




Full CDC semantics land in the Iceberg output for Redpanda Connect
Your lakehouse mirrors the database, instantly.
Integrate BigQuery and Redpanda to get real-time analytics insights for better decision-making.









Today, every data-centric business—from e-commerce stores to biomedical research firms—depends on data more than ever before. For the modern data-centric business, winning customers and keeping them happy is about quick, targeted actions.
Real-time decision-making is now an integral part of running a successful business, and the recency of the data used for such decisions often dictates the success of the business. Real-time data analytics provide a range of benefits, including tailored recommendations to customers and customer behavior predictions to plan for future demands.
A real-time analytics system requires a platform that can ingest large amounts of events or messages, processing them and storing the results for further analysis. Building such platforms usually involves integrating multiple systems.
For example, a system component may handle data ingestion, another may process the data, and another system may look after storing that data. Some advanced platforms may even provide extra features. For example, a data-storage system may also have a built-in capability to query the processed data.
This article will demonstrate how to build a real-time decision-making system using Redpanda, a real-time data platform, and BigQuery, a serverless data warehouse from Google, without using much code.
Real-time data analytics involves capturing streaming events (i.e., "live" data) from different sources and processing them as quickly as possible to help in decision-making. The processed data is "real" because it's the latest information.
For example, let's consider an e-commerce business. To improve demand planning, the organization wants to report the total page views for each product page in five-minute windows. They can achieve this by streaming all the page view events into a data store and running a query that aggregates page view counts on a rolling five-minute window. Using more analytical queries, the business can see the page view trends over time for each product.
You can implement such a real-time analytics system in two ways:
While the first approach can offer very low latency, the second method is more robust, flexible and easier to implement especially with Redpanda. This is because data warehouses are more familiar, established, have richer SQL support which allows more in-depth analytical features. Additionally, most modern cloud-data warehouses like BigQuery offer unlimited capacity and have been designed for speed. They can store large volumes of streaming data and quickly make it available for analysis. BigQuery's comprehensive SQL support and quick execution times make it a good choice for low-latency, real-time decision-making workloads.
You need three major components to build a real-time analytics system:
Following this tutorial, you're going to build the backend for a dashboard that displays the availability of rooms in a hotel in real time. Your event source will be the booking system (an OLTP application) that sends real-time events when a booking is made or canceled.
You will use Redpanda for the ingestion part. BigQuery will be both the storage layer and the processing engine. Redpanda is a real-time data pipeline that you can think of as a Kafka replacement. With Redpanda, developers don't have to deal with the complex configurations and settings required for Kafka, like JVM tuning, ZooKeeper setup, etc. It's fully compatible with Kafka APIs and can be integrated into a Kafka-based pipeline without any code change.
To connect Redpanda to BigQuery, you will need an intermediary that can translate Redpanda messages to a format BigQuery can understand. For this, you will use the Kafka Connect library for BigQuery. The simplified architecture looks like this:

The following few sections provide instructions for implementing this architecture. (For a detailed tutorial on how to connect Redpanda to BigQuery with Kafka Connect, you can refer to this blog post.)
To start, you will need to have the following resources running and available:
First, you will create a local single-node Redpanda cluster. You can follow Redpanda's documentation to do this, but to get started quickly, run the command below (replace the directory path to reflect your local environment).
docker run -d --pull=always --name=redpanda-node --rm \
-v <PATH_TO_DIRECTORY>/redpanda_integration:/tmp/redpanda_integration \
-p 9092:9092 \
-p 9644:9644 \
docker.vectorized.io/vectorized/redpanda:latest \
redpanda start \
--overprovisioned \
--smp 1 \
--memory 2G \
--reserve-memory 1G \
--node-id 0 \
--check=falseIn your Docker Desktop, you should now be able to see the container running successfully.
