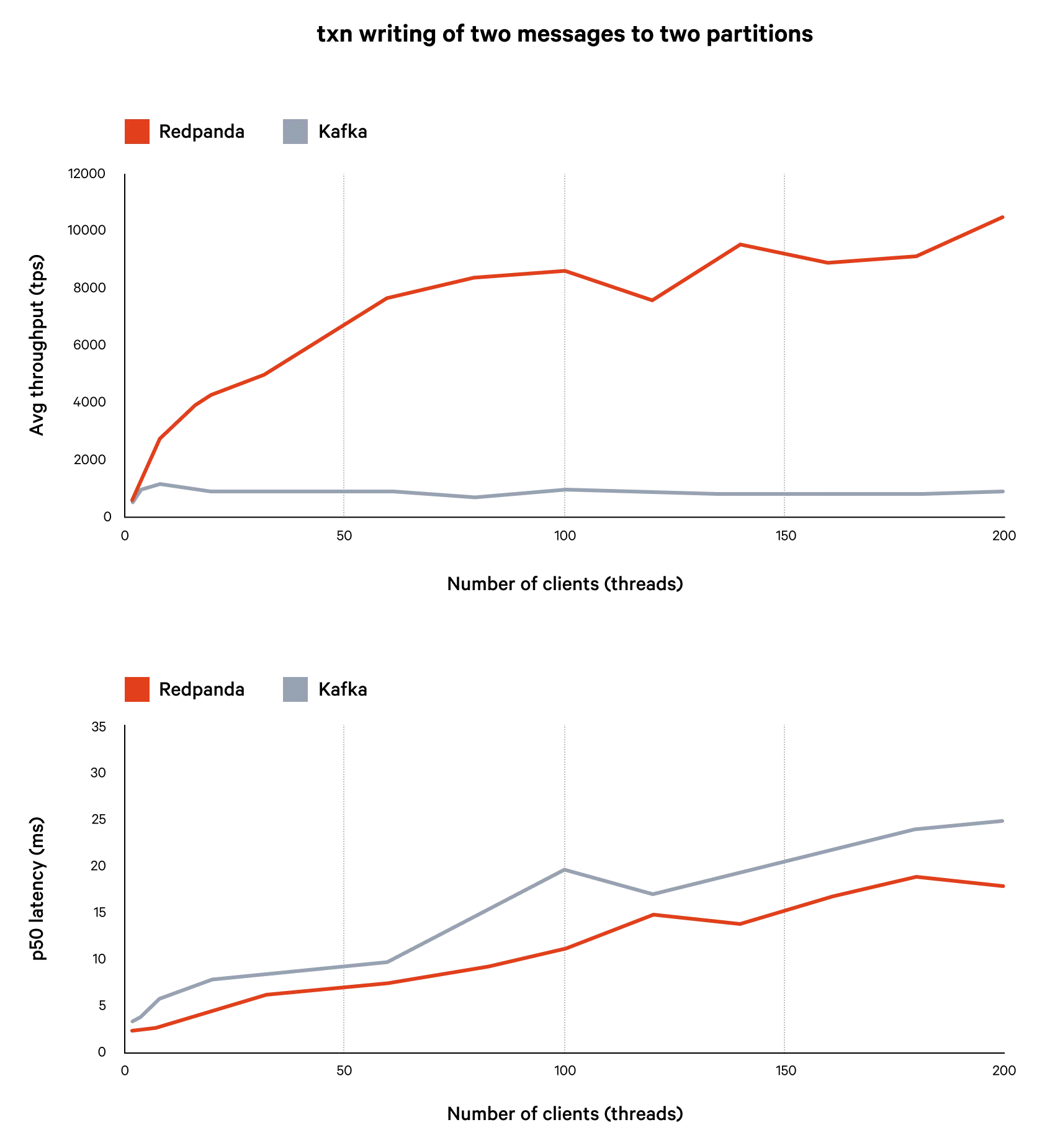
In release 21.8.1 we released a technical preview of the Kafka transactions API in Redpanda. Redpanda 22.3 brings this to general availability. Transactions are part of Apache Kafka and enable "exactly-once" semantics to help ensure guaranteed delivery of messages for applications with these requirements. More impressively, Redpanda delivers transactions without sacrificing performance. In fact, using transactions with Redpanda provides between 2x and 10x more throughput with the same latency as Apache Kafka.
