





Full CDC semantics land in the Iceberg output for Redpanda Connect
Your lakehouse mirrors the database, instantly.
Learn why we took a single-binary approach to our architecture and how working with a single-fault mode influences usability.








The homogeneous nature of a Redpanda cluster simplifies the process of performing software upgrades. This approach not only makes the upgrade procedure easier for users on bare metal, but also makes it easier for engineers to build reliable automation, such as a Kubernetes operator. While a single-binary approach does not guarantee that all future upgrades are simple, it serves as a set of guardrails to help keep complexity in check.
Redpanda's single-binary approach to packaging eliminates the need to deal with mismatched package versions or missing dependencies during installation. All of Redpanda's dependencies are built from source and statically linked into a single executable, meaning there are no dependencies to consider during installation. This approach also forces a unified view of everything, including documentation, which helps avoid divergent documentation.
Redpanda uses a single-binary approach to software architecture. This means that each node runs the same Redpanda binary and can play one or more roles such as being a data broker and/or an auxiliary service. This approach simplifies deployments and reduces the complexity of managing multiple services on a fleet of nodes.
In the very early days of Redpanda, when we were still focused on proving that we could build an Apache KafkaⓇ replacement, we made an explicit decision to always prioritize user experience. Even though at times, this was at odds with the goal of quickly building out our technology, we knew from past experience and feedback from early adopters that reducing the friction involved in working with distributed systems was a key component in finding product market fit.
Unfortunately, there is no programming language, software library, or universal set of rules to follow that can be relied upon to produce a distributed system that is easy to use. In reality, it is a mixture of many interaction points within an overall product ecosystem that yields a particular experience.
In this post, we are going to examine just one point in the overall design space of our ecosystem and how it affects usability: Redpanda’s single-binary approach to software architecture and the resulting effects of working with a single-fault mode.
The reality of distributed systems is that they contain fundamental complexity that cannot be avoided. We’ve all seen this before: deploying and monitoring multiple services on a fleet on nodes, as well as keeping installed binary versions and configurations synchronized. Of course, a large variety of solutions exist to help tame the situation, but at Redpanda, we didn’t want to depend solely on such tools for a good experience. Instead, we chose to onboard and own this complexity and the resulting experience through a single-binary architecture.
