





Full CDC semantics land in the Iceberg output for Redpanda Connect
Your lakehouse mirrors the database, instantly.

Still streaming data like it’s 2011? The world has changed—and maybe your streaming data platform should too.








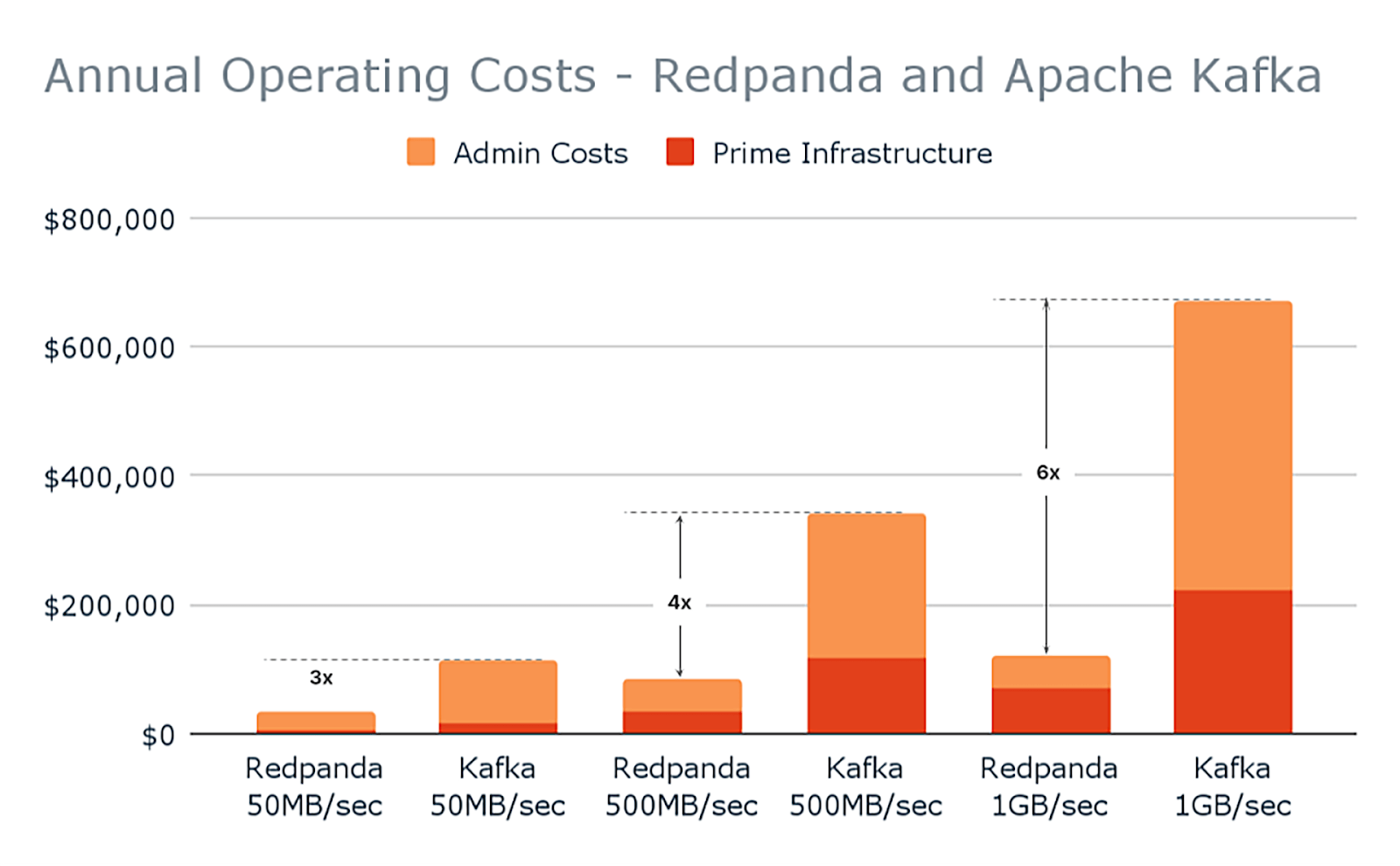
Redpanda's Community Edition is three to six times more cost-effective than running the equivalent Kafka infrastructure and team, while still delivering superior performance. Redpanda Enterprise introduces features designed to simplify operating clusters, potentially saving between $70,000 and $1.2 million depending on your workload and cluster size. This represents a significant saving compared to any commercial Kafka offering.