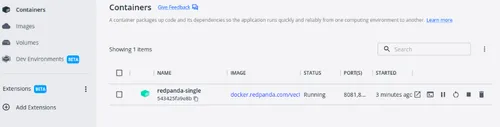
Once the cluster starts running inside the container, you can set up the Redpanda topic.
docker exec -it redpanda-node rpk topic create booking_events
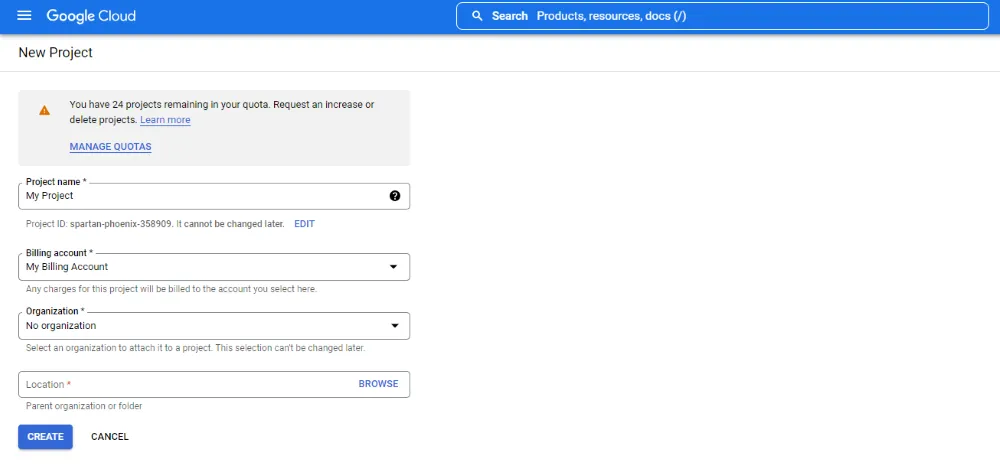
Before creating a BigQuery table, you need to create a new project in Google Cloud Platform. The image below shows the type of information you need to provide when creating a new project in GCP.
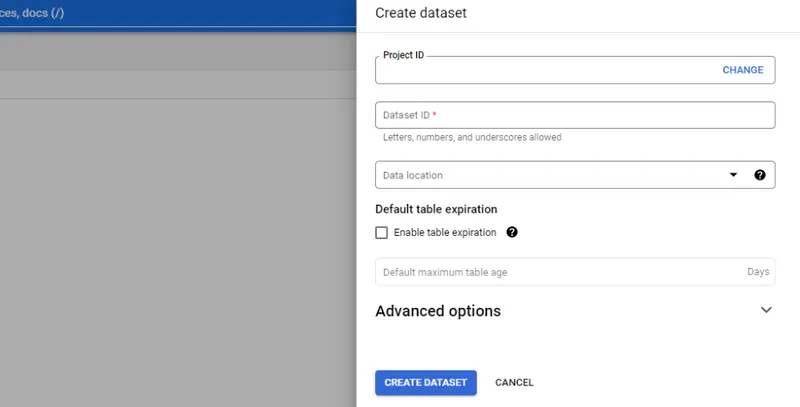
Next, create a data set in BigQuery. The image below shows the information you need to provide:
Next, create a BigQuery table called "booking_table" with the following schema. This table will hold the ingested events from Redpanda.

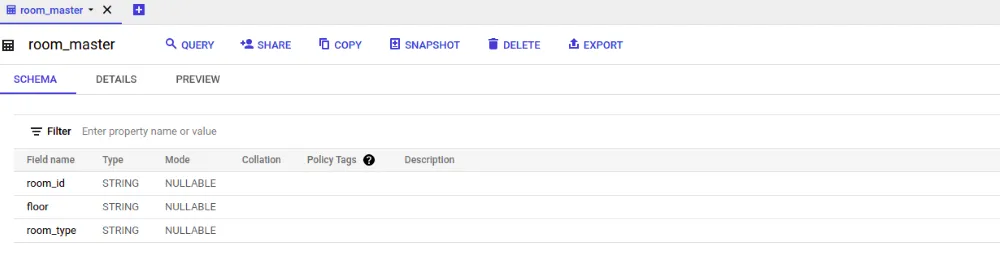
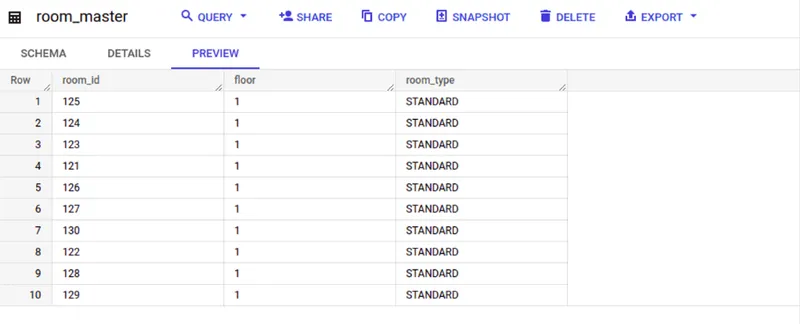
Create another table called "room_master" with the schema below. This table will contain information about the available rooms in the hotel. Later, you'll run a query that joins the bookings_table with the room_master table to find the available rooms.