Typical deployments of Redpanda today consist of a cluster of a few nodes (E.g. three to 11 nodes), providing drop-in compatibility for existing Kafka clients. Each node runs the same Redpanda binary and plays one or more roles such as being a data broker and/or an auxiliary service, such as our HTTP proxy or schema registry. Redpanda’s centralized configuration system provides a unified interface for controlling how the cluster operates, including which nodes are configured for which roles.
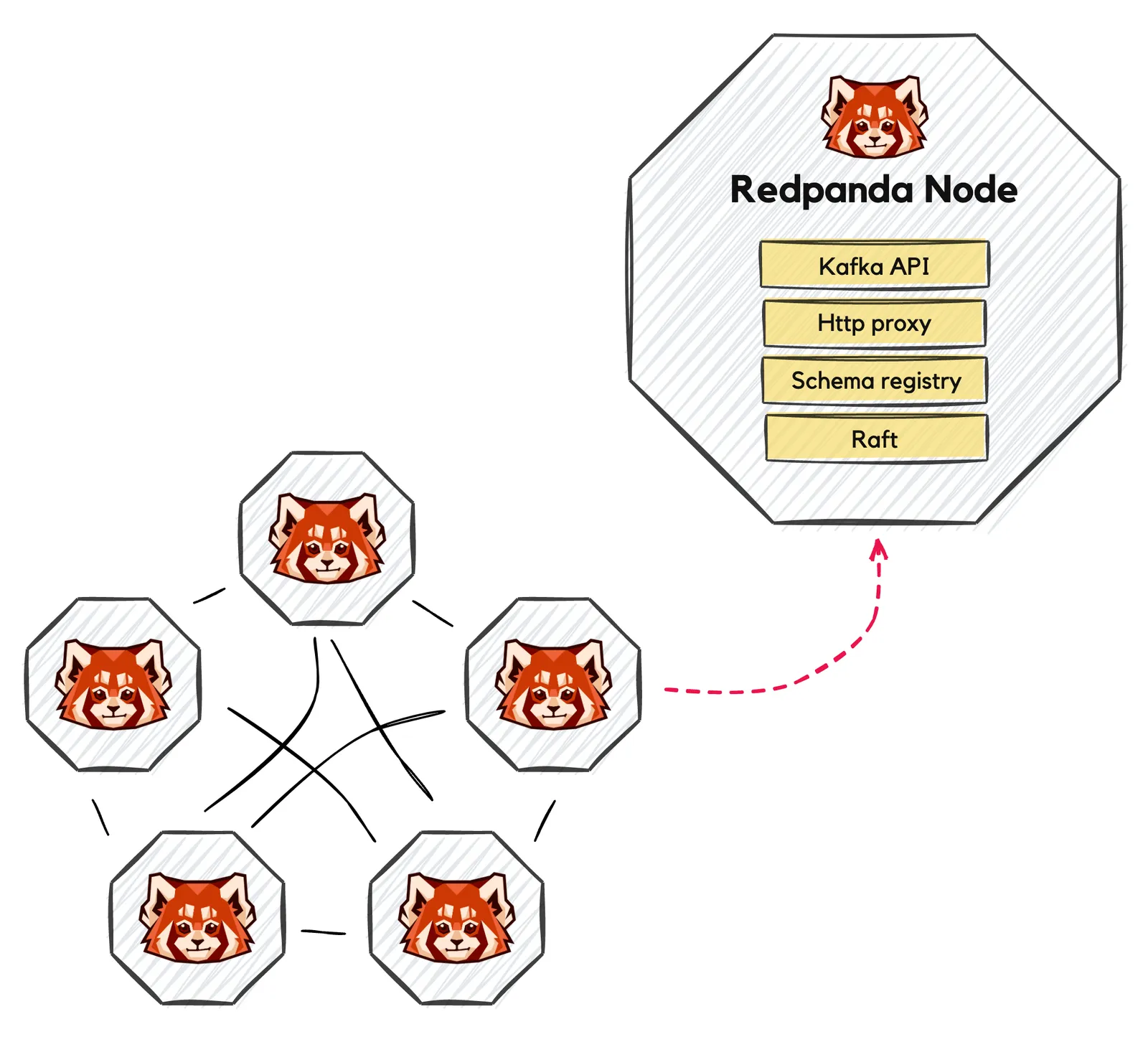
In contrast, a Kafka cluster with similar capabilities may consist of a set of data brokers, an auxiliary ZooKeeperⓇ cluster, and separately deployed resources for REST proxy and schema registry services. Note that with the introduction of KIP-500, Kafka does not depend on ZooKeeper, but deployment recommendations may include separating deployments based on process role.
It may not be immediately clear that a single-binary approach offers benefits over similar systems composed of separate, distinct services. After all, technologies like Kubernetes can hide many of these details. However, for bare-metal installations that forgo Kubernetes, or when issues arise that cannot be automatically handled by an orchestration layer like Kubernetes, the differences in deployment modality are more apparent.
Beyond generic improvements in operational simplicity, a single-binary architecture has technical benefits for several specialized deployment scenarios. Products that require a sprawling ecosystem of separate services have higher resource (E.g. memory) requirements and tend to have more inefficient life cycles, such as starting and stopping multiple interdependent services.
A single-binary approach allows Redpanda to address these issues with tighter control over resource utilization, important for single-machine and edge / IoT deployments that benefit from small footprints. And by making life cycle management more efficient, Redpanda can be used in CI/CD pipelines that benefit directly from faster startup/shutdown procedures.
The benefits of a single-binary approach to packaging begin with the installation experience. Long gone are the days of dealing with apt or dnf complaining about mismatched package versions or missing dependencies. Redpanda and all of its dependencies are built from source (including the compiler) and statically linked into a single executable. This means that there are no dependencies to consider during installation. Each package we ship to you is fully contained and ready to run on your system.
A side effect of shipping Redpanda as a single binary is that it forces us to take a unified view of just about everything. For example, consider documentation. An ecosystem revolving around a single binary with a uniform approach to configuration is effectively a forcing function on avoiding divergent documentation. This isn’t the case when a system is composed of disparate services. For example, ZooKeeper and Kafka are entirely separate projects developed independently, each with its own set of documentation to consume.