Redpanda offers operational simplicity, cost-effectiveness, and high performance. It is a self-contained system with built-in schema registry, HTTP proxy, and message broker, eliminating dependencies on JVM, ZooKeeper, or KRaft. This simplifies support and reduces infrastructure costs. Redpanda is engineered to deliver high performance and low latencies, and it is fully Kafka API-compatible, meaning no code changes are needed for your Kafka streaming apps and tools.
Apache Kafka is complex to deploy, use, and scale. It's reliant on page caching and garbage collection which can be problematic, and it brings along extraneous components like JVM and Apache ZooKeeper™, making its management and deployment difficult. Furthermore, Kafka is expensive and limiting. It was designed for an era of slower hardware and lower data volumes, hence it's not optimized for today's powerful CPUs, faster and cheaper disks, and swifter networks.
Redpanda is a Kafka API-compatible streaming data platform built from scratch in C++ that offers significant performance and operational advantages over Apache Kafka. Unlike Kafka, which requires JVM and Zookeeper, Redpanda is a single binary with no external dependencies, making it simpler to deploy and manage. It delivers up to 10x lower latencies and higher throughput while using fewer resources. Redpanda provides 100% Kafka API compatibility, allowing existing Kafka applications to work without code changes. Key differentiators include built-in Schema Registry, automatic data balancing, native Tiered Storage for cost-effective data retention, and WebAssembly support for inline data transforms. While Kafka pioneered the distributed log architecture, Redpanda modernizes it with a thread-per-core architecture that eliminates garbage collection pauses and provides predictable performance. Redpanda also offers enhanced security features, simplified operations with no ZooKeeper dependency, and significantly lower total cost of ownership due to its resource efficiency.
Apache Kafka, while once a streaming superpower, has become synonymous with complexity. It's difficult to deploy, use, and scale. Kafka's original design limits the performance you can get from modern hardware, and its reliance on page caching and garbage collection can cause issues. Running Kafka at scale can be challenging due to the infrastructure required for Kafka brokers, ZooKeeper, schema registry, cruise control, and storage for historical data.
Jump back to 2011: Netflix was shifting from DVDs to streaming, Google+ was still around, and you’d occasionally spot someone holding a Windows Phone.
It was also a different time for engineers. Affordable, high-performance hardware was still a distant dream; a terabyte (TB) of SSDs cost thousands of dollars, compared to today's $200 for NVMe drives that are a thousand times faster. Not to mention the idea of disaggregating compute and storage to boost scalability and cut costs—a hallmark of today's cloud-native world—was not yet the norm.
Cloud computing infrastructure was also significantly more rudimentary a decade ago. Today, you can provision a 225-core vCPU virtual machine (VM) and get 20 times more than what you would’ve gotten from the same cloud provider back in the day.