In BigQuery, run the commands below to load data into the room_master table.
INSERT INTO ‘<project_name>.<dataset>.room_master' VALUES('121','1','STANDARD');
INSERT INTO ‘<project_name>.<dataset>.room_master' VALUES('122','1','STANDARD');
INSERT INTO ‘<project_name>.<dataset>.room_master' VALUES('123','1','STANDARD');
INSERT INTO ‘<project_name>.<dataset>.room_master' VALUES('124','1','STANDARD');
INSERT INTO ‘<project_name>.<dataset>.room_master' VALUES('125','1','STANDARD');
INSERT INTO ‘<project_name>.<dataset>.room_master' VALUES('126','1','STANDARD');
INSERT INTO ‘<project_name>.<dataset>.room_master' VALUES('127','1','STANDARD');
INSERT INTO ‘<project_name>.<dataset>.room_master' VALUES('128','1','STANDARD');
INSERT INTO ‘<project_name>.<dataset>.room_master' VALUES('129','1','STANDARD');
INSERT INTO ‘<project_name>.<dataset>.room_master' VALUES('130','1','STANDARD');The table will look like this:
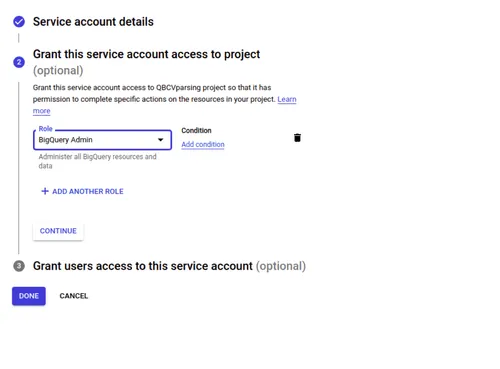
You will now create a service account in Google Cloud Platform to use with Kafka Connect. You should grant the service account BigQuery admin role to keep things simple for this exercise.
Once you create the account, click the ellipsis button beside its name and select the Manage keys option.
From the next screen, create a new KMS key by clicking on the Create new key option, and download the JSON file as redpanda_integration.json.
You will now set up the Kafka Connect cluster. First, download Apache KafkaⓇ from the Apache site and uncompress the file into your working directory.
Next, download the dependency jars for Redpanda and Kafka Connect, unzip the file, and save its contents to a directory. You can call this directory "plugins".
Create a folder called "Configuration" and add an empty file to this directory. Name this file redpanda.properties. Using the code snippet below, specify the Redpanda connection configuration parameters and specify the Redpanda cluster IP and the location of the plug-ins folder in the placeholders shown below:
# Kafka broker addresses
bootstrap.servers=<RED_PANDA_CLUSTER_IP>
# Cluster level converters
# These apply when the connectors don't define any converter
key.converter=org.apache.kafka.connect.json.JsonConverter
value.converter=org.apache.kafka.connect.json.JsonConverter
# JSON schemas enabled to false in cluster level
key.converter.schemas.enable=true
value.converter.schemas.enable=true
# Where to keep the Connect topic offset configurations
offset.storage.file.filename=/tmp/connect.offsets
offset.flush.interval.ms=10000
# Plugin path to put the connector binaries
plugin.path=<PLUGIN_DIRECTORY>You will now configure the BigQuery cluster details in Kafka Connect. To do this, create a file named biqquery.properties and the following configuration:
name=bigquery-sink-connector
connector.class=com.wepay.kafka.connect.bigquery.BigQuerySinkConnector
# The key converter for this connector
key.converter=org.apache.kafka.connect.storage.StringConverter
# The value converter for this connector
value.converter=org.apache.kafka.connect.json.JsonConverter
# Identify, if value contains a schema
# Required value converter is `org.apache.kafka.connect.json.JsonConverter`.
value.converter.schemas.enable=false
topics=booking_events
# The name of the BigQuery project to write to
project= <your_bigquery_project_id>
# The name of the BigQuery dataset to write to (leave the '.*=' at the beginning, enter your
# dataset after it)
datasets= <your_bigqquery_dataset_name>
# The location of a BigQuery service account or user JSON credentials file
# or service account credentials or user credentials in JSON format (non-escaped JSON blob)
defaultDataset=
keyfile=<path and name to redpanda_integration.json>
# 'FILE' if keyfile is a credentials file, 'JSON' if it's a credentials JSON
keySource = JSON
# Whether to automatically sanitize topic names before using them as table names; if not enabled, topic names will be used directly as table names
sanitizeTopics=false
# Automatically create BigQuery tables if they don't already exist
autoCreateTables=false
# Whether or not to automatically update BigQuery schemas
autoUpdateSchemas=false
schemaRetriever=com.wepay.kafka.connect.bigquery.retrieve.IdentitySchemaRetriever
# The maximum number of records to buffer per table before temporarily halting the flow of new records, or -1 for unlimited buffering
bufferSize=100
maxWriteSize=100
tableWriteWait=1000
timestamp=UTC
bigQueryPartitionDecorator=false
Make sure you are specifying the correct BigQuery data set name, the BigQuery project name, and the path to the service-account-credentials JSON file in the placeholders shown.
Start the Kafka Connect process using the following command (note how we are running this command from the Kafka Connect directory):
<kafka_connect_directory>/bin/connect-standalone.sh redpanda.properties bigquery.properties
<kafka_connect_directory>/bin/connect-standalone.sh redpanda.properties bigquery.properties
You will find Kafka outputting logs straightway once this command is executed. Ensure that there are no errors being thrown and the output contains INFO log entries only.
Now you are ready to add some data to the Redpanda cluster and route it to BigQuery.
To test, create a JSON file, name it booking_events.json, and add the following JSON data using the format below.
{"room_id":"123","booking_id":"XB1231","status":"ACTIVE","start_date":"2022-07-15","end_date":"2022-07-21","timestamp":"2022-07-10 00:00:00 UTC"}
{"room_id":"124","booking_id":"XB1241","status":"ACTIVE","start_date":"2022-07-13","end_date":"2022-07-16","timestamp":"2022-07-10 00:00:00 UTC"}
{"room_id":"124","booking_id":"XB1241","status":"CANCELLED","start_date":"2022-07-13","end_date":"2022-07-16","timestamp":"2022-07-10 00:08:00 UTC"}
{"room_id":"125","booking_id":"XB1251","status":"ACTIVE","start_date":"2022-07-12","end_date":"2022-07-16","timestamp":"2022-07-09 00:00:00 UTC"}
{"room_id":"126","booking_id":"XB1261","status":"ACTIVE","start_date":"2022-07-13","end_date":"2022-07-21","timestamp":"2022-07-10 00:00:00 UTC"}
{"room_id":"129","booking_id":"XB1271","status":"ACTIVE","start_date":"2022-07-10","end_date":"2022-07-13","timestamp":"2022-07-08 00:00:00 UTC"}{"room_id":"123","booking_id":"XB1231","status":"ACTIVE","start_date":"2022-07-15","end_date":"2022-07-21","timestamp":"2022-07-10 00:00:00 UTC"}
{"room_id":"124","booking_id":"XB1241","status":"ACTIVE","start_date":"2022-07-13","end_date":"2022-07-16","timestamp":"2022-07-10 00:00:00 UTC"}
{"room_id":"124","booking_id":"XB1241","status":"CANCELLED","start_date":"2022-07-13","end_date":"2022-07-16","timestamp":"2022-07-10 00:08:00 UTC"}
{"room_id":"125","booking_id":"XB1251","status":"ACTIVE","start_date":"2022-07-12","end_date":"2022-07-16","timestamp":"2022-07-09 00:00:00 UTC"}
{"room_id":"126","booking_id":"XB1261","status":"ACTIVE","start_date":"2022-07-13","end_date":"2022-07-21","timestamp":"2022-07-10 00:00:00 UTC"}
{"room_id":"129","booking_id":"XB1271","status":"ACTIVE","start_date":"2022-07-10","end_date":"2022-07-13","timestamp":"2022-07-08 00:00:00 UTC"}
This data contains new booking and cancellation events. Our imaginary booking application will generate an event when a booking is confirmed. The event data has a few fields: the room identifier, booking identified, status ("ACTIVE" for confirmed bookings), start date, end date, and timestamp. It's not possible to have update operations in an event-based system, so the application generates a similar event when a booking gets canceled. The "cancel" event has the same fields, except the status shows "CANCELLED". Our real-time analytics application can find the latest room and booking status by processing this event history. You should also note how the event fields correspond to the BigQuery booking_table schema.