And our single-binary approach isn’t something that merely exists at this moment, open to being replaced as soon as we encounter a challenge. We’ve baked the assumption of a single binary into our build system and testing infrastructure. This means that we’ve intentionally made it difficult for ourselves to deviate from this design decision that has become a central component of an experience Redpanda users expect.
It’s important to note that we do not view the single-binary architecture as an all-or-nothing proposition. In reality, a product ecosystem will necessarily involve a variety of distinct components. While this post is concerned with our core data plane service, other components, such as Console, benefit from being separated and have a different set of goals and requirements.
At Redpanda, we have come to expect universally positive reactions when folks learn that we do not depend on ZooKeeper or any external metadata management cluster. The reasoning behind the reaction is simple: managing one distributed system is preferred to managing two. In the best case, those that manage an organization’s infrastructure must necessarily become proficient in the operation of two complex systems. But as installation footprints grow, it is not unheard of for folks to specialize in one system or the other. All of this is to say that improving operational simplicity can lead to direct cost savings in both hardware and ongoing operating costs.
One specific aspect of ongoing management that is simplified by a single-binary approach is the process of performing software upgrades. The homogenous nature of a Redpanda cluster results not just in a simplified upgrade procedure for users on bare metal, but also makes it easier for our engineers to build reliable automation such as our Kubernetes operator. While a single-binary approach does not guarantee by itself that all future upgrades are simple, it serves as a set of guardrails to help keep complexity in check. This is in contrast to a federation of systems whose individual upgrades must be considered along with the overall system upgrade procedure.
A surprising result of developing Redpanda as a single binary was that failure scenarios became easier to reason about, and the observability of the system improved. While these do not directly affect resilience, reduced complexity leads to a more robust development process, systems that are easier to grok and test, and increased visibility simplifies tasks such as health monitoring. All of which, combined, arguably do affect resilience.
Having onboarded inherent system complexity into a single binary, Redpanda has a fault model that is easier to comprehend. We refer to this as a single-fault domain in that node — as a unit of failure – encompasses a slice of all services. This is in contrast to other systems where partial failures of a subset of services are more likely.
An example of this is every Redpanda node in a cluster is a member of a Raft-based internal service, which manages all of the critical system metadata. In many systems such services are factored out of the data plane into a smaller, separate service. This makes sense for systems in which the number of data nodes grows large but is not a problem in Redpanda. This is made possible because of Redpanda’s efficient use of hardware: clusters can remain small while delivering high performance. Since every node is a member of this service, any node is eligible to replace any other node that fails in this role.
When failures and problems do occur, having a unified log and set of metrics has become an invaluable resource for our engineers and support teams. Debugging in the context of other federated systems means investigating across both physical node boundaries and contextual boundaries, all of which introduce additional complexity and hoops that engineers must jump through.
For example, synthesizing insight using metrics and logs from multiple processes (especially from different hosts) is inherently challenging without additional support systems, and debugging the hardest problems often means working in the trenches with raw data.
Finally, the use of a single binary reinforces a high level of internal code reuse. When separate systems are brought together, there is an interest in both the quality of the individual components, as well as the semantics of the correct behavior of the combination of components.
For example, when one distributed system makes use of a separate system for metadata management, there are two independent storage systems in use. Redpanda development emphasizes reuse of hardened subsystems, such as storage, to avoid bifurcation of critical components as much as possible. For instance, brokers in Redpanda use the same storage system and Raft implementation that is also used by our internal metadata management system that powers the cluster controller, which in turn replaces ZooKeeper in a traditional Kafka deployment.
Working within a fast-growing organization like Redpanda Data can place a lot of demand on engineering. But establishing design principles and maintaining a sharp focus on simplicity has allowed our engineering teams to keep up pace without sacrificing quality.
In this post, we’ve discussed a seemingly trivial example of such a guide — single-binary packaging — and shown how its downstream effects have been quite positive for us. In a number of ways, we have simplified installation and deployment management, as well as reduced system complexity and improved observability, all with this one weird trick.
Take Redpanda for a test drive here. Check out our documentation to understand the nuts and bolts of how the platform works, or read our blogs to see the plethora of ways to integrate with Redpanda. To ask our Solution Architects and Core Engineers questions and interact with other Redpanda users, join the Redpanda Community on Slack.
Subscribe to our VIP (very important panda) mailing list to pounce on the latest blogs, surprise announcements, and community events!
Opt out anytime.