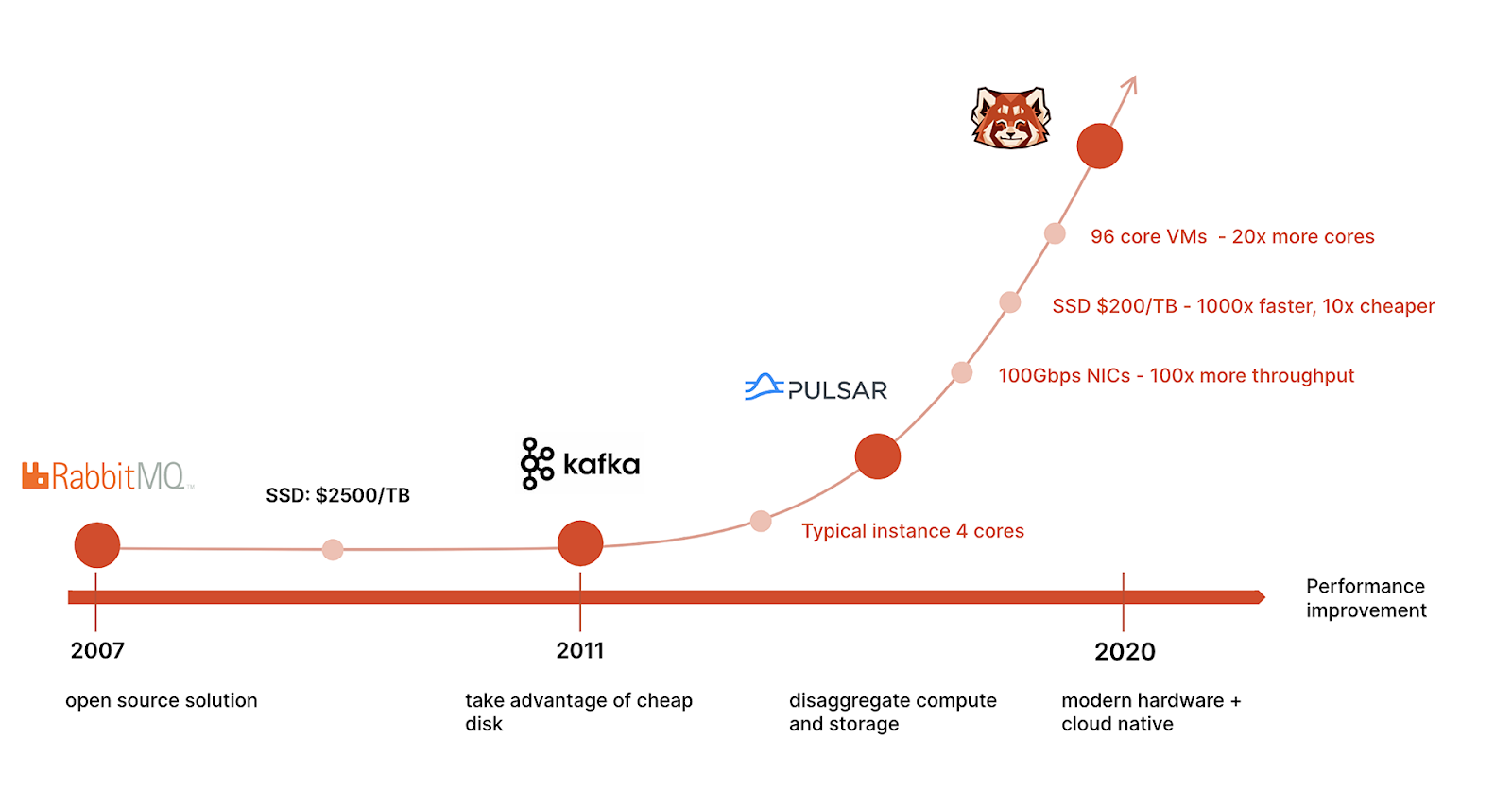
It was also a time when data was a relatively low-volume stream. A TB was a "big deal". The primary focus was simply managing these data streams, and the requirements were nowhere near as demanding as they are now.
The software solution that ruled this era? Apache Kafka®—a distributed publish-subscribe system open-sourced by LinkedIn that was designed to take advantage of low-cost commodity spinning disks through virtualization. Its popularity exploded, and the Kafka API ecosystem spread to every layer of the data stack. Most data software and services today come pre-wired to talk to Kafka. And, with 80% of the Fortune 100 using it, Kafka continues to hold the crown as the go-to streaming data platform for many.