Specifically, in 22.3 we're adding support for KIP 360, KIP 447, support for compacted topics, as well as additional robustness improvements to maintain smooth application behavior.
With transactions enabled, If a producer sends messages to one ore more partitions and issues such as network connectivity or broker failure cause the producer to retry the sending, Redpanda will guarantee that all messages in the transaction are written exactly once, making the operation atomic. If the transaction cannot be completed and is aborted, the failure is clearly visible to the client. The client may then retry the transaction to ensure delivery. Transaction support builds upon Redpanda’s idempotent producer support to help enable applications provide end-to-end delivery guarantees.
Also in 22.3 is new support for continuously self-healing multi-rack/multi-AZ Redpanda clusters. Previously, multi-rack clusters distributed data evenly across failure domains during normal operations, but did not ‘catch up’ replication after rack or availability zone outages ended. In 22.3, rack-aware replication continuously attempts to achieve durability guarantees, even for data that arrived during HW/AZ failures by triggering data balancing and treating rack/AZ data distribution as a ‘hard constraint'. This enables you to meet the most stringent of data safety guarantees, without exception.
Redpanda 22.3 also brings better support for securing critical services, extending access to HTTP clients, as well as improvements to simplify day-to-day security and operational hygiene.
Redpanda 22.3 enables a consistent security profile with AuthN+TLS everywhere. With support for HTTP basic authentication added to both the HTTP proxy (‘pandaproxy’) and the schema registry services within Redpanda clusters, HTTP clients can now use Redpanda securely and uniformly, enabling you to bring streaming data to more applications within your environment. Users of the HTTP proxy (also known as the “pandaproxy”) were previously anonymous, granting access to all cluster resources, whereas now they are recognized as a unique Kafka user (after supplying a valid username/password). This enables authorization policies ( Kafka ACLs) to be applied to p HTTP clients.These policies can be easily managed via the Redpanda Console! With Basic authentication for Schema Registry, only known Redpanda users supplying a valid password can connect to the Registry, further protecting potentially sensitive metadata.
As an extra layer of convenience, Console introduces the UI way of managing users and associated access policies (Kafka ACLs). Instead of browsing the respective ACLs, Console provides a single pane where admins can view permissions and make adjustments with a couple of clicks. Read more about the user and access management in our blog.