Next, run the command below to send the files' events to Redpanda:
docker exec -it redpanda-node /bin/sh -c 'rpk topic produce booking_events < booking_events.json'
docker exec -it redpanda-node /bin/sh -c 'rpk topic produce booking_events < booking_events.json'
Ensure that you use the complete path of booking_events.json if you are executing this command from another directory.
This should populate the BigQuery table with the events. To verify, run the command below against the booking_table BigQuery table.
SELECT * FROM `<dataset>.booking_table`;
SELECT * FROM `<dataset>.booking_table`;
The output should look like this.
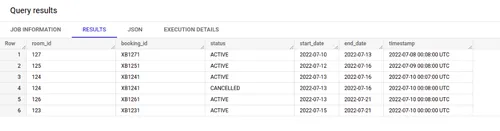
As you can see, the Kafka Connect middleware has helped Redpanda send its data to BigQuery. You tested your application by manually ingesting events to Redpanda. In a production system, there will be another connectivity layer between the online booking application and Redpanda, so whenever an event generates, it will automatically send that data to Redpanda.
As the final step of this tutorial, you will now run an analytical query to find the status of room availability in real time. Run the SQL command below in BigQuery:
SELECT b.room_id,status FROM
(SELECT * FROM
(SELECT *,RANK() OVER (PARTITION BY room_id ORDER BY timestamp DESC) as rmk FROM `test.booking_table` WHERE CURRENT_DATE >= start_date AND CURRENT_DATE <= end_date ) WHERE rmk=1 AND status='ACTIVE')a
RIGHT JOIN
`test.room_master` b
ON a.room_id = b.room_idHere, the SQL command is selecting all booking events that are valid for a specific date range and finding their latest status. It then joins the result set with the room_master table to generate an availability report for each room. The final output is shown below.
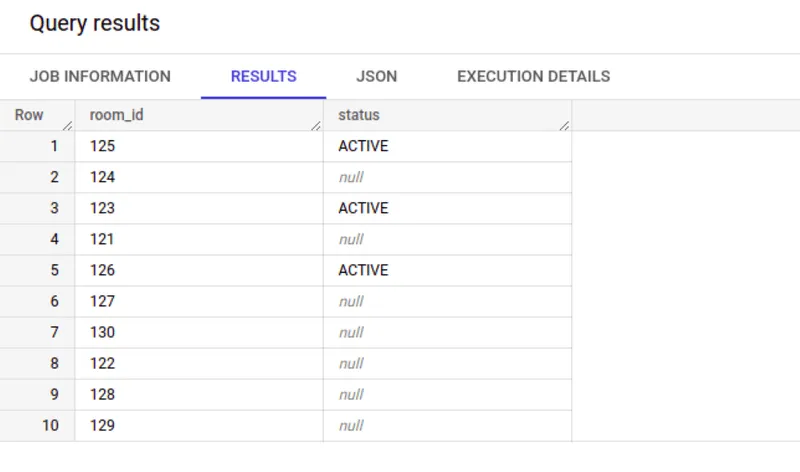
This tutorial should have given you a good idea about how to build a real-time data analytics platform with Redpanda and BigQuery.
Redpanda provides a real-time ingestion platform that can be a drop-in replacement for Kafka. As a data warehouse, BigQuery's powerful query engine and quick execution time make it a perfect choice for storing real-time data streamed to it Redpanda.
Apart from BigQuery, Redpanda supports other data platforms for storage and processing. These include Snowflake, Google Cloud Storage, and more. You can use the basic concepts you learned in this tutorial to configure Redpanda to work with any of these storage and processing solutions. Instead of BigQuery, you can substitute it with another managed service like Redshift or Snowflake. Each data platform will have some common functionalities, unique features, strengths, and weaknesses. What works best for your application will depend on the specific use case.
Take Redpanda for a test drive here. Check out our documentation to understand the nuts and bolts of how the platform works, or read our blogs to see the plethora of ways to integrate with Redpanda. To ask our Solution Architects and Core Engineers questions and interact with other Redpanda users, join the Redpanda Community on Slack.
Subscribe to our VIP (very important panda) mailing list to pounce on the latest blogs, surprise announcements, and community events!
Opt out anytime.