But times have changed, and so have our needs.
Kafka was what we needed at the time, but today’s global, mobile, AI, and edge applications need to process up to trillions of events per day—and Kafka simply can’t keep up. Organizations with ultra-intensive data requirements are now looking for faster, leaner alternatives that they can easily scale without straining their budget or sending their ops team into a meltdown.
Here’s how Kafka pulls back on the reigns of modern data streaming.
Let’s get real—Apache Kafka is cumbersome. What once was known as a streaming superpower is now synonymous with complexity on every level.
Kafka's original design puts a cap on how much performance you can squeeze out of modern hardware. Its reliance on page caching and garbage collection can be problematic, and let's not even start on the deployment and management issues—courtesy of the extraneous components it drags along, like JVM and Apache ZooKeeper™.
This makes running Kafka at scale harder than it needs to be. The infrastructure for Kafka brokers, ZooKeeper, schema registry, cruise control, and storage for historical data stacks up quickly. Add on the complexities of administering the JVM environment, and you have yourself your very own nightmare.

Now imagine managing all of those different components in a multi-region cloud deployment, or in a supercluster on-premises with thousands of partitions. (Your hair likely turned grey just at the thought.)
Running Apache Kafka at scale is a serious drain on resources. Try breaking the 1GBps throughput barrier with it and see for yourself. We gave it a shot, and documented our findings in this Redpanda vs. Apache Kafka: A Total Cost of Ownership comparison report.
The complexity of managing additional components doesn’t just make Kafka tedious at scale, but also unreasonably expensive.
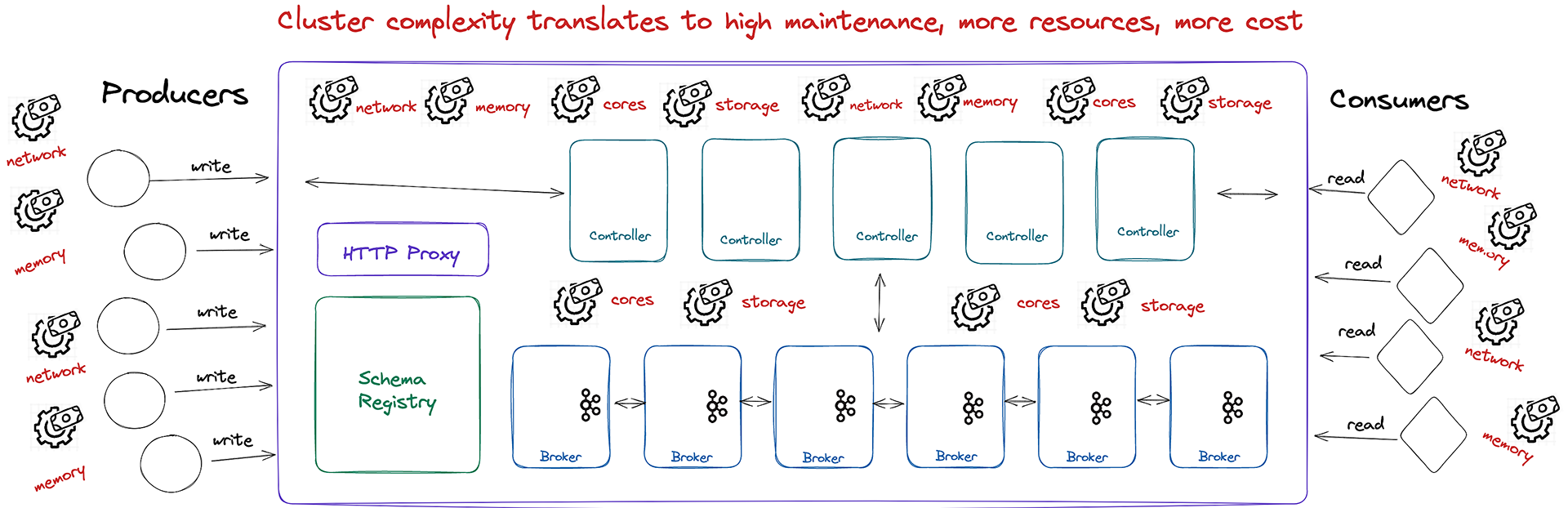
This is because Kafka was designed for an era of slower hardware that was expected to manage a significantly lower volume of data. It's simply not optimized to take full advantage of today's more powerful CPUs, faster and cheaper disks, and swifter networks. Its architectural roots make it clunky.