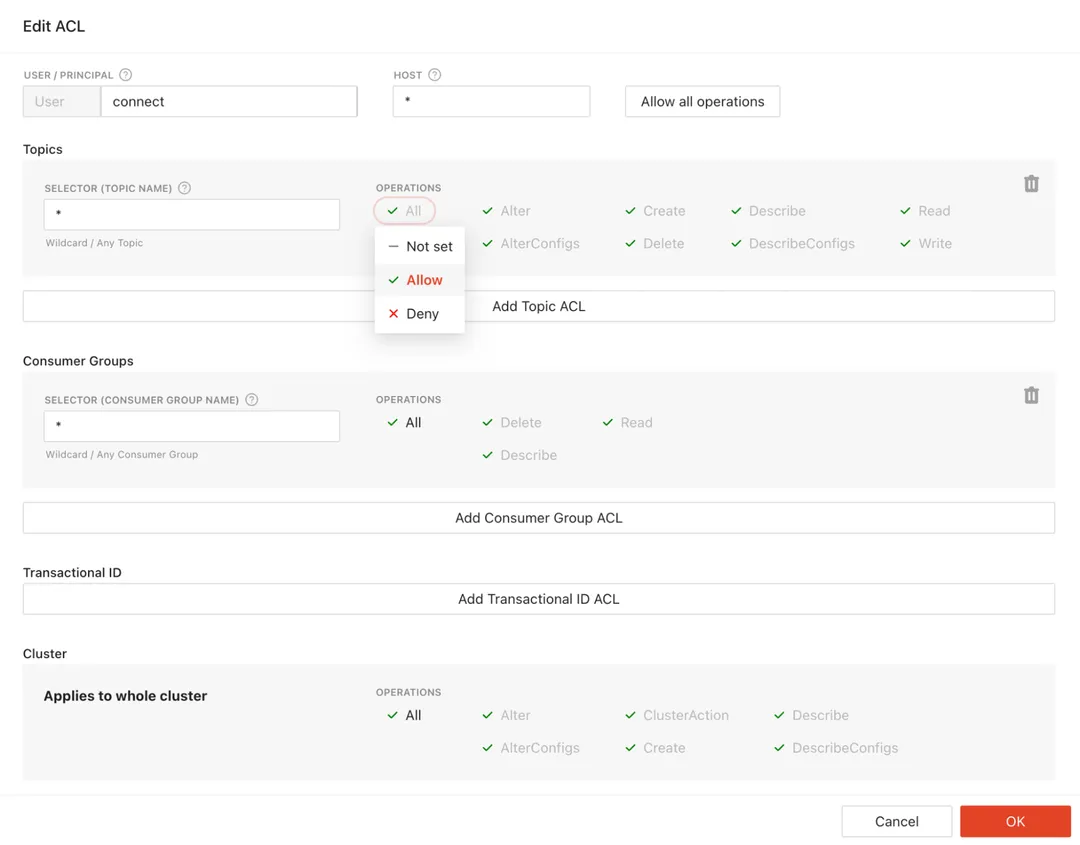
22.3 eliminates the need for service credentials for HTTP Proxy and Schema Registry to be baked into configuration files. In previous editions, both the http proxy and schema registry services communicated with the message broker using service accounts, with credentials stored in configuration files. With 22.3, these services auto-generate service credentials with random usernames and passwords, and then securely share a copy of the usernames and hashed passwords to other nodes. This way the services can authenticate as before with service credentials, but without user involvement. When the node is added or restarted the credentials are regenerated and updated transparently. This eliminates the need for any explicit configuration steps to enable proxy/registry services, alleviate security concerns about storing credentials in plain text, and rotate credentials on restart. Overall, ephemeral credentials improve security hygiene and reduce the chance of a failed security scan/audit.
Redpanda 22.3 eliminates “root” nodes and nodes are configured without IDs, harmonizing configuration and dramatically simplifying configuration management and cluster provisioning /repairing/scaling workflows. Previously, clusters formed consensus via a ‘root’ node and ‘seed servers’, with unique IDs per node. This could lead to heterogeneous configuration, confusion, and ‘split brain’ cluster creation. 22.3 simplifies the out-of-box experience for multi-node deployments, and makes it simpler for you to operate Redpanda clusters._ Importantly, while pre-22.3 node configurations will still work, deployment automation scripts will need to be updated to take advantage of the new approach and the robustness it provides_.
Last but not the least, 22.3 provides hundreds of bug fixes and other minor improvements, like the ability to change the replication factor of existing topics via RPK, making it easy to up/down replicate based on the desired level of data durability per topic. Please check out the release notes for more details on other improvements and fixes in 22.3.
Redpanda 22.3 is available today, complete with the docs! You can request a free trial for the Enterprise Edition or grab the Community Edition from our GitHub repo.
Questions? Contact us.
Boxes and arrows for people who move billions of events a day. No per-row invoice required.

Solving a Kafka problem to balance batching efficiency against latency and cost
Subscribe to our VIP (very important panda) mailing list to pounce on the latest blogs, surprise announcements, and community events!
Opt out anytime.