To its credit, Apache Kafka has been busy making amends to its architecture to alleviate some of these problems—like replacing ZooKeeper with KRaft. Naturally, we ran yet another benchmark to check whether Redpanda is faster than Kafka with kRaft. (Spoiler: it is.)
This is where Redpanda comes in. It's a streaming data platform built from scratch to be a faster, easier, cost-effective alternative to Kafka. It couples blazingly fast performance with operational simplicity, and flaunts a lean, modern design that was engineered to meet the demands of today's data-driven, cloud-native world.
So, when do you choose Redpanda over Kafka?
The simple answer is “always.” Here’s why.
Redpanda is a self-contained, single binary. Schema registry, HTTP proxy, and message broker are all built-in. That means no JVM, ZooKeeper, or KRaft dependencies.
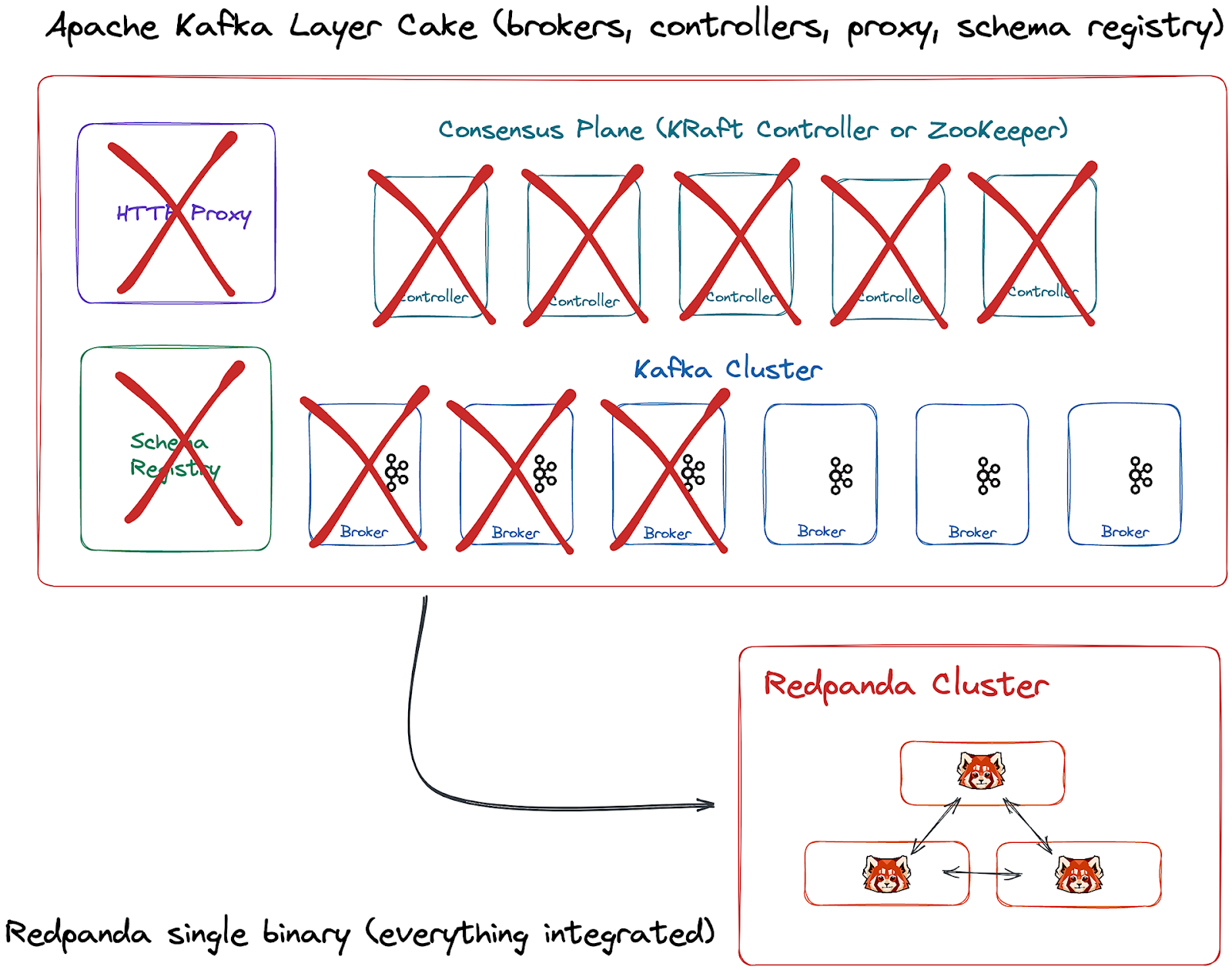
This simplifies support and reduces infrastructure costs, whether you're running Redpanda on your own infrastructure or as a fully-managed cloud service. It also keeps your cluster in its optimal state by using native anti-entropy mechanisms to intelligently redistribute data partitions, which is typically a manual task in Kafka.
Furthermore, you get rpk—a dev-friendly CLI—as well as Redpanda Console, a simple but powerful web UI for visibility into data streams.
You can almost hear the collective sigh of relief when we tell developers how easy Redpanda is to use, manage, and scale. The best part is that Redpanda is fully Kafka API-compatible. You can just drop it in and the default configuration will work with all your Kafka streaming apps and tools. No code changes needed.
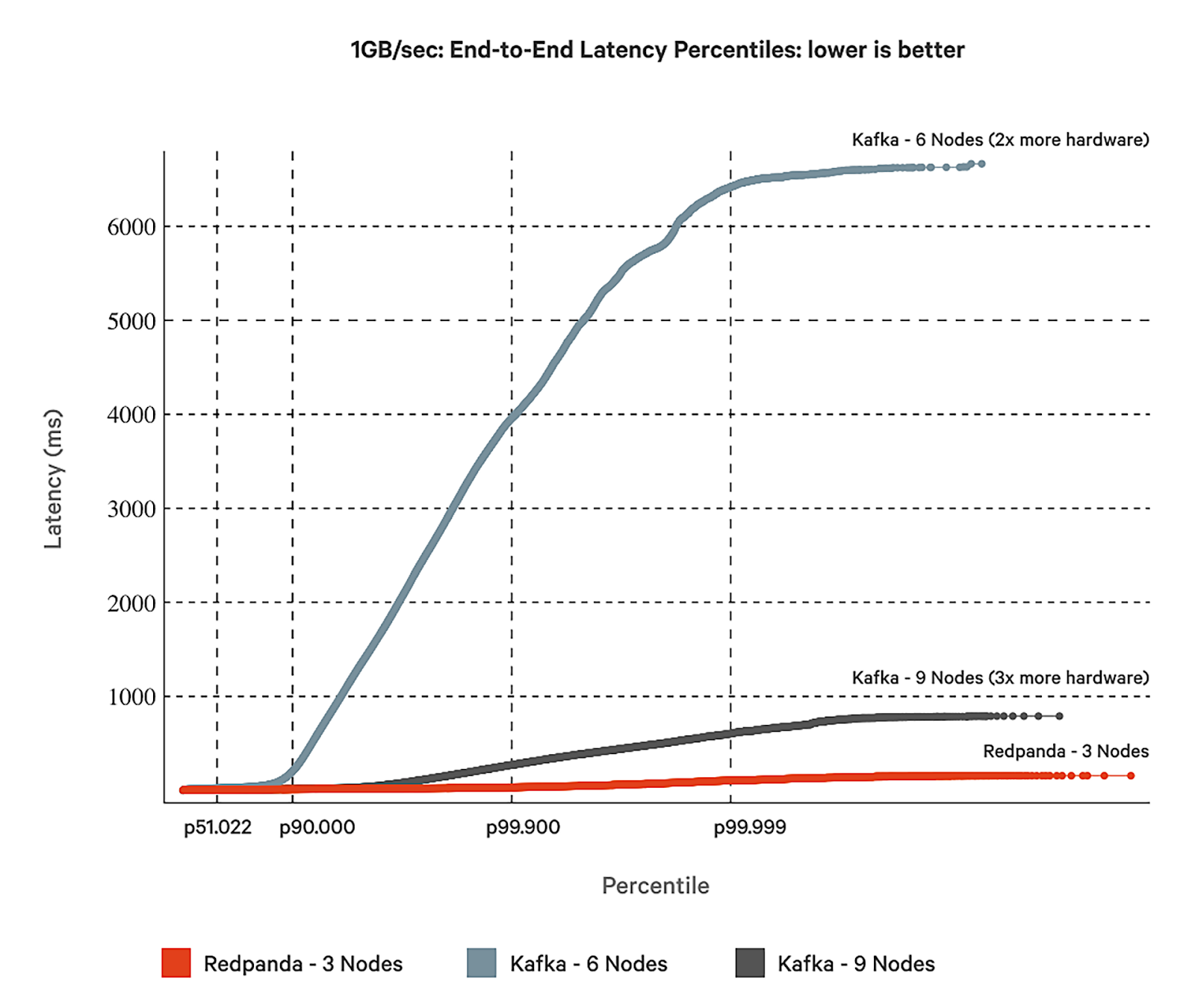
Redpanda is engineered in C++ with a thread-per-core architecture to squeeze the most out of your resources, keep latencies consistently low, and deliver throughputs that range in GBps+ on the smallest of hardware footprints. After more than 200 hours of testing, we proved that Redpanda runs seamlessly on both x86 and ARM-based hardware, outperforming Kafka at tail latencies (p99.99) by at least a factor of 10.
As for cost, Redpanda’s source-available (and free) Community Edition is between three to six times more cost-effective than running the equivalent Kafka infrastructure and team, while still delivering superior performance.
Redpanda Enterprise introduces several features designed to simplify operating clusters, potentially saving you between $70,000 and $1.2 million depending on your workload and cluster size. That's a significant saving compared to any commercial Kafka offering.
Bottom line is: Redpanda deploys in minutes, spins up in seconds, and runs efficiently wherever you choose to develop.
Kafka's rise was meteoric back in the day because it helped organizations achieve their goals faster. It was the engine behind new machine learning models, improved security outcomes, customer engagement, and much more. But we're not in 2011 anymore.
Engineers are being challenged every day to support increasingly demanding service-level objectives. We're dealing with messages processed per second, cluster availability, low latency, and more, for applications that handle gigabytes per second. The landscape has changed, and we need tools that can keep up.
Enter Redpanda. As we find ourselves in the midst of a real-time renaissance, Redpanda ensures that you can accelerate your streaming data workloads. It's fully compatible with the Kafka ecosystem, bringing fresh innovation that lays the groundwork for the data-driven apps of tomorrow.
Don't just take my word for it—see the difference for yourself. The Redpanda source is available from GitHub, or you can request a free cloud trial. If you have questions, ask away in the Redpanda Community on Slack.
Subscribe to our VIP (very important panda) mailing list to pounce on the latest blogs, surprise announcements, and community events!
Opt out anytime.

